内存屏障是随着SMP系统的出现而出现的,也就意味着在单核的机器上,不需要任何的内存屏障。
所以要想理解内存屏障的意义,我们需要知道CPU从单核到多核,究竟修改了什么,需要我们引入内存屏障
内存屏障是随着SMP系统的出现而出现的,也就意味着在单核的机器上,不需要任何的内存屏障。
所以要想理解内存屏障的意义,我们需要知道CPU从单核到多核,究竟修改了什么,需要我们引入内存屏障
我决定写一个系列,从头到尾讲一讲我理解的内存屏障的起源。
要想真正理解内存屏障,其实要讲很多的东西。
第一节,先来讲讲CPU的执行与重排序。
分区副本是Kafka中重要的概念。
下面我们来详细谈一谈副本相关的概念。
Kafka的是个复杂的系统,除了基本的Producer,Consumer,Broker外,为了实现完备的功能,Kafka中有许多重要的模块,本文梳理一下这些模块的划分,与他们负责的功能。
通过前面我们知道,对于每个方法,HotSpot都维护两个计数器
并且我们知道对于一个方法,JIT有两种不同的编译方式
很自然得我们就会想到,其实计数器和编译方式之间是有对应关系的。
当对应的方法计数器达到一定的次数,就会触发响应的编译
HotSpot是一款Java虚拟机的实现,除了基本的解释功能以外,该虚拟机还拥有将字节码编译成机器码的并执行的能力,我们知道,直接执行机器码肯定比解释更快。
HotSpot最初会通过解释的方式执行程序,当它发现某个方法运行得特别频繁时,就会将这些热点(Hot Spot)代码进行编译,编译成平台相关的机器码。这个过程也叫做JIT(Just In Time),与之相对的是AOT(Ahead Of Time),比较典型的是C和C++语言。
HotSpot进行JIT编译的编译器有两个,分别叫做C1和C2,或者也可以叫做Client Compiler和Server Compiler。这两种编译器编译策略不同,运用在不同的场景,下面会详细的说明。
Raft实现指北
开始看Lucene源代码,找了个最简单的FSLockFactory开始看。
然而还是看出了不明白的地方
在NativeFSLockFactory的close方法中有这么一段注释
1 | // NOTE: we don't validate, as unlike SimpleFSLockFactory, we can't break others locks |
我从网上找到了当初的Bug的讨论帖
https://issues.apache.org/jira/browse/LUCENE-6507
从里面讨论了NativeFSLock了一些关于这个文件锁的实现的问题
MVStore是h2数据库的底层的存储文件格式
在1.4版本之前底层的文件存储都是org.h2.store.*包中的
然后1.4之后默认改为了org.h2.mvstore.*包中的
官方的介绍说是根据Log Structed FS设计的,顺序写提高性能
MV的意思是multi-version
同类型的项目有个叫mapDB的项目
https://github.com/jankotek/mapdb
还有一个Apache的项目mavibot
http://directory.apache.org/mavibot/downloads.html
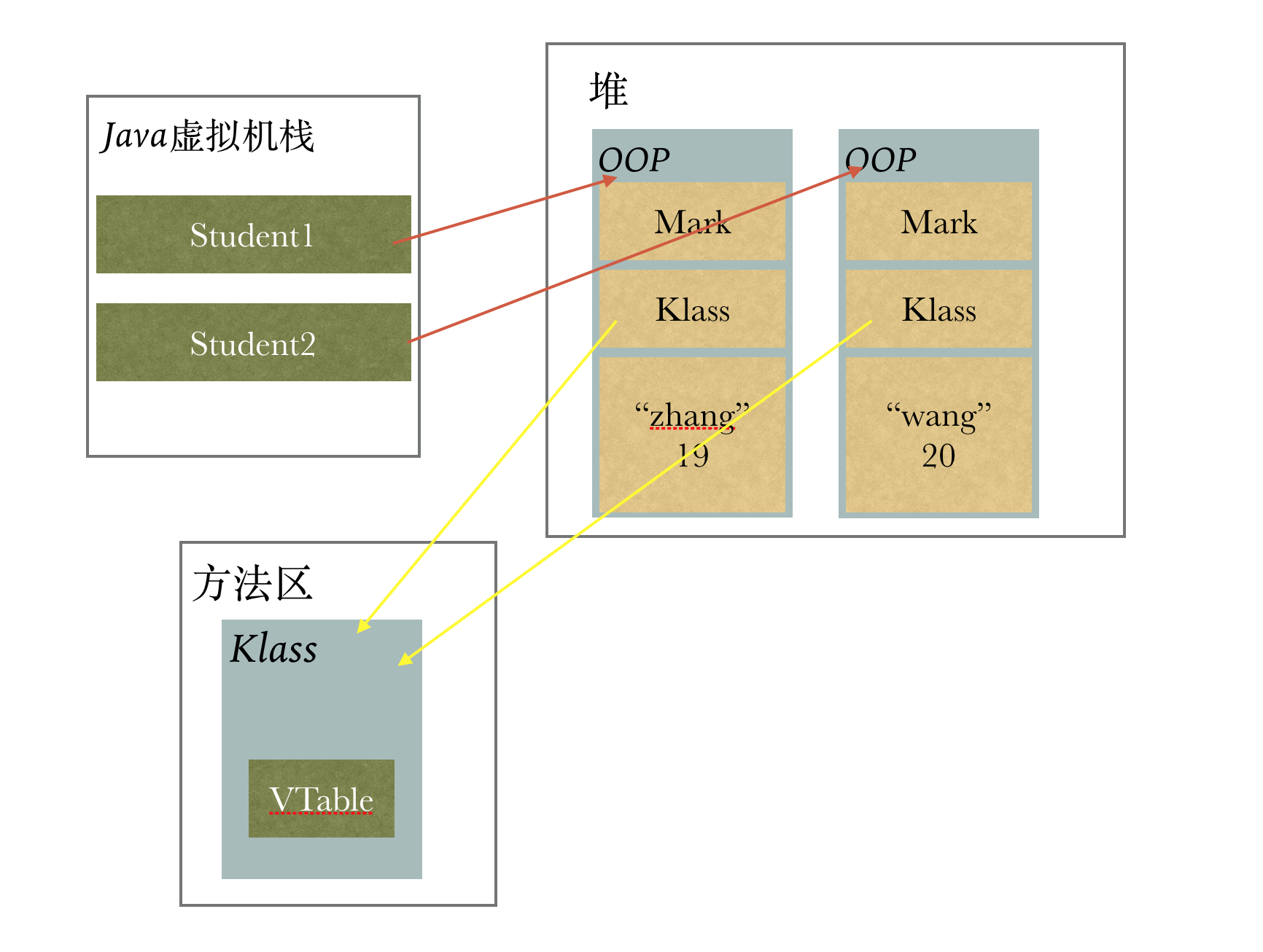
看任何JVM的书,oop-klass总是绕不去的坎
我一直想理解这些,但是就是理解不了,但是也说不出哪里不明白。
这篇文章不会对这个模型做系统的阐述,假设读者已经看过oop-klass模型,但是还是有点一知半解的状态。
为什么要这么设计?
其实很多书也提到,既然HotSpot完全基于C++去编写,要实现多态完全可以进行C++层面的转换就行。
但是C++的多态其实每一个对象都维护了一个VTable,就是虚函数表,函数表可以理解为一个函数指针的数组,这个数组在内存上和一个对象是一起的。
但是很多书中提到,为了避免每个对象都有一个VTable,JVM定义了oop-klass模型,其中oop就是保存数据结构的,而klass则担当了一部分VTable的功能,这样的话,VTable就是每个类只存在一个。
也就是说,对oop而言,它对应的klass是单例的,而Java层面每New一个对象,都会在JVM生成一个oop。
所以在Java中,类和对象的关系更像是这样:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Main {
public static void main(String[] args) {
Student student1 = new Student("zhang", 19);
Student student2 = new Student("wang", 20);
}
}
class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
这里再提一个我对动态绑定的理解。
其实动态绑定这个概念,大家都知道大概是个什么意思,但是再详细的说,就理不清很多细节。
现在我们都知道动态绑定是和虚表有关,在Java字节码中,需要动态绑定的指令是invokevirtual。
https://cs.au.dk/~mis/dOvs/jvmspec/ref–35.html
这个ref中讲的是,动态绑定需要一个寻找函数的过程
invokevirtual retrieves the Java class for objectref, and searches the list of methods defined by that class and then its superclasses, looking for a method called methodname, whose descriptor is descriptor.
这当然我感觉是一种很扯淡的说法,要是这么来,运行时时间都花在匹配函数上去了。
而寻找函数的过程,我理解完全可以放在编译期去完成。
我更认同是这种方式,就是不需要进行运行时的函数匹配,动态绑定的意思是需要在运行时改变代码段的函数指针,类似于下面文章中提到的
https://www.jianshu.com/p/fa50296b301c
编译器内部会发生转换,产生类似下面的代码:
( ( p->vptr )[0] ) (p); //( p->vptr )[0]是函数入口地址
这段代码的生成,对于C++而言是编译时,对于Java则是ClassLoader的时候,并不是运行时。
关于动态绑定,还有一些其他模棱两可的说法
比如这个文章中
https://zhuanlan.zhihu.com/p/24317613
它提到在invokevirtual的调用过程,需要去查父类的方法表
(2) 在Father类型的方法表中查找方法f1,如果找到,则将方法f1在方法表中的索引项11(如上图)记录到AutoCall类的常量池中第15个常量表中(常量池解析 )。这里有一点要注意:如果Father类型方法表中没有方法f1,那么即使Son类型中方法表有,编译的时候也通过不了。因为调用方法f1的类的对象father的声明为Father类型。
这我也是觉得是脱裤子放屁的说法,为啥要去查父类的方法表,要知道父类的方法表,是在另外一个Klass对象里,要是继承链比较长,那么需要很多次指针寻址才能找到。
其实这个和另外一个比较经典的动态绑定的解释很像:
如果子类Son中定义了 method() 的方法,则直接调用子类中的相应方法;如果子类Son中没有定义相应的方法,则到其父类中寻找method()方法。
很多人把这个过程理解为动态绑定,这个的问题也是一样的,它的假设是子类的Klass对象中没有父类的方法指针,所以需要去父类的Klass的VTable中去找。
但是通过一些文章我们可以看出,其实子类的VTable完全的Copy了一份父类的VTable。
https://stackoverflow.com/questions/18082651/how-does-dynamic-binding-happens-in-jvm
https://cloud.tencent.com/developer/article/1180981
所以至此,整个动态绑定的过程我们就已经理解,所谓动态绑定,就是比静态绑定多了一个指针寻址,去Klass中找VTable的过程。
很多书中都提到,oop-klass模型在1.8中改变较大。
原因是1.8中去掉了永久代(Perm),而改为了元空间(MetaSpace)。
我们先看看1.7中的oop-klass的继承链
https://github.com/openjdk-mirror/jdk7u-hotspot/blob/master/src/share/vm/oops/oopsHierarchy.hpp
oop继承链1
2
3
4
5
6
7
8
9
10
11
12
13typedef class oopDesc* oop;
typedef class instanceOopDesc* instanceOop;
typedef class methodOopDesc* methodOop;
typedef class constMethodOopDesc* constMethodOop;
typedef class methodDataOopDesc* methodDataOop;
typedef class arrayOopDesc* arrayOop;
typedef class objArrayOopDesc* objArrayOop;
typedef class typeArrayOopDesc* typeArrayOop;
typedef class constantPoolOopDesc* constantPoolOop;
typedef class constantPoolCacheOopDesc* constantPoolCacheOop;
typedef class klassOopDesc* klassOop;
typedef class markOopDesc* markOop;
typedef class compiledICHolderOopDesc* compiledICHolderOop;
klass继承链1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Klass;
class instanceKlass;
class instanceMirrorKlass;
class instanceRefKlass;
class methodKlass;
class constMethodKlass;
class methodDataKlass;
class klassKlass;
class instanceKlassKlass;
class arrayKlassKlass;
class objArrayKlassKlass;
class typeArrayKlassKlass;
class arrayKlass;
class objArrayKlass;
class typeArrayKlass;
class constantPoolKlass;
class constantPoolCacheKlass;
class compiledICHolderKlass;
可以说是非常多
但是到了1.8中,就变的很少
oop继承链1
2
3
4
5typedef class oopDesc* oop;
typedef class instanceOopDesc* instanceOop;
typedef class arrayOopDesc* arrayOop;
typedef class objArrayOopDesc* objArrayOop;
typedef class typeArrayOopDesc* typeArrayOop;
klass继承链1
2
3
4
5
6
7
8class Klass;
class InstanceKlass;
class InstanceMirrorKlass;
class InstanceClassLoaderKlass;
class InstanceRefKlass;
class ArrayKlass;
class ObjArrayKlass;
class TypeArrayKlass;
而少掉的那部分,其实只是换了个名字,叫做Metadata1
2
3
4
5
6
7
8
9// class MetaspaceObj
class ConstMethod;
class ConstantPoolCache;
class MethodData;
// class Metadata
class Method;
class ConstantPool;
// class CHeapObj
class CompiledICHolder;
可能你已经猜到了,Metadata的这部分,已经全部转移到了元空间。
以下是 JDK 1.7 中的类在 JDK 1.8 中的存在形式:
Klass少掉的部分,还可以理解,但是为啥oop会少了这么多。
这里就牵扯到永久代和元空间的区别了。
首先的问题是,为什么撤销永久代而换成元空间
我找到了当初的JEP
http://openjdk.java.net/jeps/122?spm=a2c4e.11153940.blogcont20279.13.13fd33dbw7ltIv
永久代的调优非常难,永久代的大小很难确定,其中涉及到太多因素,如类的总数、常量池大小和方法数量等,而且永久代的数据可能会随着每一次Full GC而发生移动。
这里就要提到元空间的特点
Symbols were moved to the native heap
Interned strings were moved to the Java Heap
Class statics were moved to the Java Heap
而如果你去看JDK1.7的oopDesc的定义,你会发现一个奇怪的事1
2
3
4
5
6
7
8
9class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
wideKlassOop _klass;
narrowOop _compressed_klass;
} _metadata;
}
这里的Klass,为什么是Oop对象?
这里引用R大的解释
https://rednaxelafx.iteye.com/blog/858009
因为HotSpot 1.7之前,包括Class在内的元数据对象都需要被GC管理,因此这四列的对象其实都是oopDesc类型,只不过第一列是描述实例的instanceOopDes, 第二三四列为klassOopDesc;这个klassOopDesc可以看作是klass的一个wrapper,仅仅为了被gc更容易滴管理和表示,它的内部有一个klass成员来表达klass的信息。
所以第二列的 klassOopDesc 内部的klass 乃Integer类的klass,第三列的klass为 klassOopDesc这个对象的klass——instanceKlassKlass,那第三列这个类的klass是什么呢?由于描述instanceKlassKlass,methodKlassKlass,xxxxKlassKlass等一大票KlassKlass需要的元数据实际上是相同的,他们就是第四列的KlassKlass,第四列的KlassKlass的klass可以用它自己来描述,于是就圆满了。
简单说就是为了偷懒,用Oop包裹一层,让GC一同管理了。
到了元方法区,已经不属于堆了,自然不需要这个了,自然可以去掉。
所以到了1.8,就变成了正常的状态1
2
3
4
5
6
7class oopDesc {
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
}
还有一些细节,我还是比较困惑的。
比如这个MarkOop的定义1
2class markOopDesc: public oopDesc {
}
它是继承于oopDesc的
但是在oopDesc的定义中1
2
3
4
5
6
7class oopDesc {
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
}
又用到了markOop
好吧,这个是一件比较奇怪的是。
上面R大提到,继承与oopDesc的都是被GC管理的,
但是这里有个奇怪的点
MarkOop存在于OopDesc中,讲道理应该是个对象才是,但是它的作用却只是作为对象头。
在Java层面没有与之对应的东西。
更没有道理要被GC管理着啊
我翻阅文档的注释
发现了这么一句话1
2
3
4//
// Note that the mark is not a real oop but just a word.
// It is placed in the oop hierarchy for historical reasons.
//
既然官方解释是历史原因,那就不追究这个问题了。
这个算是一个小发现
我们查看oop的体系,发现Method也有对应的oop
在method的oop中,有个变量叫MethodCounters1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class MethodCounters : public Metadata {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
Method* _method; // Back link to Method
int _interpreter_invocation_count; // Count of times invoked (reused as prev_event_count in tiered)
u2 _interpreter_throwout_count; // Count of times method was exited via exception while interpreting
u2 _number_of_breakpoints; // fullspeed debugging support
InvocationCounter _invocation_counter; // Incremented before each activation of the method - used to trigger frequency-based optimizations
InvocationCounter _backedge_counter; // Incremented before each backedge taken - used to trigger frequencey-based optimizations
这个类维护了几个关于方法调用次数的计数器,和JIT的热点探测有关
具体的细节可以查看
https://www.jianshu.com/p/1ea9b3d1abb9
http://mail.openjdk.java.net/pipermail/hotspot-compiler-dev/2011-June/005750.html
这个工具,可以用来查看运行时的oop和klass数据
简单的使用,网上可以随便百度到,这里介绍下怎么查看虚表
https://cloud.tencent.com/developer/article/1180981