前言
内联是编程语言编译器中常规的优化操作,几乎所有的语言在编译时或者在执行时都会有内联操作。
内联的本质是把几个方法合并成一个方法
从一方面讲,内联减少了函数调用的栈帧创建和销毁的时间消耗
从另一方面讲,内联为很多其他的优化方法提供了更多的可能,比如逃逸分析,无用代码消除,虚函数优化等,这也是内联被叫做优化之母(The Mother Of All Optimization)的原因。
HotSpot-JIT
简介
对于HotSpot的JIT而言,内联是一个渐进的过程,这个渐进表现在两方面
- C1和C2两个JIT编译器的内联策略不同,C2可能更加激进一些
- 内联策略和很多因素有关
- 内联发起函数大小,被内联函数大小
- 被内联函数的调用次数
- 内联深度
- 中间表示的NodeCount
- 函数方法签名
初步体验
先看一段代码,初步的了解下HotSpot的内联,以下代码的执行参数-XX:CompileCommand=exclude,Inline.main
这个参数的意义是禁止main函数内联inline方法
1 | class Inline { |
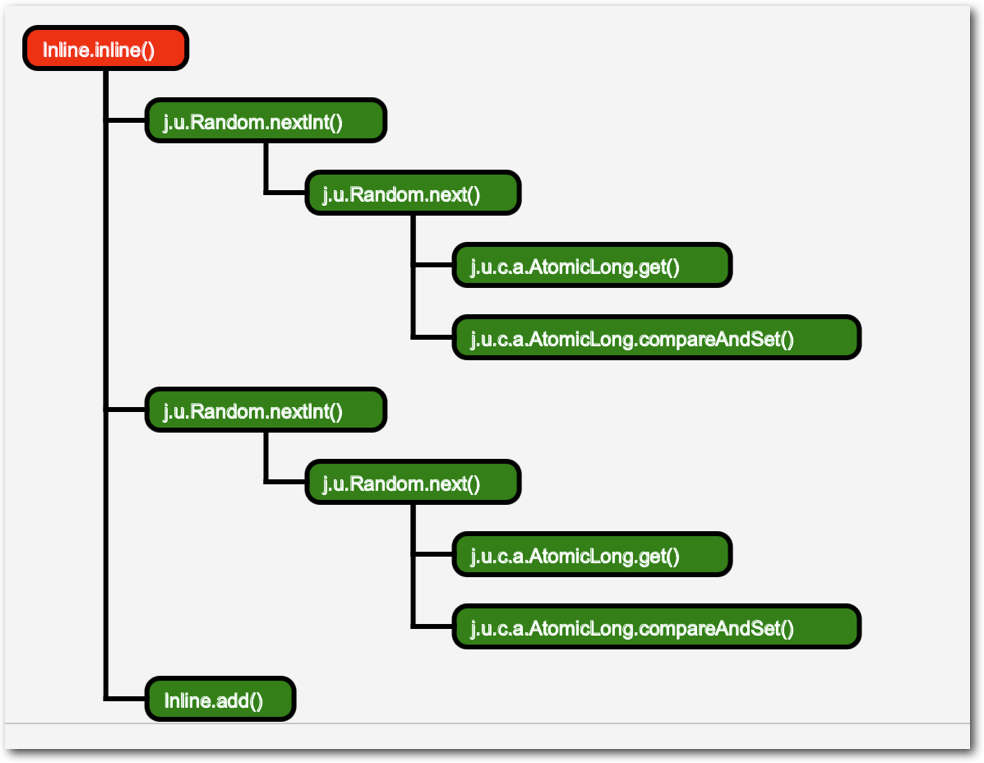
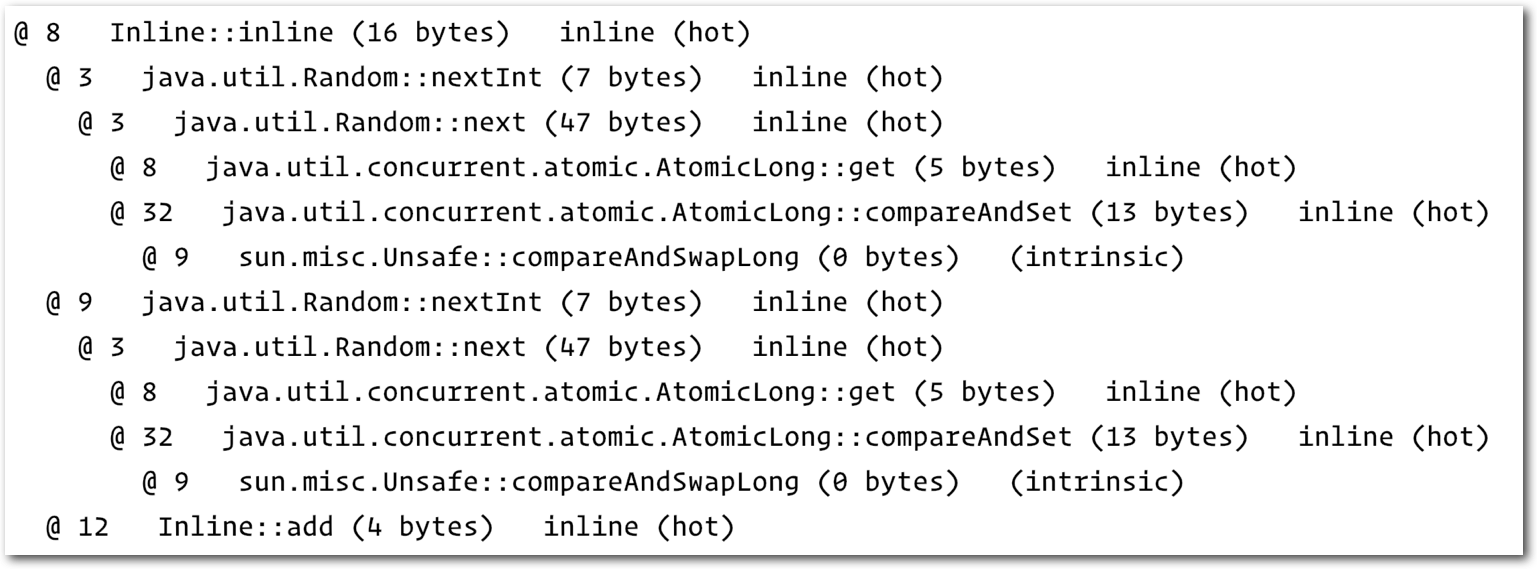
上图中展示了经过C2编译后,整个inline函数的内联状态
可以看到不仅仅内联了random.nextInt()方法,还将nextInt方法中的next方法等等好几个再下层的方法也内联了进来
HotSpot参数
java -XX:+PrintFlagsFinal | grep "Inlin"
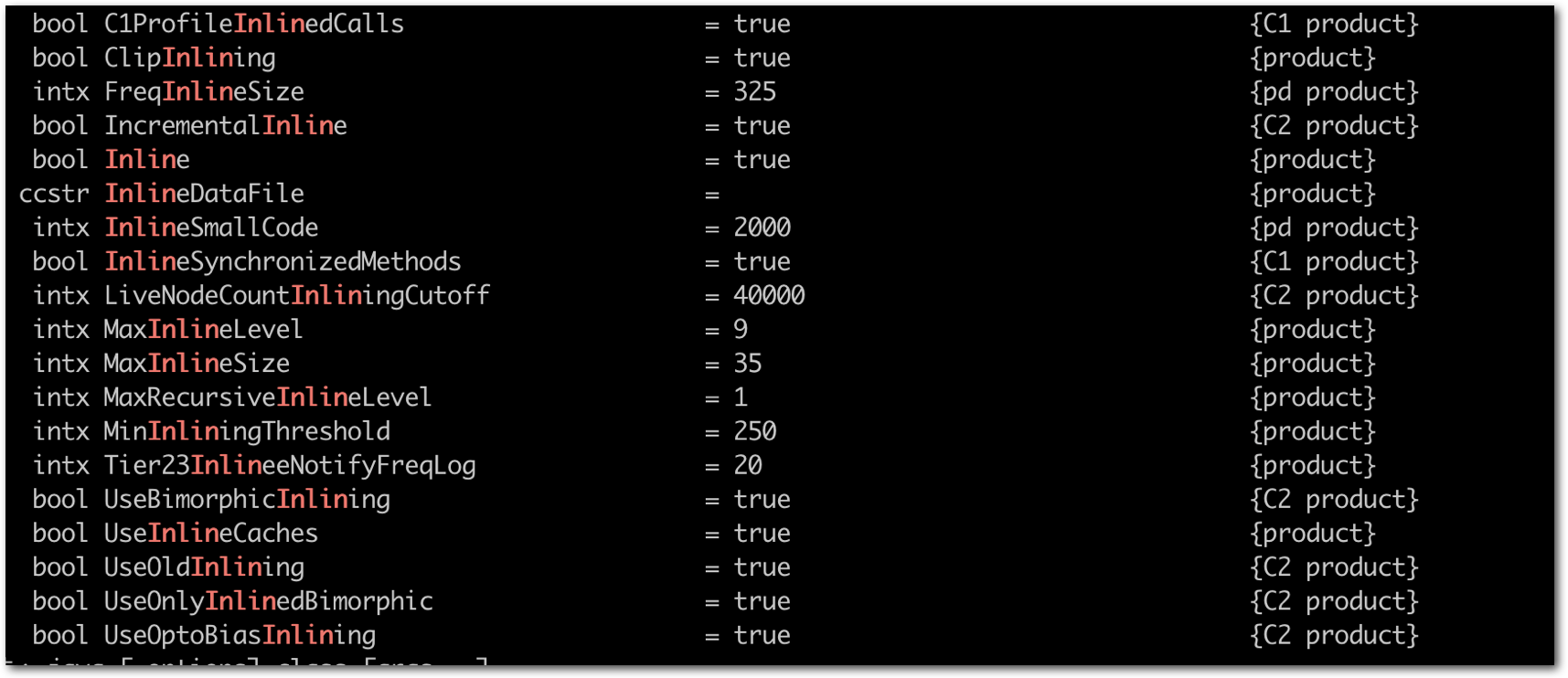
可以看到HotSpot可以控制内联的参数很多很多,从侧面也表示HotSpot的内联策略是非常复杂的。
笔者也无法精通所有的内联策略,所以只挑选出比较重要的几个参数来讲解。
主要讲解如下几个参数
| 参数 | 默认值 |
|---|---|
| MaxTrivialSize | 6 |
| MaxInlineSize | 35 |
| FreqInlineSize | 350 |
| MinInliningThreshold | 250 |
| InlineSmallCode | 1000(No-Tier) 2000(Tier) |
| MaxInlineLevel | 9 |
| MaxRecursiveInlineLevel | 1 |
内联策略
MaxTrivialSize
对于Trivial方法,在HotSpot中有着严格的定义
1 | bool SimpleThresholdPolicy::is_trivial(Method* method) { |
从上面的代码可以看出,常见的Getter方法,肯定是trivial方法
而函数中有循环,或者函数大小超过15bytes,则不是trivial方法
对于trivial方法,如果它的函数字节码小于MaxTrivialSize,那么即使它在调用方至今一次也没有被执行过,HotSpot也会将它内联进来。
这是对于C1而言,对于C2而言,则不会进行内联,而是会生成UnCommon Trap
MaxInlineSize
我们了解了MaxTrivialSize,那么对于MaxInlineSize则很容易理解。
对于调用方至少执行过一次的方法,如果它的大小小于MaxInlineSize,那么就会考虑将它内联进去
FreqInlineSize和MinInliningThreshold
了解了以上两个参数后,你可能会问,如果被调用的函数既不符合Trivial方法,大小也大于MaxInlineSize,但是这个方法非常的Hot,就没有机会被内联了吗
并不是,FreqInlineSize和MinInliningThreshold这两个参数就是为这种方法设置的。
当一个方法既不是Trivial方法,而且大于MaxInlineSize,如果他的调用次数大于MinInliningThreshold,也就是250次,且它的大小小于FreqInlineSize,那么它也会被内联
InlineSmallCode
我们知道,调用方进行方法内联的时候,函数本身的大小会越来越大。
这时候你又会问了,那调用方内联可以无限内联吗,内联后的大小肯定会有限制的吧。
对的!InlineSmallCode就是限制的大小
如果是非分层编译的环境,阈值是1000bytes
如果是分层编译的环境,那么阈值是2000bytes
MaxInlineLevel
对于一个函数进行其他函数的内联,除了内联后的大小限制,内联的深度也是有限制的。
在HotSpot中,默认的内联最大深度是MaxInlineLevel控制,也就是9层。
为什么要限制内联的最大深度呢?
在stackoverflow上有个我认为比较中肯的答案
Why does the JVM have a maximum inline depth?
Not exactly, but I guess the basic reason is to keep things simple. Unlimited inlining depth would increase complexity, the compilation time and memory usage might be less predictable (that is OK for AOT compilers, but not for JIT). Also mind that compiled code should keep track of the whole inlining tree at run-time (to be able to unwind and deoptimize). Though I think the default value of 9 is outdated. It has not been changed for ages, but nowadays, with much more resources available, with streams and lamdas in mind, there is definitely a place for improvement
总结一下答案:
- 为了保持内联的简单性。无限制的内联会增加复杂度。
- 内联后的编译代码,需要记录整个内联树。
- 编译时间和内存消耗会变得不可预测。
当然,作者也认为默认值9已经很久没有改动了,随着计算机资源变得不再那么昂贵,完全可以适当调大这个值。
MaxRecursiveInlineLevel
对于递归的方法,它内联自己最多只能内联MaxRecursiveInlineLevel层,也就是1次。
查看内联结果
如果想要知道我们的代码在编译时,内联了哪些方法,那么可以加上参数
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
对于上面的inline.java的结果输出如下