前言
自己陆陆续续花了一些时间完成了一个Raft的库,目前基本的流程都完成了,下面要继续做的话,就是要进行一些优化的逻辑了。
Rub-Raft
取名叫Rub,就是卢布的意思,纪念雯姐今年去世的花枝鼠[2016-2019]。
卢布是我见过最乖的鼠,很聪明,她喜欢睡在吊床上,不会像其他的鼠去啃吊床的线。
参考资料
一个很好的博文
https://lichuang.github.io/post/20180921-raft/
《CONSENSUS: BRIDGING THEORY AND PRACTICE》论文
https://ramcloud.stanford.edu/~ongaro/thesis.pdf
整体流程
集群的整体状态一般分为三种
- 选举
- 日志添加
- 正常添加
- 非正常添加
- 新节点获取日志
- 新增节点
我可能不太会对所有流程做详细的阐述,只是一些简单的问答和心得。
整个RPC的方法其实只要4个就可以完成Raft,前两个和选举有关,后两个和日志有关
1 | VoteResponse requestPreVote(VoteRequest voteRequest); |
配置
需要节点的自动注册和发现吗
一开始我还是RPC的实现思路,以为需要一个自动的节点注册和发现机制
当然其实并不需要,集群启动的时候,只要我们把初始的节点信息写死在启动Config文件中就好
那么可不可以有呢,我理解是不可以的,因为选举的时候,节点需要知道当前节点的个数,来判断自己得到的选票是不是已经有集群节点的一半了。
如果你还搞个节点自动注册,那么到底集群有几个节点呢?
节点的RPC连接
讲道理其实RPC连接并不是什么大问题,但是我们不能先入为主的当做DUBBO这种RPC框架去实现我们的RPC框架。
这个问题的根源是:正常的RPC模型并不是互相问答的模式
都是C/S模型
一个节点一般会开一个Server,让其他的节点来连接,并提出请求,这个Server并不会主动向其他的Node发送消息。
这个时候会想到,我们每个节点都当做是一个Server,然后对每个其他的Node,开对应的Client连接。我就是这么实现的,这样的情况其实对于两个节点而言,互相的连接通过了两个不同的Channel来实现。
后来发现其实这样还有问题。
问题是在无法重新连接的情况
假设这样的情形,3Node互相连接,过程中Node1断开,其他两个Node互相连接,过一阵子,Node1又启动,开启自己的RpcServer,并顺利连接到其他两个Node的RpcServer
而其他两个Node并不会主动的去连接Node1的RpcServer
这个就需要一种机制,当其他的节点连接上自己的RpcServer的时候,获得感知,然后自己也去连接对方的RpcServer
那么这个感知机制,放在哪里去做呢。
放在Rpc层面吗?我感觉侵入性很大,一方面作为一个Rpc并不需要这种机制,需要的话,也是一个抽象度很高的东西,类似于连接上的回调之类。
我这里另外开了一个RPC方法,叫requestConnect,当每个节点RPCClient或者RPCServer启动的时候,都会向其他的节点发送requestConnect请求,其他节点接收到这个请求,会检查自己与发送请求的节点的链路是否已经失效,如果失效,则请求重新连接。
这样完成的很好,但是就是RPC请求的次数会有点多。
RPC请求的异步与同步
这个问题不是很复杂,但是我们如果自己实现RPC的话,要注意的一点就是不能不支持异步的方式。
我的RPC的实现中,支持3种请求方式
- SYNC 同步请求
- ASYNC 异步请求
- ONE_WAY 不需要返回的请求
不过异步请求说白了就是RPC框架帮你封装好了SYNC的Future的方式
上面提到了Raft的需要的5种方法,那些需要异步呢
- requestConnect => ONE_WAY
- requestPreVote => ASYCN
- requestVote => ASYNC
- requestAppendLog => SYNC
- requestInstallSnapShot => SYNC
选举
节点启动顺序
节点启动的顺序要注意什么吗?
还是不需要,选举要得到一般的选票才能成为Leader,即使有一个节点最后启动,此时集群中已经选举出一个Leader了,最后启动的那个节点收到AppendLog的消息,就会自动变成Follower。
节点初始化
节点初始化要做的事不多,就是设置自己的状态为Follower
然后启动一个选举超时的定时器
选举超时时间
节点刚启动的状态是Follower,并且启动一个超时定时器,当时间到了的时候开始进行选举
那么这个超时的时间是多少呢?论文中给出的范围是150 - 300ms[章节3.4]
超时期间收到Request
我们知道当选举超时之后,节点把自己的状态设为pre_candidate,并且发送消息给其他节点进行选举。
如果超时期间收到消息呢
论文中写,A server remains in follower state as long as it receives valid RPCs from a leader or candidate.
很明晰,超时期间收到其他节点的Request,那么就不会进入选举流程,依然是一个Follower。
超时方法什么时候调用
在接收到PreVote,Vote,AppendLog的RPC请求接收到之后都要开始调用
锁
要加锁吗,当然是要的
上一个我们提到
节点超时,开始发起选举RPC之前,启动超时,如果到超时结束,还没有选举出一个Leader,那么就把自己的term加一再次发起选举
这个过程中有两个事件需要一些条件的同步
- 超时线程:没有收到Leader的信息和其他节点的选举信息,就执行,也就是心跳有更新
- 接收vote线程:收到Leader和其他节点的信息,还在超时未完成状态,就更新心跳信息
如果分为两个方法的话,最简单的就是给整个方法都加锁
但是这样锁的粒度太大了,能不能把条件抽象出来呢
我想的是对Node的状态进行cas的修改
超时线程,首先判断心跳有没有更新,如果有更新就不进行选举,如果没有更新,就加锁的对NodeStatus进行CAS更新,从Follower更新到Pre_Candidate
接收Vote线程,首先对NodeStatus进行CAS的更新,从Follower更新到Follower,然后更新心跳时间
我们分析两个线程的流程
超时线程
- 1.判断心跳有没有更新
- 2.NodeStatus从Follower更新到Pre_Candidate
接收Vote线程
- 3.首先对NodeStatus进行CAS的更新,从Follower更新到Follower
- 4.更新心跳时间
如果不加锁,流程从3 - 1 - 2 - 4就出问题了
这个思路很麻烦
我们再换个思路
超时线程进行vote的时候,需要对term进行+1
接收Vote线程,如果成功接收其他节点的信息维持Follower的话,那么对面的term肯定比自己大的,那么也就是需要对Term进行加1
所以我们对Term进行cas操作,谁成功了谁进行操作
PreVote
其实论文中并没有很直观的提到PreVote的阶段
需要PreVote的原因也不复杂,可以百度一下。
VoteFor可以进行修改吗
Vote阶段
假设这样一种场景:
我们有节点1 2 3
2最后启动
1,3同时超时,且3的请求先到2
3,term = 1,2投票给他,1拒绝,于是3变成leader
1,term=1,2拒绝了他,3也拒绝了他
这个时候Term2其实已经有Leader了,是3,那么1也要变成Follower
这个时候1收到HeartBeat就要把自己变成Follower
那么这里的1的Term=1的votedfor其实已经设置为自己了
所以VotedFor还是可以进行修改的
Leader发现更高任期的Server
这种情况也是会发现的,就是Leader进行了STW的GC,然后其他的节点进行了超时选举,选出了Leader。
这种时候,原来的Leader的GC结束,进行进行AppendLogRequest,就会发现更高任期的Server
这种情况直接自己变成Follower就行
日志比较的原则
https://zhuanlan.zhihu.com/p/32052223
日志比较的原则是,如果本地的最后一条log entry的term更大,则term大的更新,如果term一样大,则Log Index更大的更新
选举模型
5个节点中,如果有两个节点同意,那么就可以成为Leader
但是反过来说,如果3个节点拒绝了,那么就不能成为Leader
第一个条件我们可以使用Latch
第二个条件我们还是可以使用Latch
那么怎么组合这两个Latch呢
答案就是
所以总而言之,不能用Latch
只能加锁唤醒了
我这里自己实现了一个类专门用来进行选举的计数。
日志复制
Peer状态管理
这个也是我实现的时候遇到的比较棘手的问题
一开始也没有什么好的解决思路
因为每个节点的任务执行的状态在同一个时刻肯定是不一致的,有可能这个快一点,那个慢一点
也有可能就是有的是正常发送心跳,有的则是刚刚重启需要进行日志的同步
但是有一个很明确的点就是每个Follower节点都是不同的状态管理
同时我们再关注下Leader向Follower节点发送心跳或者AppendLogRequest的频率,会发现每次只能有一个请求过去,当这个请求没有返回或者未超时失败时,是不能够发送下一个Rpc的。
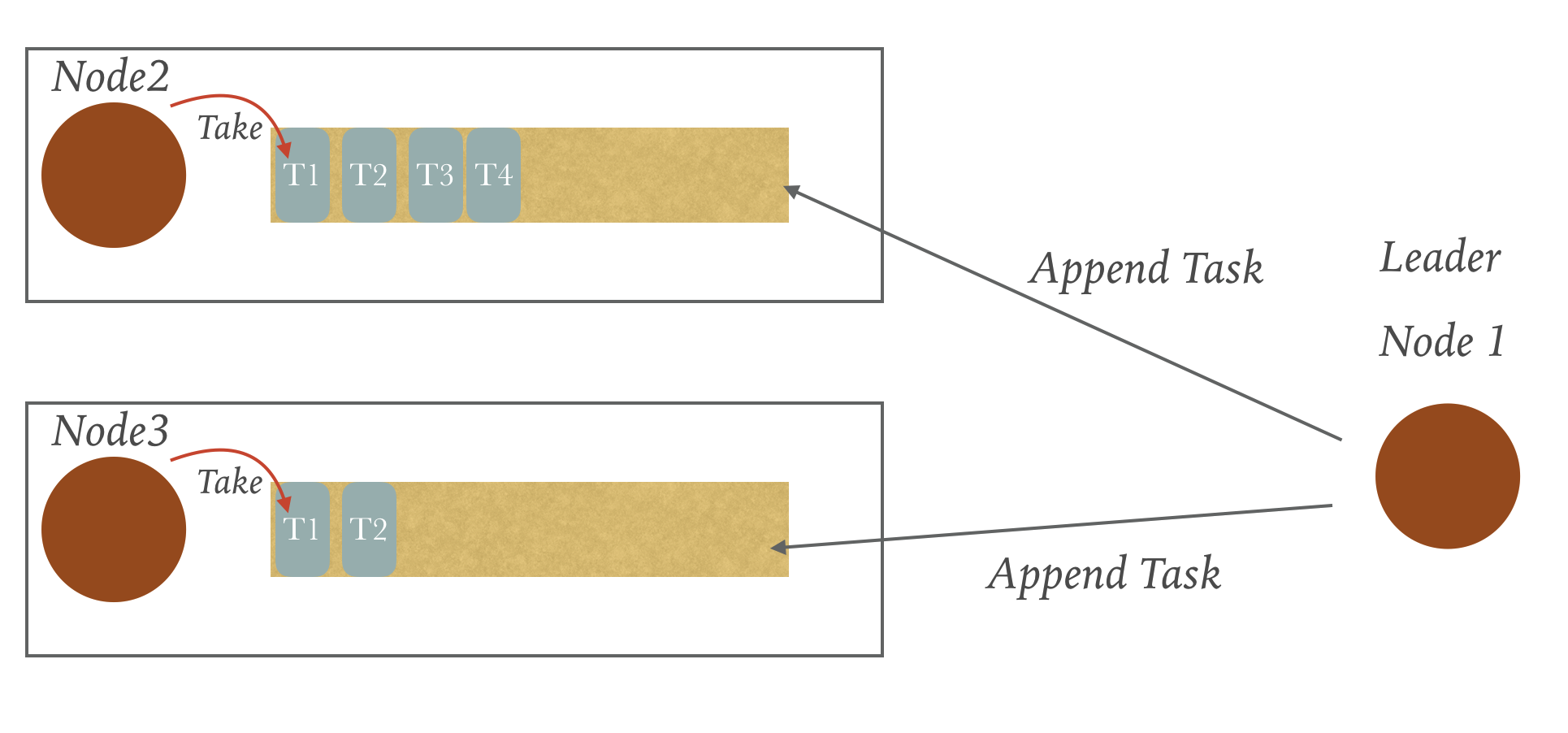
综合以上两点,我的设计就是为每个PeerNode分配一个任务队列,每个PeerNode都有一个单独的线程去拿队列的第一个任务,然后同步的执行。
当Leader需要进行发送心跳或者AppendLogRequest或者其他的请求时,直接Append一个Task到PeerNode的任务队列就行。
除了AppendLog还要做什么
这个也是一个误区,因为心跳的RpcRequest就是一个空的AppendLogRequest
我开始的实现中,会判断如果需要Append的Log为空,那么就重置一下选举定时器,然后就直接返回了。
这个其实是错误的,我们对每一个AppendLogRequest都要进行日志的比对,把还没有Commit的日志,如果需要,给删了或者覆盖了。
这么说可能不太明白,假设这样一种场景。
一共三个节点,Node1是Leader,三个节点的日志都是1,2,3,一致的。
然后发生了网络分区,Leader被隔绝了,但是Node1并不知道,同时客户端的请求也过来了,虽然日志无法commit,但是还是Append到了Node1中。
如果网络分区结束,Node2变成了Leader,Node2给Node1发送心跳的时候,这时候就需要根据Log的index和Leader的commitIndex,把4和5删掉。
这个BUG我也是找了很久,当初图省事简单也没考虑到这些。
ReplicatedLogResponse的变更
如果是节点Down了之后重启,Leader发现nextIndex对不上的时候,会一步一步的退一个NextIndex把日志发送过去,但是每次都发送后续的全量的Log,开销会很大,所以这里可能可以加一个优化,就是在ReplicatedLogResponse加上自己的lastCommitIndex,让Leader可以一次定位到matchIndex。
成员变更
论文中讲了,如果3台节点中突然加了两台,可能出现两个Leader,一个通过新配置,一个通过旧配置。
所以一般的实现是一次只增加一个节点,这个增加的行为其实是人为控制的。
这个地方的实现也有一些坑点存在。
比如论文中写新配置是通过日志的形式进行Append进去的,那么这个日志的格式是啥样的呢。
一开始我们定义成了增加节点和删除节点的形式,比如1
2
3
4
5class ClusterChangeLog {
Type type; //表示是增加节点还是删除节点
NodeId nodeId; //需要增加的节点Id或者删除的节点Id
EndPoint endPoint; //需要增加的节点Id或者删除的节点Id的IP和端口地址
}
像这种形式的日志进行Append,但是其实是不行的。
我们需要的Log要包含新的集群的所有的节点信息,是否是删除还是增加,删除还是增加的节点信息由节点的日志模块自己去解析。
所以正确的形式应该是这样1
2
3class ClusterChangeLog {
List<NodeConfig> nodeConfigs;
}
为什么说第一种的形式是行不通的或者说实现起来有BUG呢?
主要的问题还是在要新增的那个节点上,
- 首先新增的节点会有个像Leader获取日志的情况,在获取日志的时候,新增的节点还不属于集群,也就是说,在日志中并没有体现,除了Leader节点,其他的follower节点并不知道该节点的存在。也就是说,我们在开启新增的节点的时候,是不能够将现有的集群的配置写给他启动的,不然就自动连接到其他的节点上去了。
- 第二种情况就是,如果我们把当前的集群配置写给新增的那个节点,然后启动它,再把新的集群配置写给Leader,在Leader还没发送时,Leader挂了,那么这个新增的节点咋办呢,能办也能办,但是搞起来会很复杂
所以我们需要在启动新的节点时,不给它写当前的集群的配置,然后把新增的集群信息写给Leader,Leader也不会立即写日志,而是会进行日志的同步,
- 如果日志同步的过程中,Leader挂了,那么没关系,因为新的配置还没写日志,挂了就人为的再写给新的Leader就行,不会影响当前的集群
- 日志同步结束之后,把日志进行Append,然后发送给所有的节点,包括新增的节点,那么即使这中间Leader挂了,因为集群更改日志是只要Append就生效的,按照日志最新的才能当前Leader的原则,新的Leader出现之后,会把更改日志再同步到其他的节点,包括新增的节点。
测试
好的,代码写完了,那么你怎么测试你的代码的正确性呢。
这个是我当初头疼的一点,没什么办法进行测试,我到底有没有写对。
首先这是个分布式的应用,我们除了模拟分布式的环境,还要模拟网络的各种情况,这些肯定不是我们真实模拟硬件和网络情况的,所以肯定要侵入代码的。
但是这种需要侵入代码的方法,没有一个方法论在里面的话很容易写乱。
这里我参考了MIT6.824的课程代码
MIT-6.824/blob/master/src/raft/test_tes
这里模拟了诸多情况
- Leader断网
- Leader断网又恢复
- 集群整体掉线恢复
- 网络分区
等诸多情况
