前言
HotSpot是一款Java虚拟机的实现,除了基本的解释功能以外,该虚拟机还拥有将字节码编译成机器码的并执行的能力,我们知道,直接执行机器码肯定比解释更快。
HotSpot最初会通过解释的方式执行程序,当它发现某个方法运行得特别频繁时,就会将这些热点(Hot Spot)代码进行编译,编译成平台相关的机器码。这个过程也叫做JIT(Just In Time),与之相对的是AOT(Ahead Of Time),比较典型的是C和C++语言。
HotSpot进行JIT编译的编译器有两个,分别叫做C1和C2,或者也可以叫做Client Compiler和Server Compiler。这两种编译器编译策略不同,运用在不同的场景,下面会详细的说明。
JIT编译
1 | public class Add { |
上面这段代码,我们有一个add方法,如果我们对改方法进行时间统计,我们会得到下面的曲线。
X轴是次数,Y轴是时间的log2。
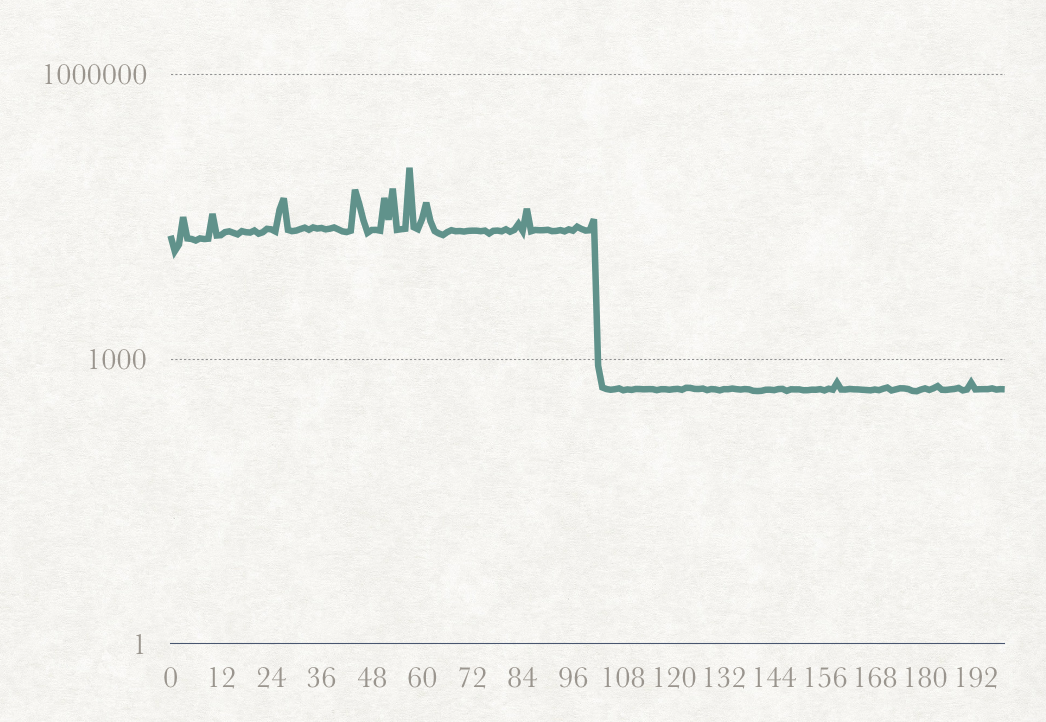
从这个曲线我们可以看出,在第大概100次的时间,时间消耗会下滑,也就是性能提升了一个档次。
由此我们可以猜到,前100次的add方法是由解释执行的,在100次后,执行的是由JIT编译器编译过的机器码。所以性能会有较大的提升。
Profile
在详细讲述C1和C2之前,我们还有一个内容需要科普,就是方法的Profile信息。
除了最基本的用于判定某个方法是否是HotSpot的方法调用次数(Invocation Counter)信息外,对于某个方法,还有一些信息是会在运行时进行收集的。
比如我们看下面这段代码
1 | public static void record(List<String> list) { |
record函数的功能很简单,入参是一个List,如果List不为空,那么就把大骚包卢布这个字符串传递进去。不然的话就打出一个warn级别的日志我不是大骚包。
那么在调用这个方法的时候,HotSpot还会记录哪些信息呢
- List的真实类。因为List在Java中是一个接口,具体的传入可能是ArrayList或者LinkedList或者其他的。HotSpot需要记录具体的类为了以后的优化。
- Log的真实类,理由和List一样。
- 进入if的次数,以及进入else的次数,更通俗的说是条件选择的实际情况。
有人可能会问统计这些Profile有什么用。
举个最简单的例子,如果我们需要对list.add做内联,那么我们到底内联那个实现呢,这个就需要我们收集list的真实实现是什么。
C1和C2
| C1 | C2 | |
|---|---|---|
| 编译时间 | 快 | 慢(x4) |
| 执行时间 | 慢 | 快(30%) |
| 输出代码 | 多 | 少 |
上表是C1和C2在编译时间,执行时间,输出代码的区别
- 编译时间:同样一段代码,C1需要时间比C2短,也就是需求的CPU资源较少
- 执行时间:C1编译时间短,通常意味着优化不如C2,所以C2编译出的机器码执行效率较高
- 输出代码:C1编译时间短,最终也就导致输出的机器码占用的内存要比C2多的
总结:同一段代码,C1消耗的CPU资源较少,但是输出的代码质量不如C2。但是毋庸置疑的事,无论是C1还是C2输出的机器码,执行效率肯定都比解释快的。
C1又称Client Compiler,C2又称Server Compiler,不是没有历史渊源的。
或许我们都听过java在启动的时候可以执行是client模式还是server模式。
当我们使用client模式时,一般运行的是应用程序,比如java swing,awt之类的图形软件,对于这些桌面软件,作为使用者而言,并不希望哪个桌面应用占用大量的CPU,所以非常适合C1的场景
- 编译速度快
- 占用CPU资源少
而对于Server模式而言,一般是公司的服务器上跑的稳定的服务应用,服务器的资源一般较为丰富,同时一个应用并不会像桌面应用一样频繁的开关,一般都要跑几周或者几个月甚至几年。这种应用,当然速度越快越好。所以非常适合C2的场景
- 编译消耗更多的CPU资源
- 代码质量更高,也就是性能更好
C1和C2和Profile
前面提到过的Profile信息,你可能会疑惑这个和C1和C2有什么联系。
其实我们需要先明白一个概念,就是收集那些Profile不仅仅会占用程序以外的更多的内容,而且会占用很多的CPU消耗。同样一段代码,插入了收集Profile逻辑和没有插入收集Profile逻辑,执行性能是不同的。
结合我们提到的C1和C2的使用场景的区别,可以得出这样的结论,这个收集Profile的消耗,对于桌面应用而言,是非常不合适的。
但是C2则需要这些Profile去做更好的性能优化。
所以对于Client模式的应用而言,解释器不会去收集程序的Profile信息,而Server模式在解释器阶段,则会进行Profile的收集,这也就导致了Client模式的起步性能是比Server模式的起步性能要好很多。
启动模式
在JDK1.6之前,指定是client还是server模式,我们在java程序启动时直接加参数就行了
java -client Hello
但是
注意我这个但是
其实自从JDK6的某个版本开始,你已经控制不了这个参数了
https://docs.oracle.com/javase/7/docs/technotes/guides/vm/server-class.html
从这个网站可以看到,默认如果你是64位的机器并且至少有2G内存和2核心的CPU,默认都是Server模式了。
-client这个参数会被忽略
但是也并不是没有办法指定client模式
不仅仅要在启动参数中加上-client
还需要去修改文件jre/lib/jvm.cfg
比如我的文件中默认是这个状态
1 | -server KNOWN |
注意到我的-client后面跟的是IGNORE,所以我指定-client模式其实是不生效的
我需要改成-client KNOWN才行。
当然Oracle选择忽略-client模式也不是没有道理的
- Java的桌面应用已经很少了,Swing基本已经死了
- 现在大家的笔记本的CPU和内容资源都很充足
所以全部使用server模式也没问题。
后续
当然C1和C2的故事并没有这么简单
同时JIT编译的策略也不是非C1就是C2,在JDK7中引入了分层编译,结合了C1和C2的优点。
这些会在后面的文章讲述。
