我决定写一个系列,从头到尾讲一讲我理解的内存屏障的起源。
要想真正理解内存屏障,其实要讲很多的东西。
第一节,先来讲讲CPU的执行与重排序。
CPU的执行
流水线
当然我对CPU几乎没系统的学过,都是从网上看看博客学来的。
CPU执行一条指令需要4个步骤(当然网上可能有其他说法,比如三个步骤或者五个步骤,不过没关系,不影响下面我们的结论):
- 取址:从内存中取出指令
- 译码:翻译指令,生成响应的控制信号
- 执行:使用CPU的逻辑处理单元计算
- 回写:把结果写回到寄存器或者内存
假设我们有三条指令:1
2
3mov $0x0, %esi
mov $0x0, %edi
and $0xf, %ebx
我们把这四个步骤都合并成一个组合逻辑去运行的话
架构图如下:
那么我们需要的时间其实就是串行的,如下图: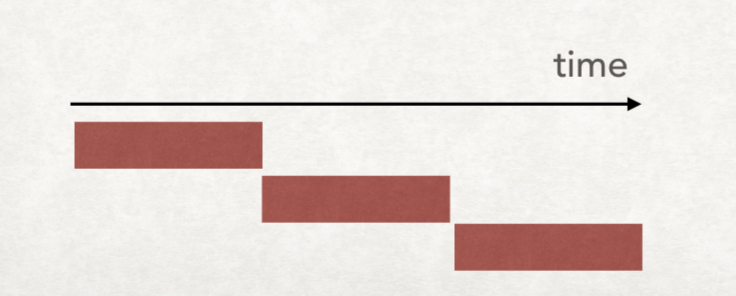
但是这样,太慢了。
于是CPU流水线技术就诞生了(大约在Intel 386里开始出现)。
原理大概是把一个组合逻辑,拆分成多个小的组合逻辑:
这样,第一个指令进行组合逻辑B的时候,第二个指令就可以进行组合逻辑A了。
我们的时间消耗可以大大减少: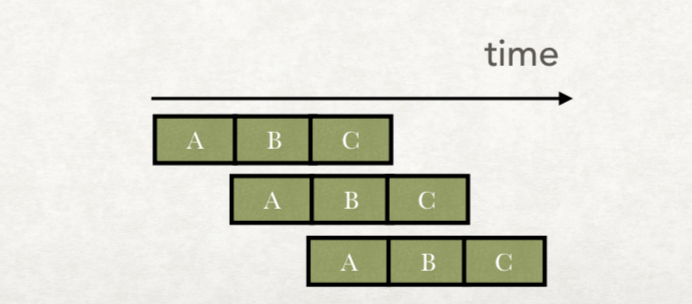
冒险
上面的例子中,流水线可以非常完美。因为我们的三个指令所需的数据都互不依赖。
但是如果指令是这样的:1
2
3Mov $0x0, %esi
Mov $0x0, %edi
Add %esi, %edi
第三个指令,是把第一个指令和第二个指令的结果进行相加
如果我们仍采用上述的流水线去运行,就会出问题: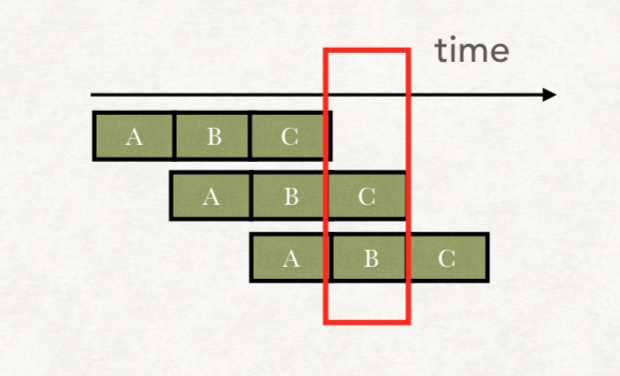
CPU在执行Add指令时,依赖第二步中%edi的值。
但是指令3执行到第二个组合逻辑时,第二个指令还没写回到寄存器。
这样下去,指令3的Add用到的%edi,其实就不是0。
和预期的结果不符合。
这个就叫冒险
其中冒险分为数据冒险和控制冒险,数据冒险就是我们上面提到的。
而控制冒险和数据冒险类似,不过一般涉及到跳转指令。
如: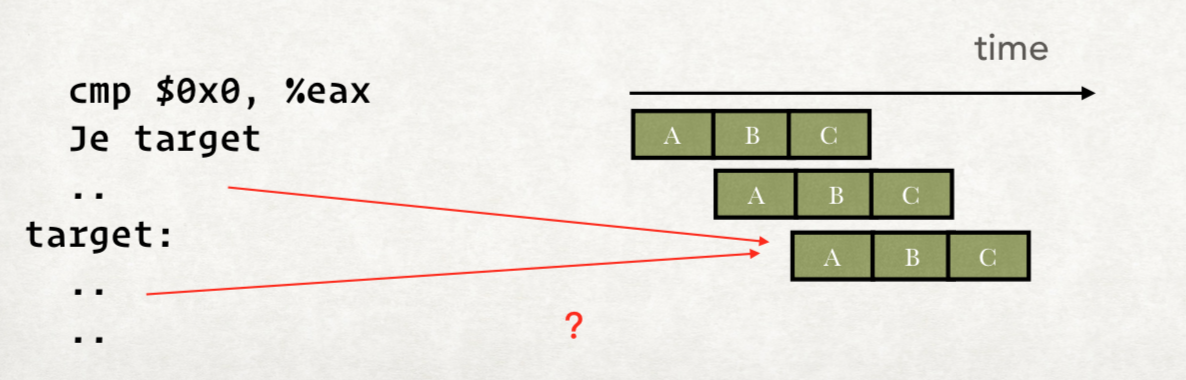
我们在执行JE的时候,依赖上一步的CMP的结果,导致正常的流水线执行就会有问题。
Bubble
那怎么解决呢?
就是插入Nop指令。
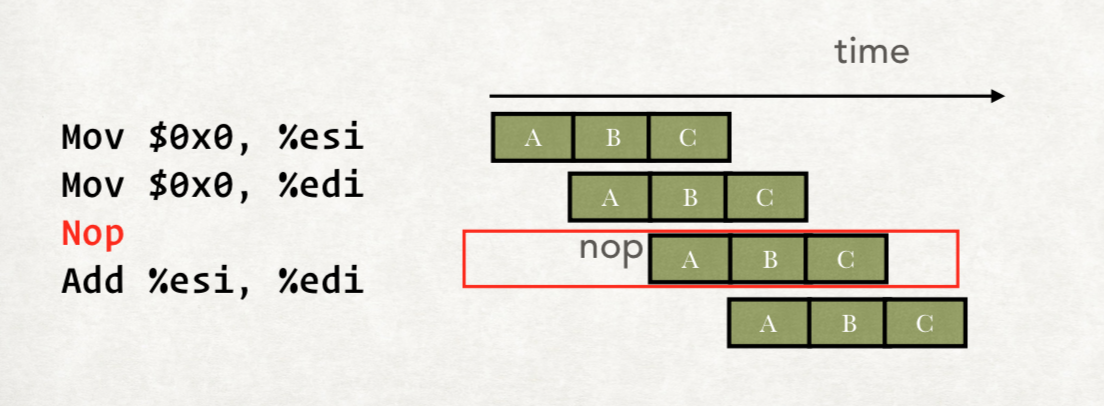
如上图所示,我们在第二个指令和第三个指令中间加入一个Nop指令,空转一个流水线。
当然我们不需要编译器每次都进行加入Nop,CPU会自己加入。
这个就叫Bubble,而执行Bubble叫Stall。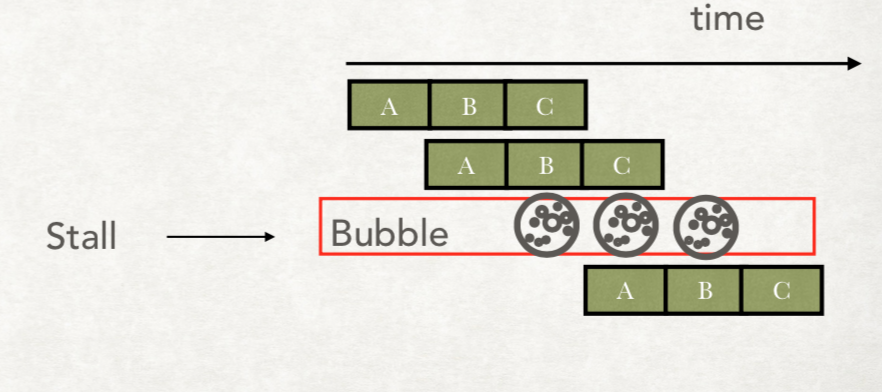
对于分支预测而言,CPU除了Bubble,还可能会随机选择一个分支先去执行,等CMP的结果出来,如果预测错了,就把执行结果丢弃掉: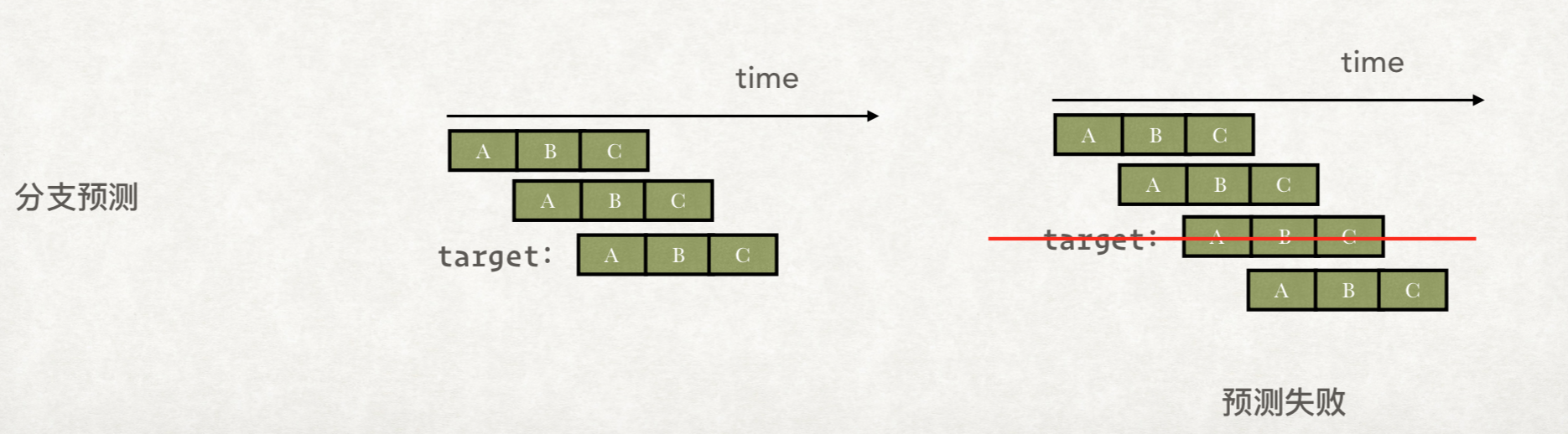
分支预测失败当然是比较消耗性能的,Google的报告上指出了一次错误的分支预测的耗时:
重排序
除了Bubble和分支预测的解决方案,还有一种解决方案,就是CPU的重排序。
对于下面的指令:1
2
3ADD AX, BX;
INC AX;
MOV CX, DX;
ADD和INC操作都用到了AX,必然会导致Stall。
但是我们发现MOV指令和ADD和INC都没有关系,
那么我们能不能调换顺序:1
2
3ADD AX, BX;
MOV CX, DX;
INC AX;
在执行时使用这种次序呢?
毕竟这种次序,就不会产生Stall,性能必然会提升。
这种就是CPU的重排序。
锅是谁的?
在x86的机器上,CPU会进行大量的指令重排序。
但是CPU重排序也不会想重排就重排的,而是需要遵守一定的规范,不然就会影响软件的正常运行。
比如说下面这段经典的代码:1
2
3
4
5
6
7
8
9
10
11
12int x = 0, y = 0;
int a = 0, b = 0;
void far() {
a=1;
x=b;
}
void bar() {
b=1;
y=a;
}
如果我们启动两个线程分别去执行far和bar函数。
正常的情况下,要么x=1,要么y=1,要么x=y=1;
但是也可能是x=y=0;
怎么解释的呢?很多人是这么解释的,这里我找了一个博客的解释:
这是处理器乱序执行的结果:
线程t1内部的两行代码之间不存在数据依赖
因此,可以将x = b乱序到a = 1前;
同时,线程t2中的y = a早于线程t1中的a = 1执行。
一个可能的执行序列如下:
t1: x = b
t2: b = 1
t2: y = a
t1: a = 1
看起来非常的有道理,CPU乱序执行害死人。
但是事实确实如此吗?
这个锅真的是CPU重排序执行导致的吗?
真的能观测到CPU的重排序吗
我对CPU不熟悉,这里我就举几个网上的答案反驳吧。
反驳一
Does an x86 CPU reorder instructions?
这个是英文回答,内容有点多,我从里面摘抄几个:
Yes, all modern x86 chips from Intel and AMD aggressively reorder instructions across a window which is around 200 instructions deep on recent CPUs from both manufacturers
肯定了x86的CPU会执行很多的指令重排序
That should answer the titular question, but then your second question is about memory barriers. It contains, however, an incorrect assumption that instruction reordering necessarily causes (and is the only cause of) visible memory reordering
这个其实超纲了,他提到了内存可见性的重排序。
否定了CPU的指令执行重排序一定会导致内存可见性问题。
At the same time, x86 defines quite a strict memory model, which bans most possible reorderings
So actually most memory re-orderings are not allowed
重点来了,x86定义了一个严格的内存模型,这个内存模型禁止了大多数可能的重排序
后续的文章中,我会提到这个内存模型。
So it is possible to define an ISA that doesn’t allow any re-ordering at all, but under the covers do re-ordering but carefully check that it isn’t observed
注意看这个词,observed。
是的,CPU确实会做指令的重排序,但是如果出现了重排序可以被observe的情况,就是BUG。
这里我们假定CPU不会出BUG。
反驳二
https://www.zhihu.com/question/53761499
有人问:
如何辨识代码是否被CPU的乱序执行优化了?
一个是中央处理器 (CPU) 话题的优秀回答者的回答:
看不到,也无法控制,ROB存在的目的就是让上层程序员看到的执行结果回归顺序。有一些memory model带来的重排序是可以被上层检测到的,比如x86的TSO模型可以通过精心设计的load store序列检测到访存的乱序。
总结
总而言之,我们记得一个词就够了:observed。
CPU确实会进行重排序,但是这种重排序是无法被我们观测到和控制的。
如果CPU没有BUG的话(基本上没听过CPU出现BUG),那么程序出现与预期不一致的行为,和CPU的重排序没半点关系。
插一句,什么内存屏障之类的,和CPU的重排序也没有关系。
参考
指令重排序
如何辨识代码是否被CPU的乱序执行优化了
https://www.cs.utexas.edu/~lin/cs380p/Free_Lunch.pdf
https://monkeysayhi.github.io/2017/12/28/%E4%B8%80%E6%96%87%E8%A7%A3%E5%86%B3%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C/
https://stackoverflow.com/questions/50307693/does-an-x86-cpu-reorder-instructions
