分区副本是Kafka中重要的概念。
下面我们来详细谈一谈副本相关的概念。
基本概念
Kafka中,每个Topic,可能有多个分区,同时为了提高每个分区的可用性,每个分区会有多个冗余备份,这个备份就叫副本(Replica),Kafka集群会将一个分区的不同副本分配在不同的Broker上,这样即使一个Broker系统宕机,也不会影响该分区的可用性。
这也是分布式系统中常见的高可用实现方式。
但是Kafka中的关于副本,还有几个比较重要的概念。
Leader副本,Follower副本
Leader副本,Follower副本:
虽然有多个副本,但是只会有一个Leader副本接收客户端的读写操作,其他的副本都叫Follower副本,Follower副本只做一件事,就是同步Leader副本的日志。
AR(Assigned Replica)
AR(Assigned Replica):
就是某分区所有副本的统称,包括Leader副本和Follower副本。
优先副本(Preferred Replica)
优先副本(Preferred Replica),也叫Preferred Leader:
Leader副本也不是随意选出的,前面提到过Leader副本是接收客户端的读写请求的,所有的Leader副本都集中在一个Broker上,那设立多个Broker进行负载均衡的意义就没有了。
所有控制器会选出每个分区的优先副本是那个,然后使用一些手段让优先副本变成Leader副本。
注意:不是每个Partition的优先副本都等于Leader副本,如果中途进行了Leader副本切换,Broker重启等事件,Leader副本就会变化,这种情况,有脚本可以手动操作。
ISR(In-Sync Replica)
ISR(In-Sync Replica):
前面提到,所有的Follower副本,只做一件事,就是同步Leader副本的日志。
但是每个副本的同步进度有快有慢,我们将与Leader副本保持一定同步的Follower副本,包括Leader副本自己,叫In-Sync Replica。
那么你可能要问了,这个“保持一定同步”的标准是什么?
落后日志小于X条?
猜的没错,确实,在Kafka的0.9版本之前,有个参数叫replica.lag.max.messages,默认值是4000。如果一个Follower副本落后Leader副本4000条消息,那么就会被移出ISR集合。
你可能会注意到,这个是在0.9版本之前,那么在之后被改掉了,为什么呢?
因为这个参数很难设置。
如果业务系统的流量一直比较平稳也就算了,但是正常的业务流量难免有波动,高的时候可能QPS就超过了这个参数,很容易就触发,低的时候每秒就1条消息,那得4000s才能发现,那也没啥意义。
所以这个参数,很难设置。
从Kafka的0.9版本开始,Broker端有个参数叫replica.lag.time.max.ms,默认值是10000,Broker会启动一个参数定时的检查每个Follower副本上次和Leader副本日志完全一致的时间(注:并不完全等于上次通信时间),如果距离现在已经过去了10000ms,那么就会把这个Follower副本从ISR集合中移除。
分区Leader
Leader副本的产生
一般来说,当我们创建一个Topic,进行分区的时候,Kafka控制器会决定分区分在哪些Broker上,同时也会决定那个副本是Leader副本,并且把这个信息写入ZK。同时通过Http请求通知其他的Broker。
Leader副本的重新选取
我们知道,每个Broker启动的时候,都会在ZK的目录下注册一个临时节点。
Kafka控制器对这个目录注册监听事件,当发生Broker断开,或者Broker新增的时候,就会触发一些响应的逻辑。
返回到我们的Leader副本,什么情况下Leader副本会不可用呢?通常来说就是Leader副本所在的Broker整个挂掉了。
Kafka控制器感应到这个事件后,就会重新指定一个副本为Leader副本。
到底指定哪一个呢?这里面有大文章。
我们慢慢来说。
在Raft中,重新选举一个Leader的条件就是谁的日志最新,谁就可以当Leader。
这样可以避免消息丢失。
在Kafka中类似,但是没有Raft中那么严格,Broker会从ISR集合中随机选取一个。
是的,随机选举一个当Leader。
我们知道,ISR集合中的副本,可不一定与Leader副本的日志完全一致的。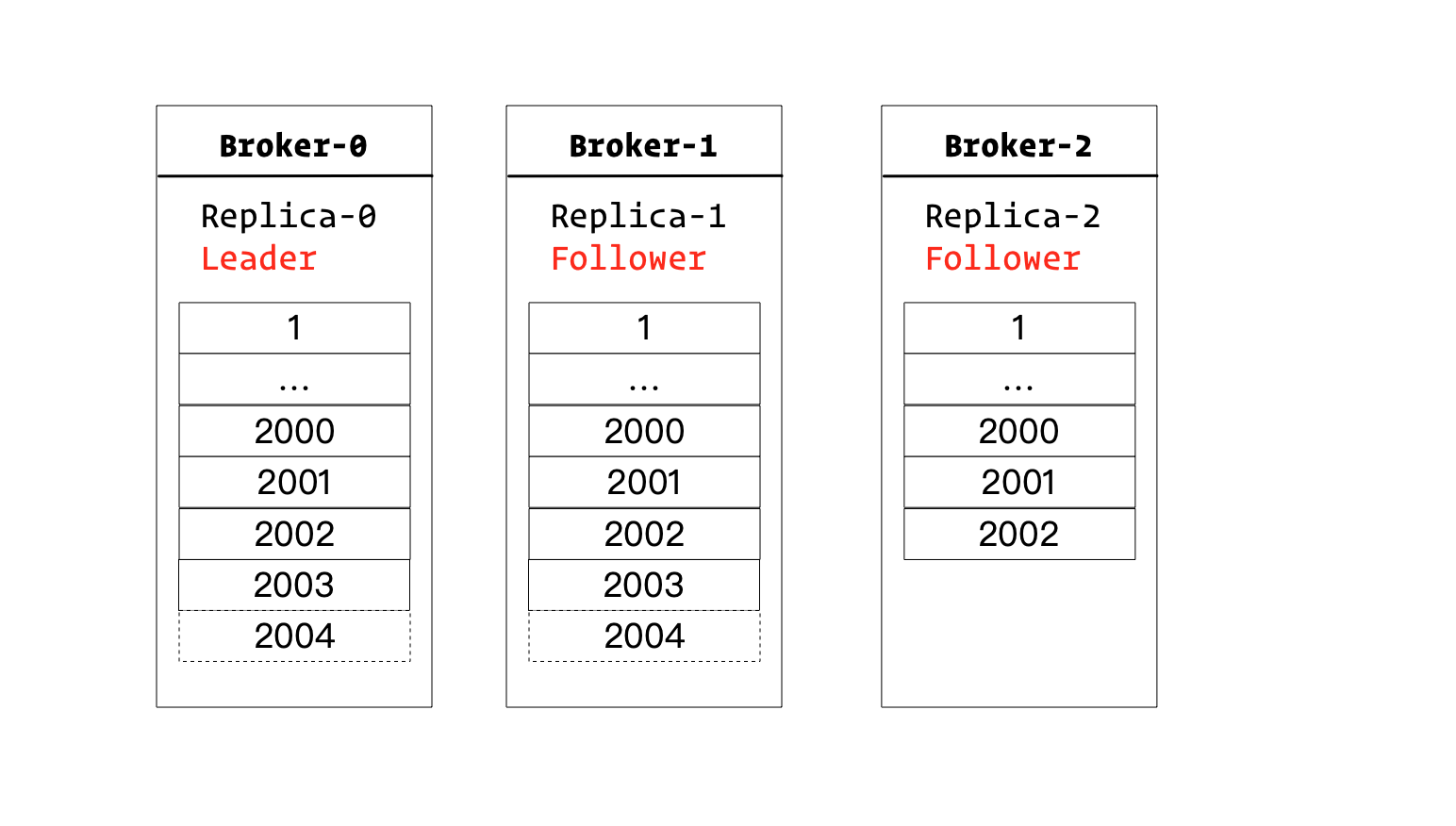
如上图所示,Leader副本如果挂掉,Follower1和2都属于ISR集合的话,虽然Follower1的日志比Follower2更新,但是Follower2也可以被选举为Leader。
当Follower2被选举为Leader后,Follower1的2003和2004的日志,都要被删除。
分区的可用性,AP还是CP
分布式系统,有个著名的理论就是CAP理论,这里有个A就是可用性。
那么Kafka作为一个分布式的系统,其实也是遵循这个理论的。
那么你会问了,Kafka是个AP系统还是个CP系统。
说到这里,不得不提一个共识性算法,叫Raft,Raft协议其实是为了构建一个CP系统,它的A属性,是保证不能挂掉一半以上的节点。
而共识性算法中,有个微软的协议叫PacificA,kafka其实和这个系统相近。
不兜圈子了,直接明说,Kafka系统到底是AP还是CP其实是可以配置的。
在Raft中,一个数据的提交,Leader节点必须要接收到一半以上(包括自己)的节点的成功响应,才能告诉客户端,说你这条消息,提交成功,我们保证,肯定不会丢失了。
把这个概念移到Kafka中,我们的Producer的发送的数据,Leader副本自己Append后,要同步给多少节点才能响应成功呢?
这个是个参数,可以配置。acks:指明分区中必须要有多少个副本收到这条消息,Broker才能响应成功。
acks=1。这也是默认值,生产者发送消息后,只要分区的Leader成功写入,就会收到成功的响应。显然,这种是不能保证数据不被丢失的。万一写完,Leader副本就挂了,Follower副本还没来得及同步。acks=0:这个比等于1还夸张,完全随缘的,不关心服务端。一般不这么设置。acks=-1,acks=all:这个参数,要保证所有的ISR副本都写入成功,才可以返回成功。结合前面我们提到的ISR的概念,会发现,单独设置这个参数其实没啥用,因为ISR集合中副本的个数你根本不知道。所以这个选项,还需要我们设置出ISR集合中,至少有几个副本:min.insync.replicas。
如果我们需要我们的Kafka是像Raft一样的CP系统,那么我们需要配置:
acks=allmin.insync.replicas=${f/2 + 1}unclean.leader.election.enable=false
显然这种,性能肯定不咋地,可用性也会大大折扣。
如果我们需要我们的Kafka系统是AP系统,那么我们需要把
min.insync.replicas=1unclean.leader.election.enable=true
这样我们可以容忍最多(f-1)个副本失效。
但是会丢失数据。
默认值:当然大部分人肯定没关心过这两个参数,其实从参数的设计来看,Kafka其实偏向于一个AP系统,acks的默认值为1,min.insync.replicas的默认值也是1,unclean.leader.election.enable的默认值是false。
这么配置的话,如果ISR集合中,某一时间只有Leader副本,同时恰好宕机了,那么整个分区就不可用了。
ISR更新
对于ISR流程的更新,笔者也画了一些示意图,当然其实流程大家心里应该也清楚了。
流程一
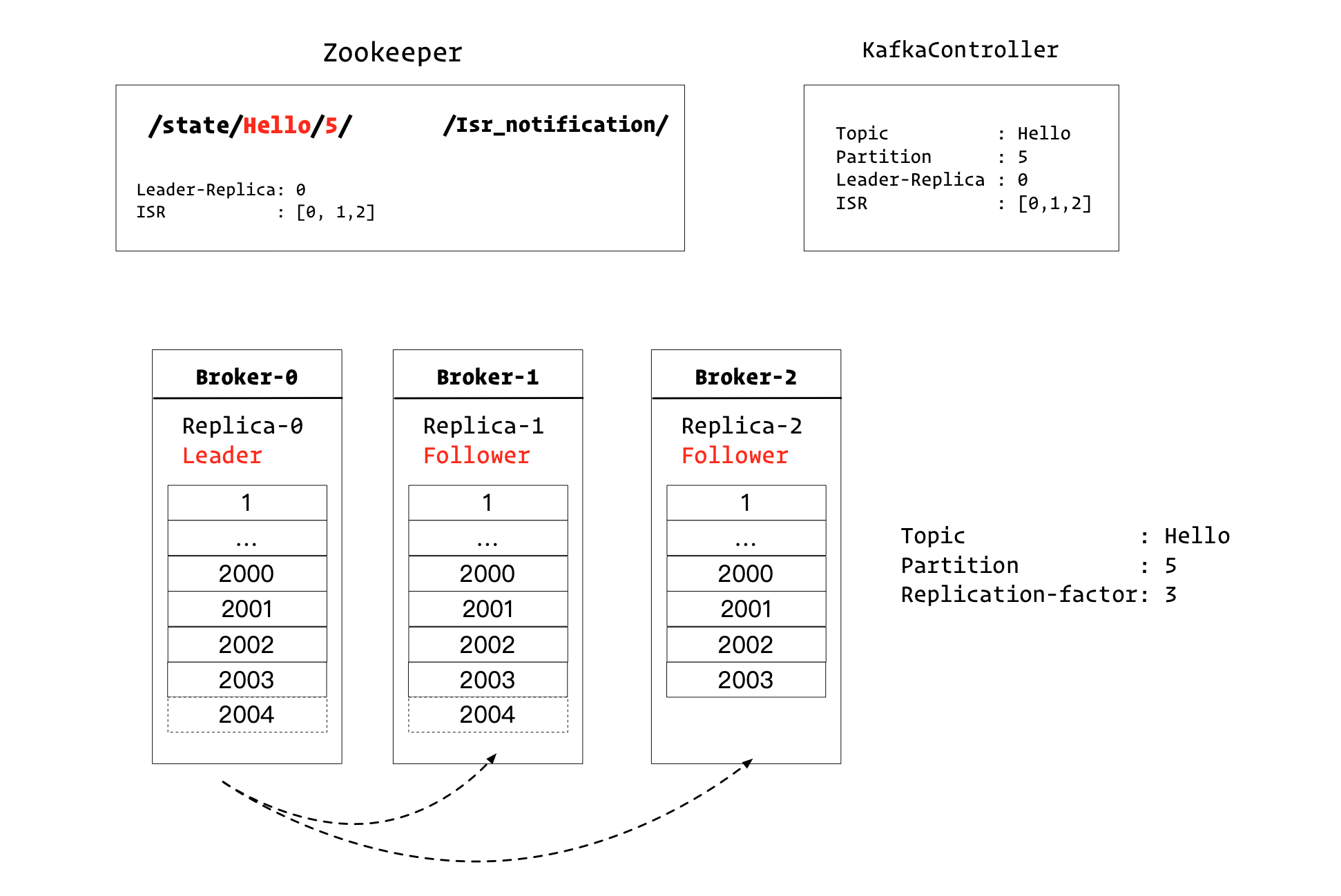
如上图所示,我们有3个Broker。
对于Topic=Hello而言,我们假设他有10个Partition,其中每个Partition有3个副本。
图中所示的是Partition5的副本分布情况。
Leader副本,也就是Replica-0,在Broker-0节点上。
这个时候,ISR集合有[0,1,2]。
在Kafka控制器和Zookeeper中都记录了该信息。
对于ZK而言,在/state/Hello/5节点中记录了该信息。
并且/Isr_notification/节点下,没有子节点。
图中没有标明的一点是:KafkaController监听了/Isr_notification/节点。
流程二
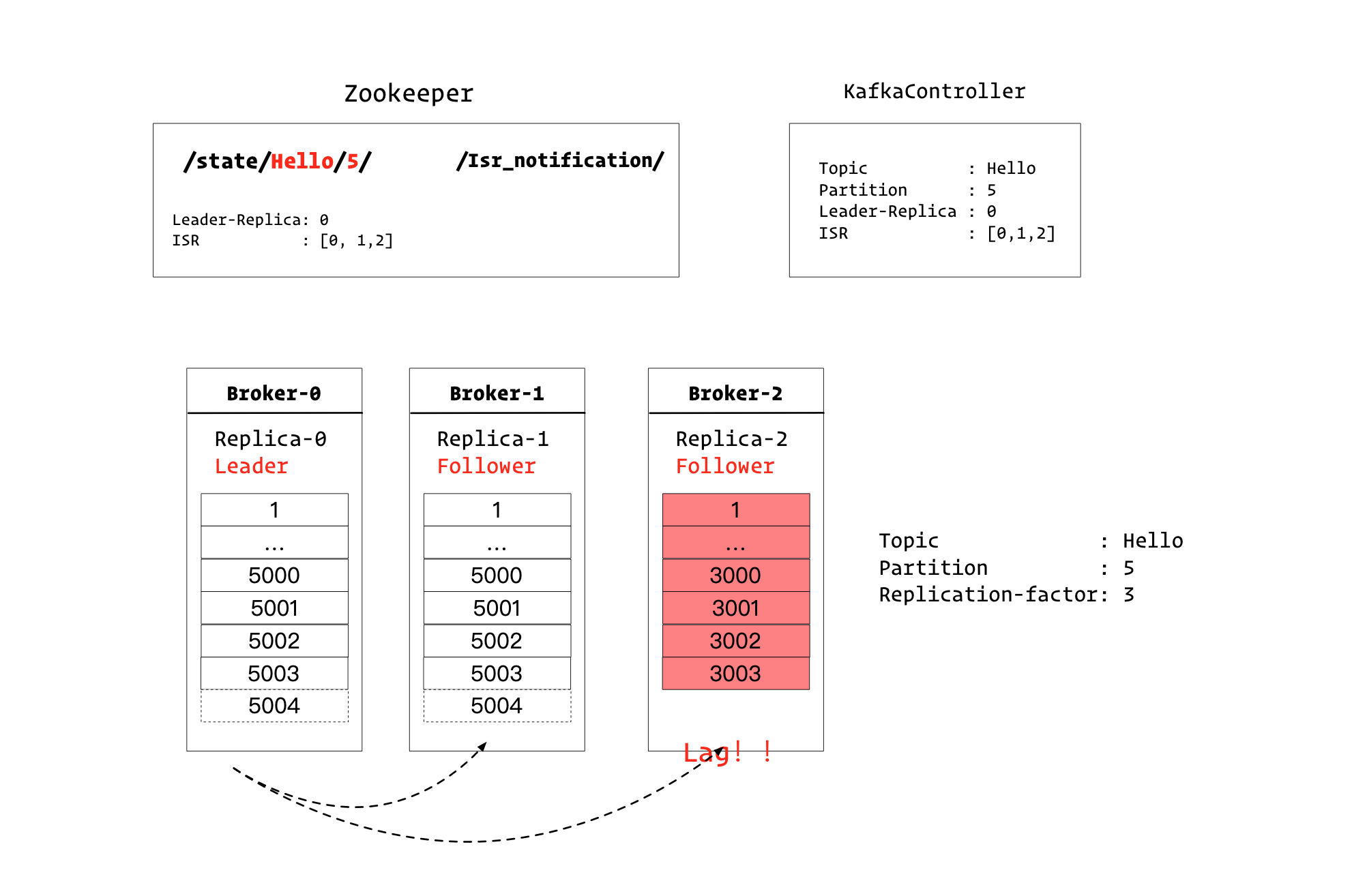
渐渐的,副本2同步日志出现了落后,被Leader副本检测到了,下面Leader副本需要更新ISR集合。
流程三
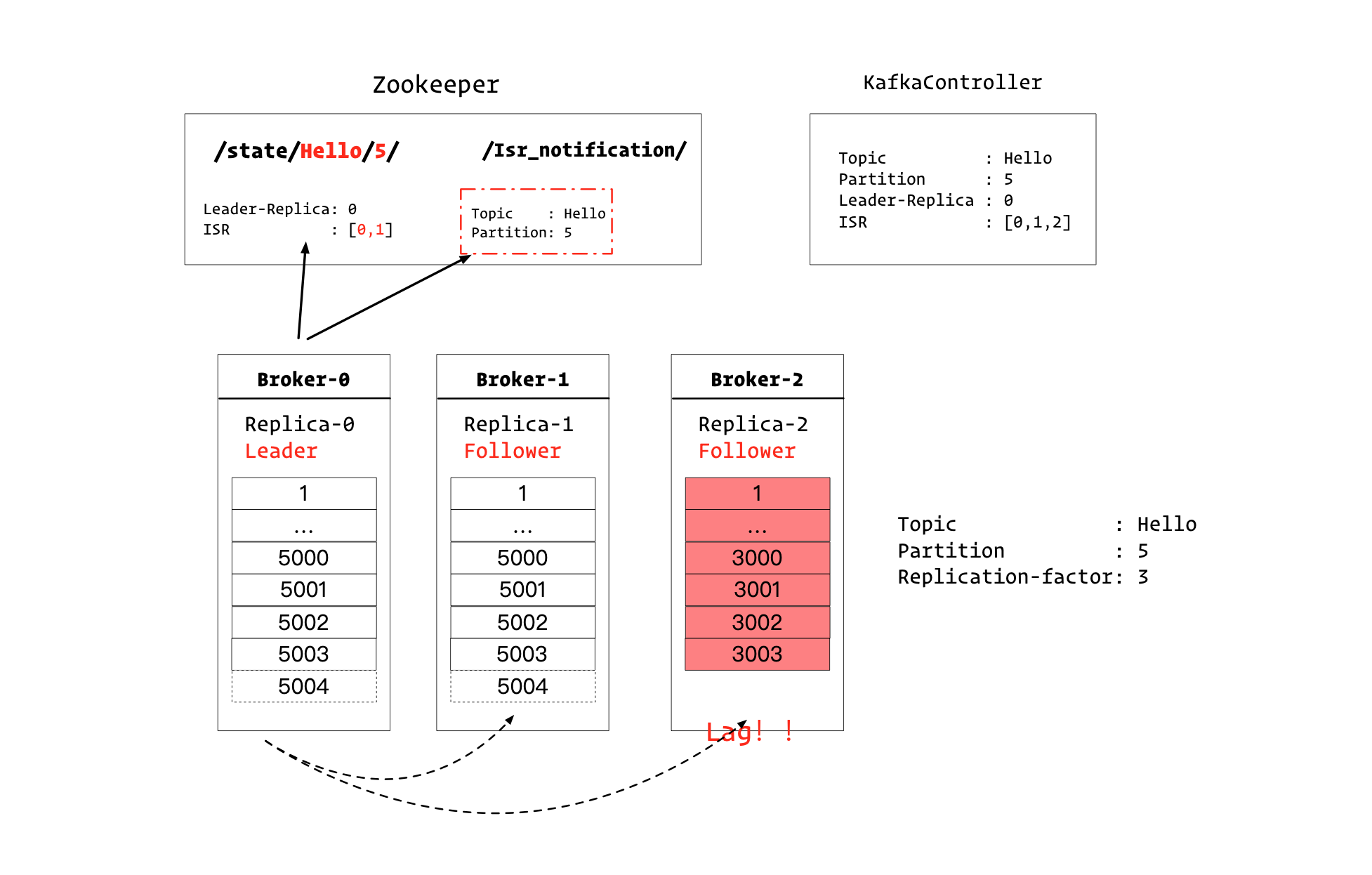
Leader副本所在的Broker0,会连接ZK,做两个操作:
- 修改
/state/Hello/5/的值,把ISR集合中的2移除 - 在
/Isr_notification/下新增一个节点,表示Hello的Partition的ISR集合发生了变化
流程四
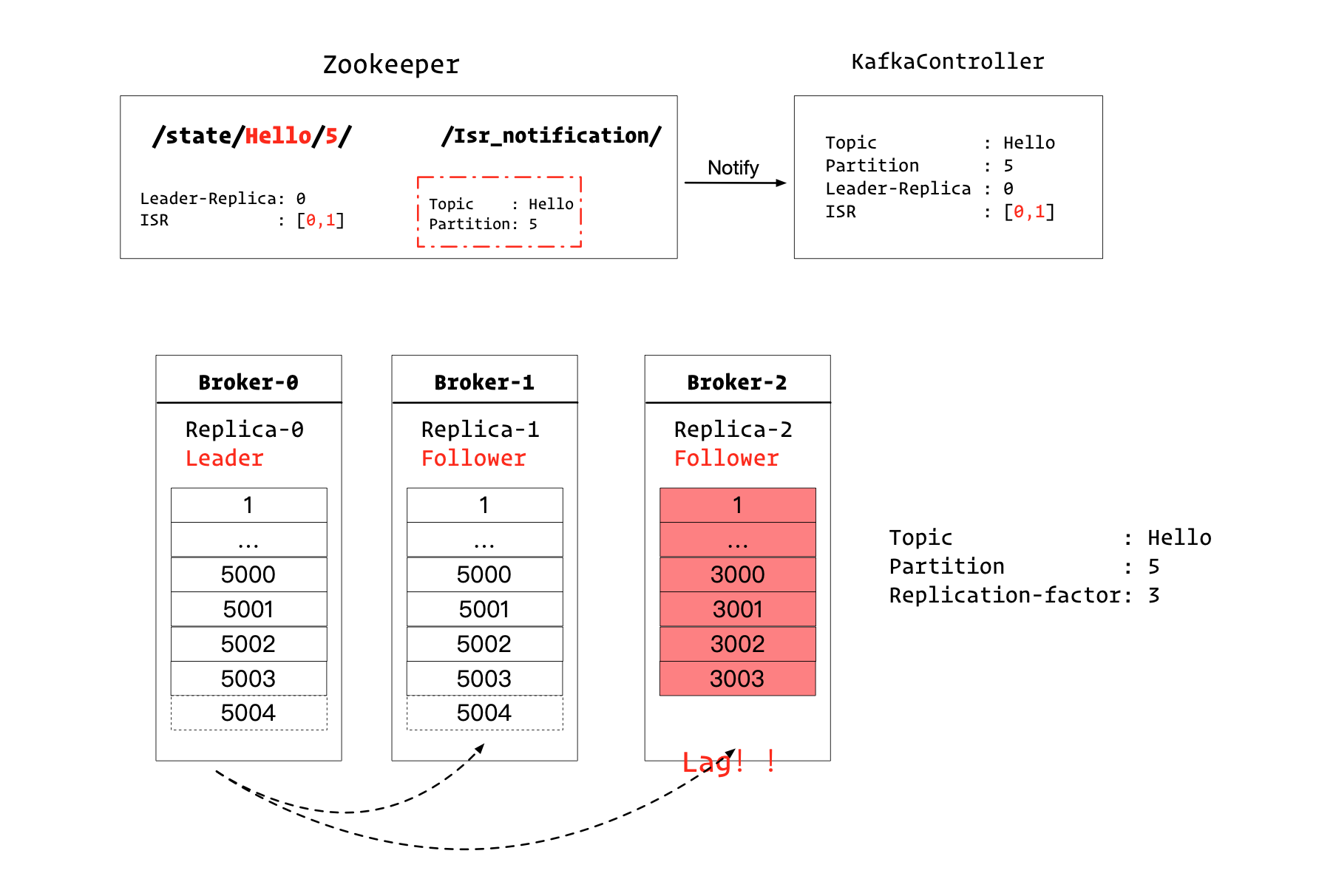
ZK会通知Kafka控制器
流程五
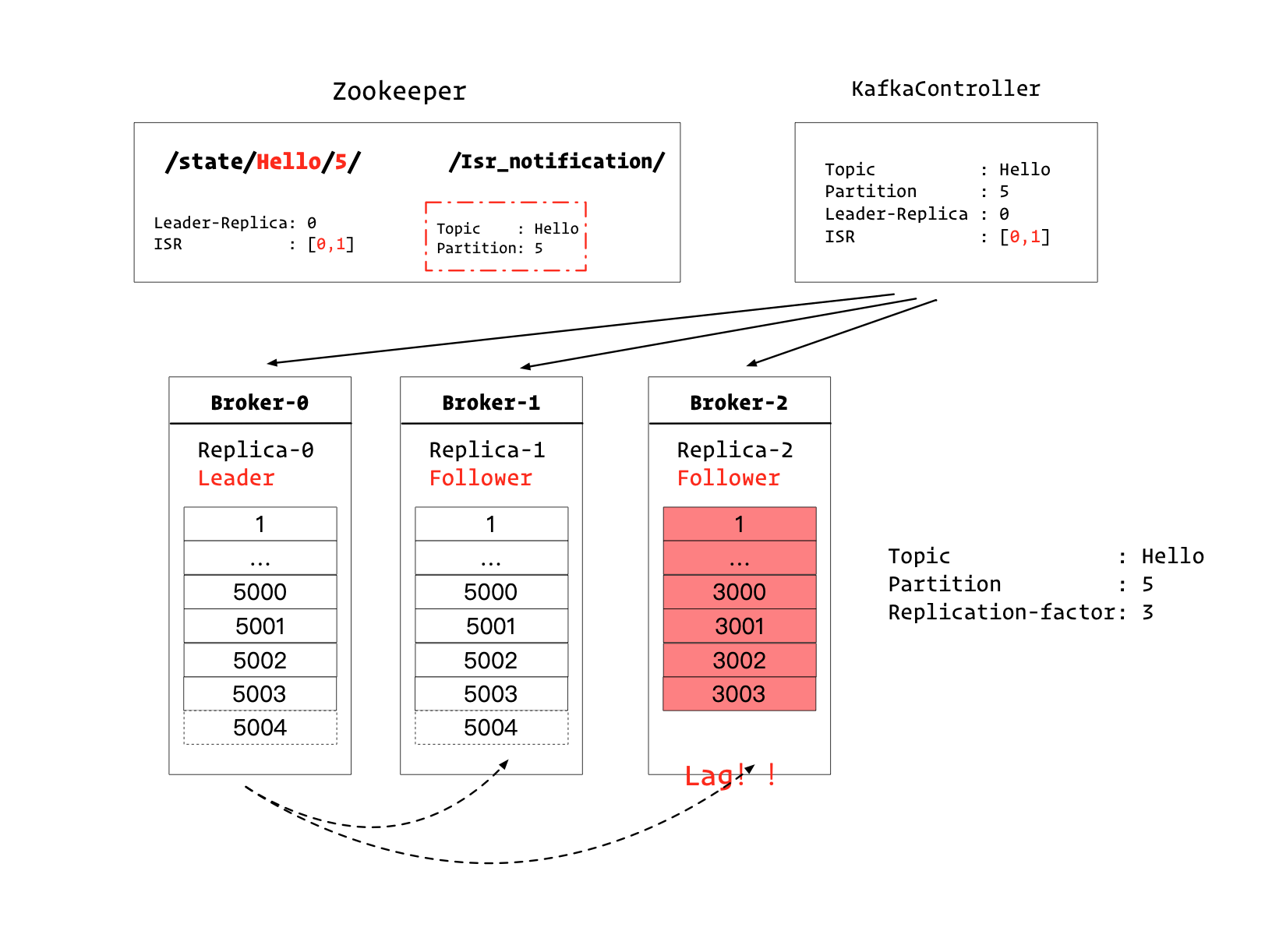
Kafka控制器会做两个操作:
- 更新自己的元数据,将副本2从ISR集合中删除
- 通知其他所有的Broker,更新其元数据。
