前言
HotSpot的初衷是将运行环境分为Client和Server,并且为他们定制了不同的JIT策略以及不同的JIT编译器(C1和C2)。
设计出ClientMode的年代,个人PC的性能还比较低,无论是CPU资源还是内存资源都比较稀少且价格较高,所以C1节约资源的快速编译是很有必要的。
随着时代的发展,个人计算机的配置在慢慢升级,同时价格也在慢慢降低,在这种环境下,ClientMode并不是那么适用了,所以HotSpot也就慢慢放弃了ClientMode,在个人计算机上默认采用Server模式。
Oracle的想法
所有的场景都默认使用Server模式自然是没有什么问题的,但是Oracle并不甘心(作者脑补的),主要不甘心在两个方面:
- 默认使用Server模式,那么相当于放弃了开发了很久的C1编译器
- 由于Server模式JIT编译策略问题,会导致应用的Warm-Up时间较长
那么有没有什么方法可以结合C1和C2呢?
比如用C1解决Warm-Up时间过长的问题。
分层编译
前面提到过,Oracle想用C1解决Server模式中Warm-Up时间过长的问题,于是引入了分层编译的概念。
如下图所示:
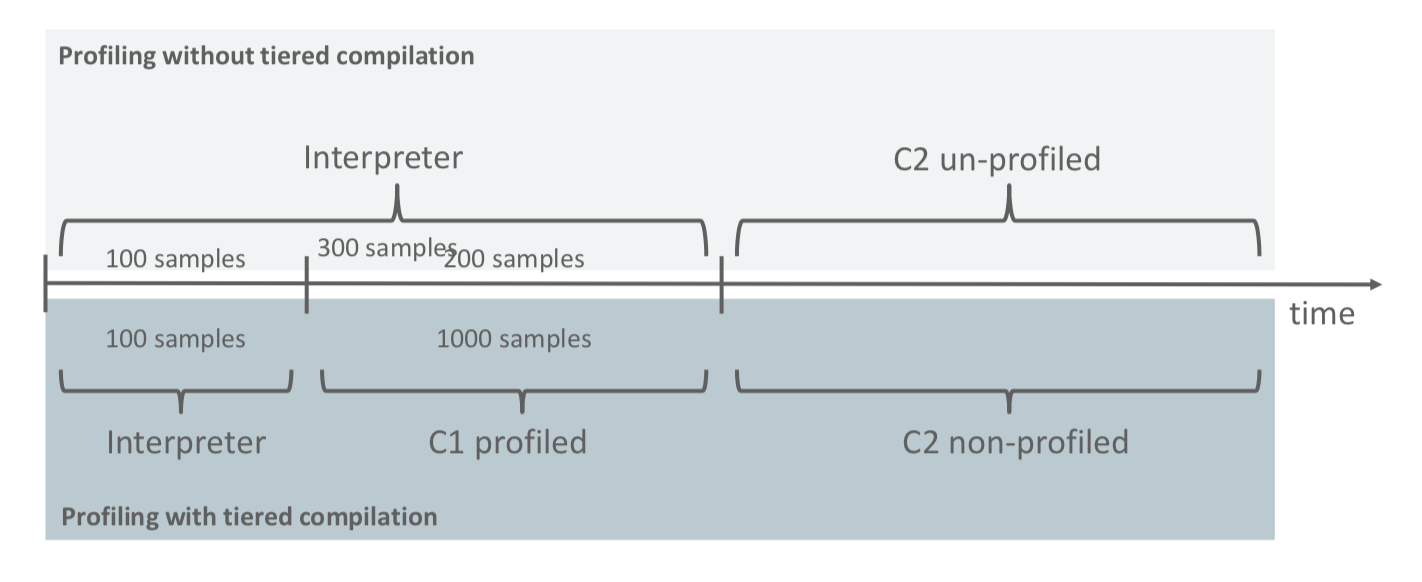
解释阶段主要是为了收集运行时Profile,Profile收集的越多,对JIT编译出的代码性能帮助越大。
先看上半部分图,如果我们采用传统的ServerMode运行,在一段时间X内,只能收集300份Profile,然后将这些Profile丢给C2去进行编译。
我们可以减少解释模式的运行时间,尽快用C1把字节码编译成机器码,用机器码去收集Profile。这就如下半部分图所示:
收集了100份Profile后,运行C1编译后的代码,在一段时间内,可以收集到更多的Profile。
上面是限制了收集Profile的时间是一定的,如果我们反过来,收集Profile的样本数是一定的:
- 传统的Server模式,可能需要花费更多的时间进行收集到指定次数的样本
- 先利用C1进行代码编译,提升方法的运行速度,相对可以花费更少的时间进行收集
如上的思想就是引入C1解决传统的ServerMode热身时间较少的问题,也就是分层编译:先采用C1进行编译,再采用C2进行编译。
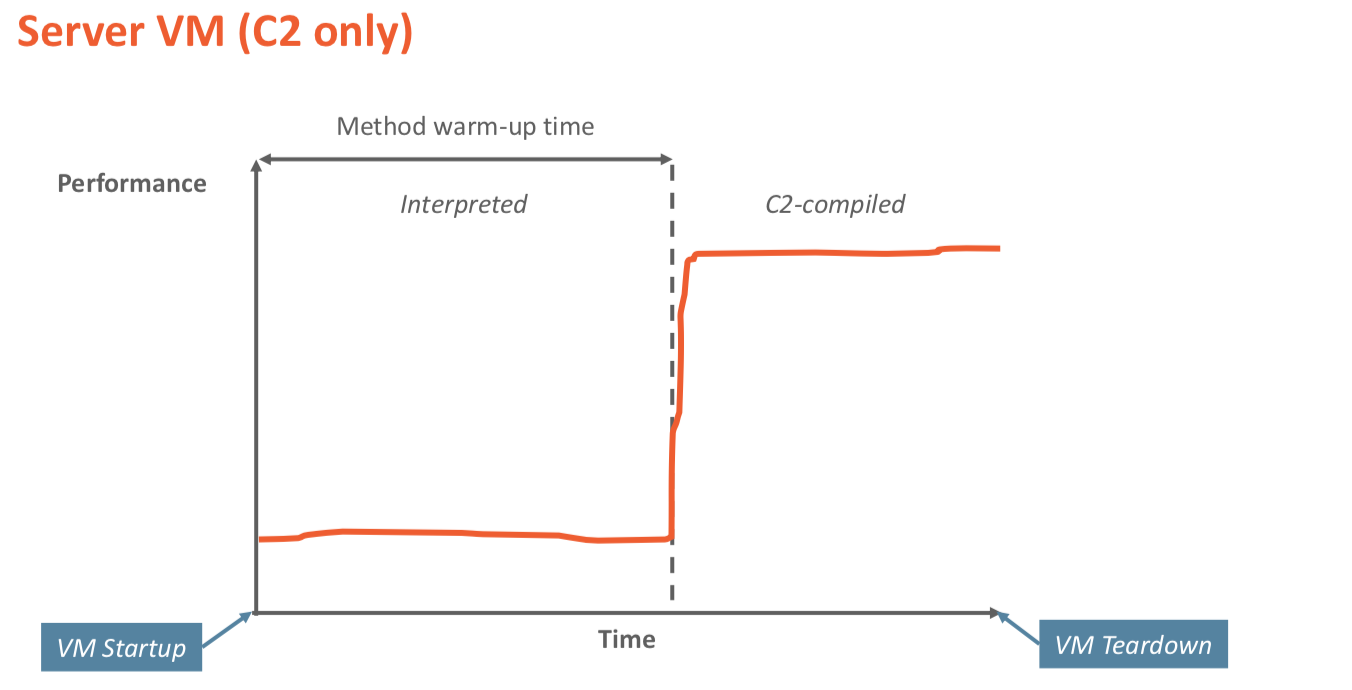
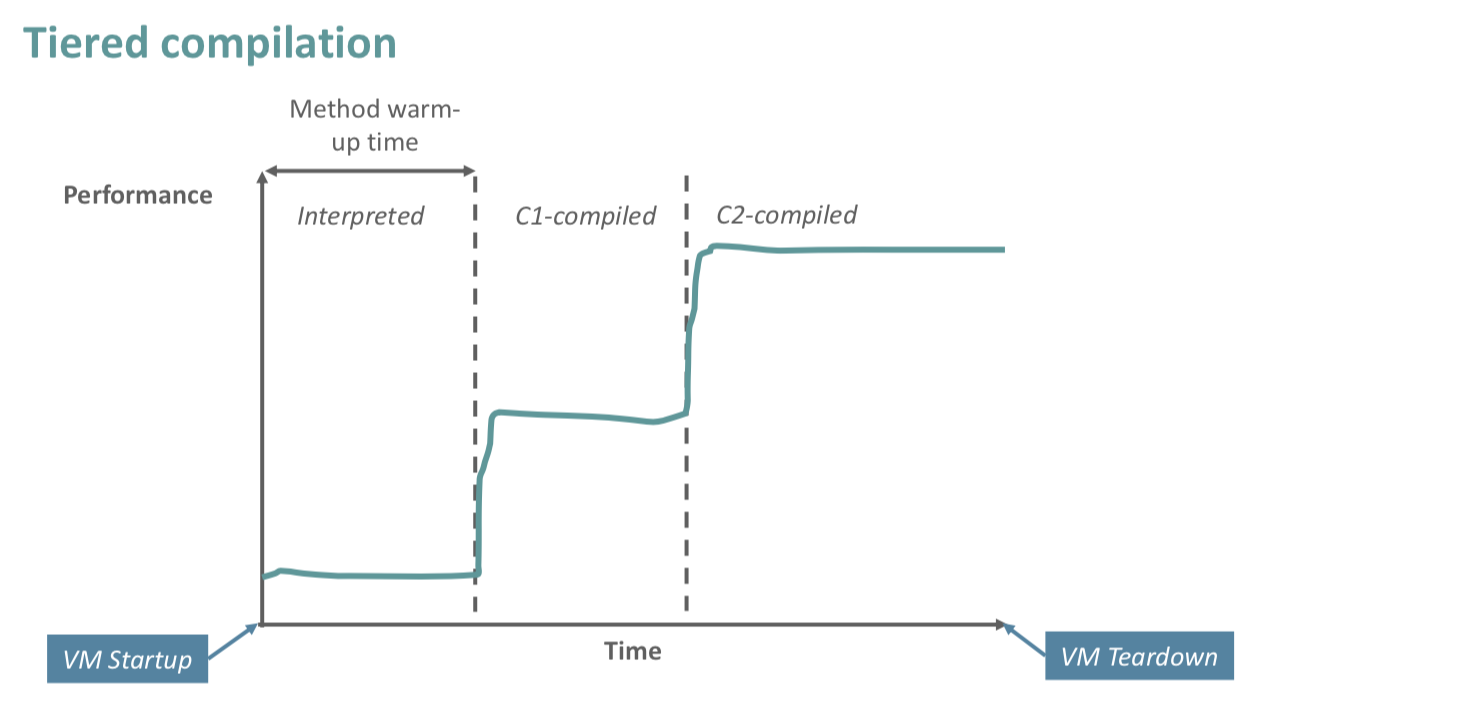
具体的时间对比如下两张图所示:只使用C2 VS 分层编译
参数
分层编译在JDK7中就引入了,但是默认是不开启的
如果运行环境还是JDK7,可以使用-XX:+TieredCompilation开启
在JDK8中,分层编译就默认开启了,如果要关闭它,可以使用-XX:-TieredCompilation关闭
扩展
正常的话,只要理解到上面就够了,分层大概分为两层,先是C1,然后是C2。
但是事实上,我们如果查看以Tier开头的HotSpot参数的话,会发现其包含的参数很多很多
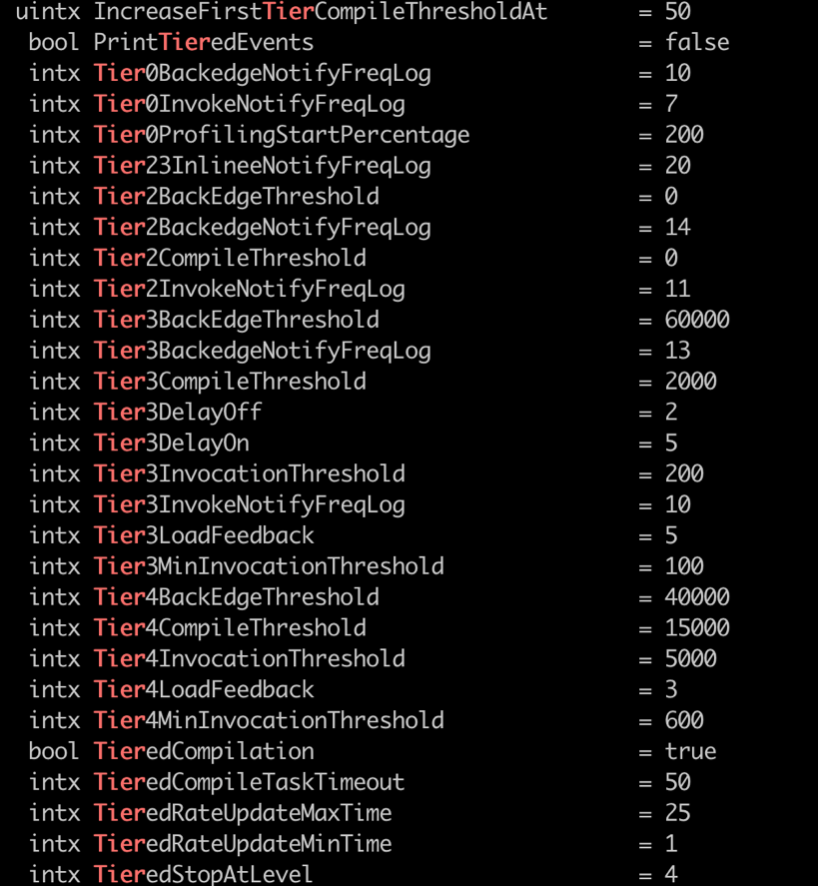
笔者第一次搜索出来时,实在是吃了一惊。
经过研究,其实发现分层编译,并不是分了两层,而是足足分了4层。
- 第0层:解释阶段
- 第1-3层:C1编译
- 第1层:C1编译出的不收集任何Profile的机器码
- 第2层:C1编译出的仅仅收集方法调用计数的机器码
- 第3层:C1编译出的收集全部Profile的机器码
- 第4层:C2编译
可以看到,在C1编译的阶段,还拆分成了三个小的阶段。
同时,对于这三个小的阶段,需要理解的是,运行上并不是递进关系,也就是说并不是先运行第1层,再运行第2层,再运行第3层。具体怎么运行,其实和很多因素有关。
我们先看看有哪些经典的分层流程:
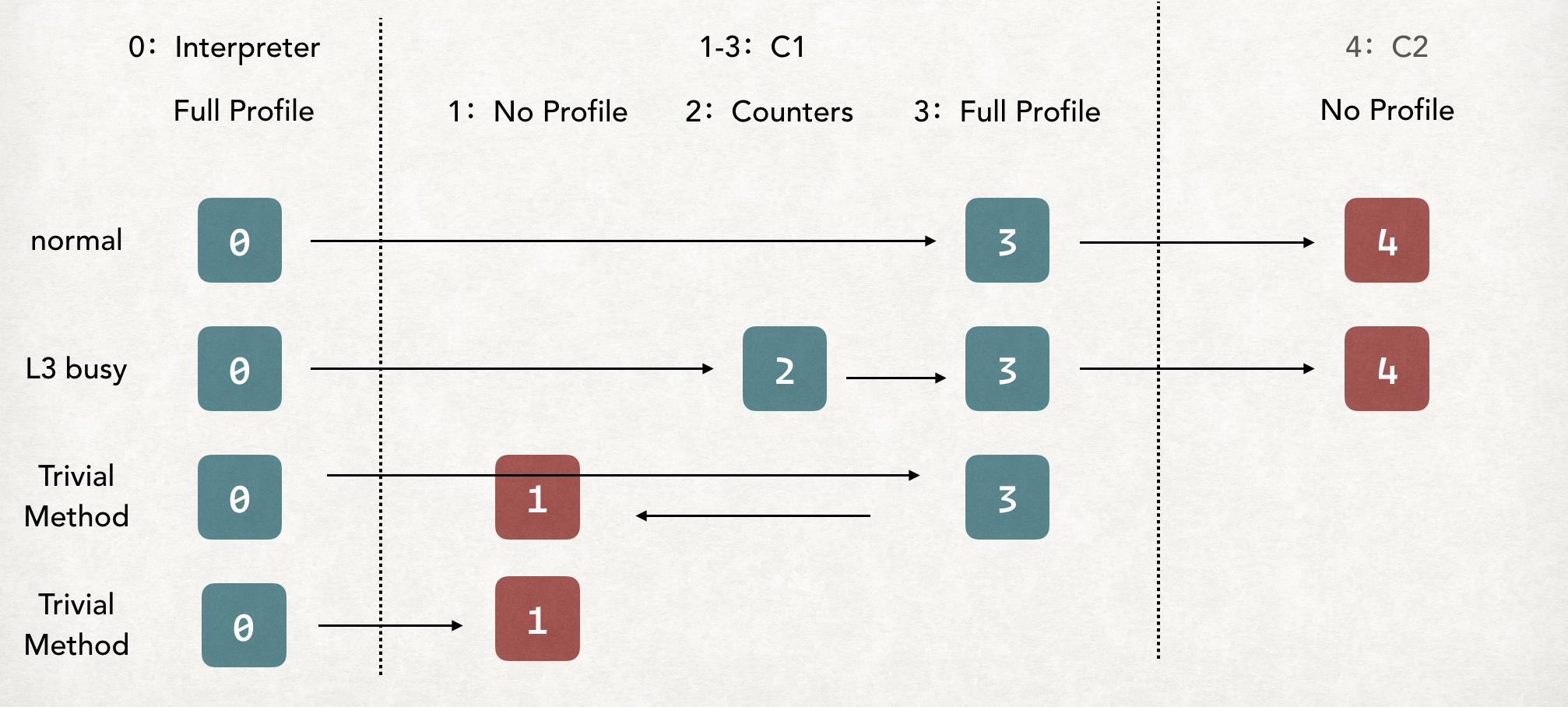
如上图所示。
- 流程1:正常的方法的编译流程,先是解释执行,然后直接跳到第3阶段,也就是C1编译出的收集全部Profile的机器码。然后再跳到第4层,也就是C2编译。深色的框表示是编译的终止阶段。
- 流程2:但是,如果第3层的等待队列太长,可能就先提交到第2层进行编译,等待一段时间后,再提交给第3层
- 流程3:如果该方法比较简单,是个Trivial方法,比如Getter方法,这种方法去收集Profile其实没有什么Profile,给C2去进行编译纯属于浪费资源,所以提交给第3层后,直接给第1层,然后终止。
- 流程4:同样也是Trivial方法,如果在解释阶段就发现其比较简单,也可以直接提交给第1层编译
以上是一些经典的流程,还有一些流程,比如从解释阶段可以直接提交给C2等。
所以,虽说是分层编译,但是具体的编译流程是不确定的,这个各个编译器的状态以及方法的属性有关。
C1和C2编译线程数
各个编译的状态,最简单的就是负责编译的线程数
HotSpot分配给C1和C2编译器的线程数,和指定的启动参数以及机器的核心数有关。
启动参数:影响线程数的参数有CICompilerCount和CICompilerCountPerCPU两个,默认值如下,一般不会去改这些
有了参数之后,具体的分配代码如下: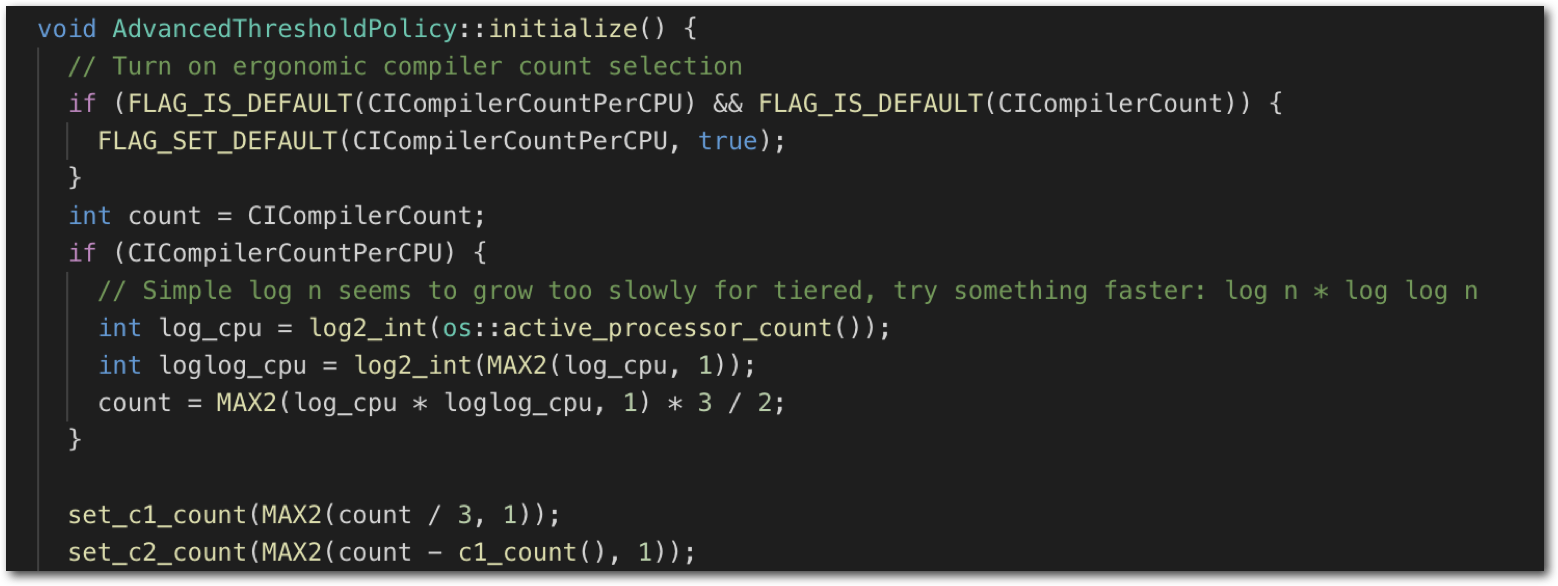
简单聊聊分配策略:
- C1+C2的总的线程数:log2(log2(CoreNum)) * 3 / 2
- C1 / C2 = 1 / 2
- C1和C2至少有一个线程
下面表格简单显示了一些常见情况
| CPU Core | C1 | C2 |
|---|---|---|
| 4 | 1 | 2 |
| 8 | 1 | 3 |
| 16 | 4 | 8 |
| 32 | 5 | 10 |
| 64 | 6 | 12 |
