前言
前文讲述了C1和C2的功能定位,以及引出了Client和Server模式的区别。
这回抛开功能和定位的角度,简单看看从设计与实现角度的区别。
前导知识
要讲解设计与实现角度的区别,需要了解很多的编译原理知识。
😄编译原理是科班必学的一门课,当时作者上的迷迷糊糊的,觉得没什么用,也没怎么听。
现在看到C1和C2的东西,真的是一筹莫展。
相信很多科班和非科班的人也是。
不过大家不用担心,作者水平有限,更是不会瞎写自己根本不会的东西,所以涉及到编译原理的东西讲的都很简单。
IR
IR,中文中间表示,全称是intermediate representation。
其实它和中间语言的定义类似,但是中间语言的定义更加狭义,只规定必须是某种语言,而中间表示则扩宽了范围,可以是树类型或者是图类型的表示。
在维基百科上,中间语言的定义是
中间语言(英语:Intermediate language),在计算机科学中,是指一种应用于抽象机器(abstract machine)的编程语言,它设计的目的,是用来帮助我们分析计算机程序。这个术语源自于编译器,在编译器将源代码编译为目的码的过程中,会先将源代码转换为一个或多个的中间表述,以方便编译器进行最佳化,并产生出目的机器的机器语言
其实更简单的定义,我觉得就是源代码的另一种表达形式。
比如Java代码,会被编译成字节码,字节码也是一种IR,是Java代码的中间表示。
IR在编译原理中的作用个人理解其实起到两种:
- 统一后端语言。比如JRuby,Scala,Kotlin等,他们的解释器其实都是JVM。但是他们的源代码都是不一样的。倘若对于每种语言的处理都是不一样的,那其实JVM的实现就没什么意义了,所以将所有语言的源代码都编译成同一种IR,然后JVM不用关心源语言是什么,只要符合该IR定义的都可以执行。
- 方便优化。很多的优化技术,其实人眼可以简单看出的,很难归一化到程序去理解。但是通过一些IR的表示,使用特定的规则,就可以进行优化。就行我们在拼魔方时的公式一样。那为什么有这么多种IR呢,很大一个程度的区别就是他们在解决一些特定优化时各有优势。比如SSA在进行复制传播时就很方便。
寄存器分配
一个解释器执行的程序和以机器码执行的程序的一个很大的区别就是对于系统寄存器的使用。
比如对于下面的函数
1 | public int add(int i, int j) { |
如果是以解释的形式而言,则需要把k存在内存的变量中,然后再进行运算,每一步的运算都要把k的值写回到内存中。
但是如果是C++的话,完全可以给k分配一个寄存器,把k放到寄存器中,然后直接对寄存器中的值进行运算就行。
所以,如果能够很好的利用系统现有的寄存器,那么程序执行的性能将提升一个档次。
对于寄存器的分配算法,有很多论文可以参考,作者水平有限,还没能学会一种。
读者有兴趣可以自己去搜索相关论文进行了解。
C1流程

C1的流程较为简单,如上图所示。
首先,字节码会经过转换,变成HIR,也就是High Level的IR,高级中间表示。
在HIR中,会进行一些优化,比如
- GVN优化
- 基本块优化
- null检查消除
- …
经过HIR优化之后,转换成LIR,也就是Low-Level的IR,低级中间表示。
这个阶段的IR其实已经很接近机器码了
在LIR时,进行
- 寄存器分配。这里的寄存器分配算法是线性扫描,时间消耗短,但是分配效果有限
- 窥孔优化
在LIR的优化过后,就是机器码的生成。
对于C1的更详细的流程,笔者也从网上找到了当时作者的一个PPT,有兴趣的可以自行下载
http://compilers.cs.uni-saarland.de/ssasem/talks/Christian.Wimmer.pdf
同时,如果有人对线性扫描寄存器分配算法有兴趣,也可以参照论文
http://web.cs.ucla.edu/~palsberg/course/cs132/linearscan.pdf
C2流程
通过前面我们已经知道C2相对于C1编译过程,更加的耗时,这个耗时可以体现在两方面
- 比C1有更多的优化
- 同一种优化使用的算法不同,C2的结果更好
对于C2而言,它的IR只有一种,叫Sea Of Nodes
就笔者了解到的知识来看,这个IR非常的牛逼,在V8引擎中,也是使用的这种IR。
不过这种IR的资料似乎非常少,笔者也仅仅是搜到了论文,没什么更深层次的讲解。
如果有人想要了解Sea Of Nodes的原理,那么大家可以从网上搜集资料来看。
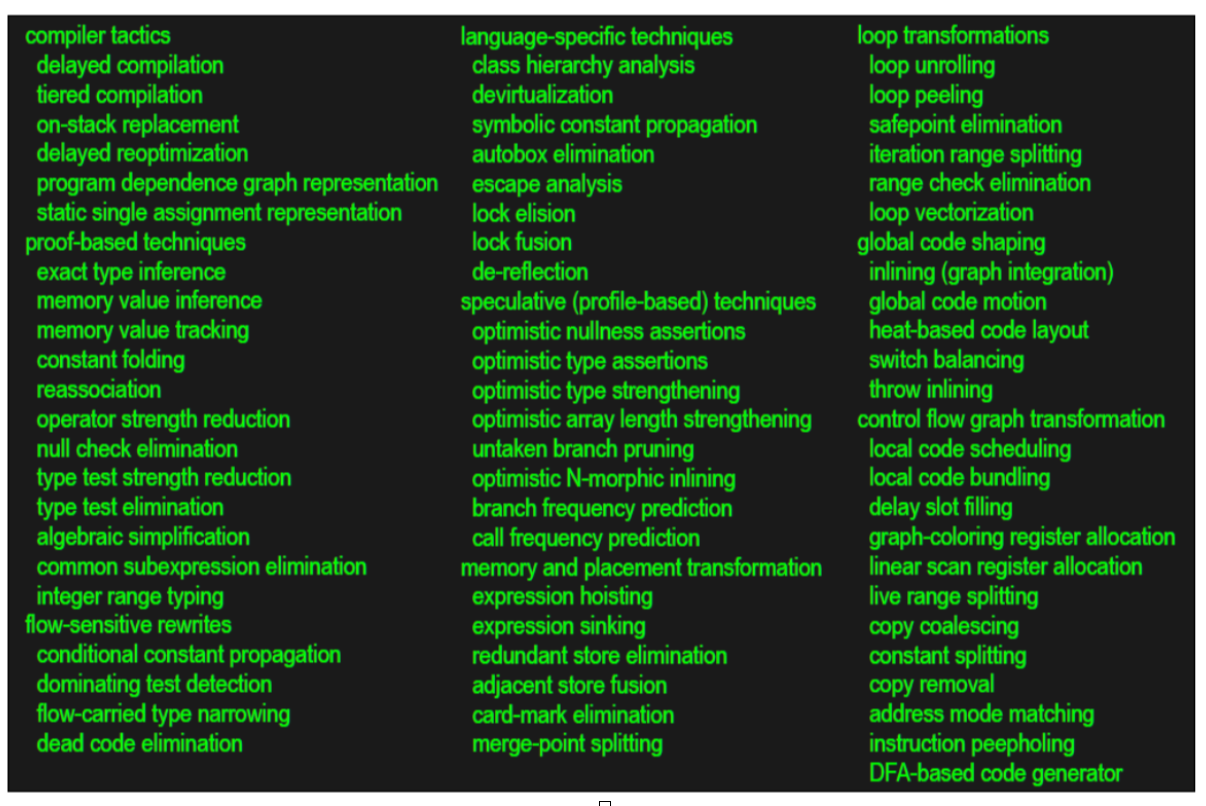
比C1拥有更多的优化
相比较于C1,C2几乎会做所有的经典优化。如下图所示
同一种优化使用不同的算法
这个体现在寄存器分配算法上,我们知道对于C1而言,使用的较为简单的线性扫描的分配算法,执行较快。
而C2使用了叫图染色的算法,消耗的时间更久,但是产生的解法比线性扫描更优。
对于图染色算法,在经典的编译原理书中都有解答。
笔者这里就不赘述了(其实是笔者也没看懂)
