内存屏障是随着SMP系统的出现而出现的,也就意味着在单核的机器上,不需要任何的内存屏障。
所以要想理解内存屏障的意义,我们需要知道CPU从单核到多核,究竟修改了什么,需要我们引入内存屏障
单核时代
如果我们把CPU看做黑盒的话,简单的计算机中,除了CPU负责运算外,还需要存储系统进行存储。这个存储系统就是主存。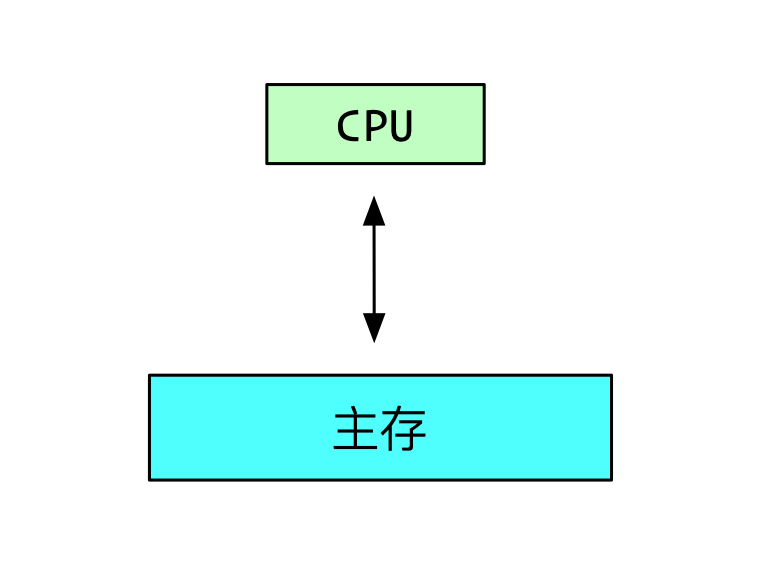
但是问题来了,我们知道cpu的速度其实是很快很快的,但是主存的写入和读取的速度过慢,如果这么运行的话,会导致cpu的很多时间都浪费了。
如果在cpu和主存中间,加入了很多的cache系统,通常来说有L1,L2,L3等。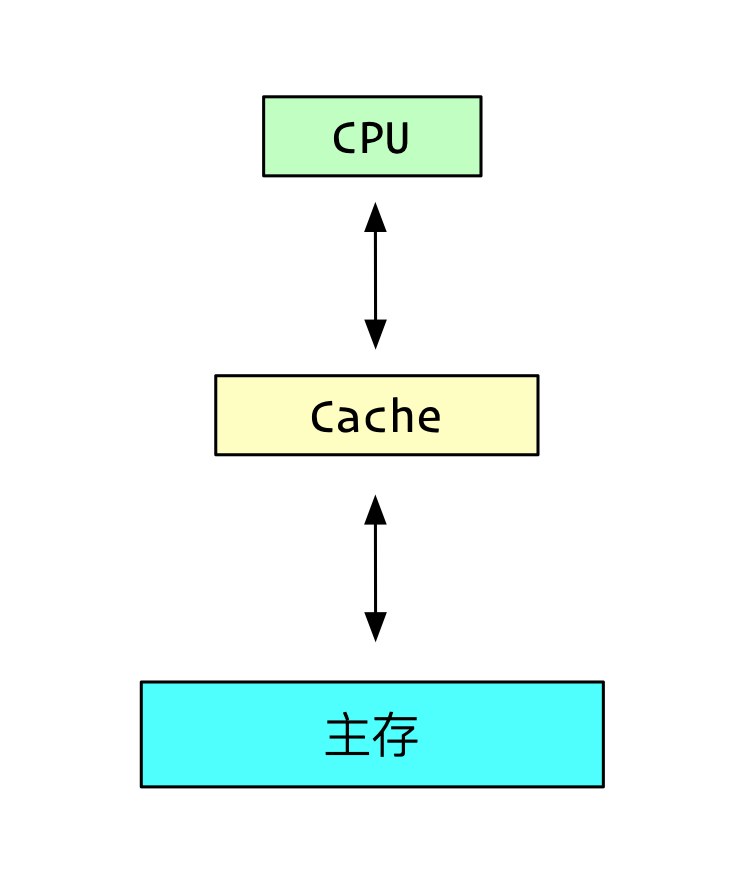
cache的速度比主存快的多,这样会大大的提高性能。
在单核的系统中,当然是没问题的,因为只有一个CPU,所有的读取和写入都是它。
虽然一个值可能在主存和Cache中都有,但是都以Cache中的为准就行了。
多核时代
但是引入了SMP多核系统后,每个核心都有一个属于他自己的Cache。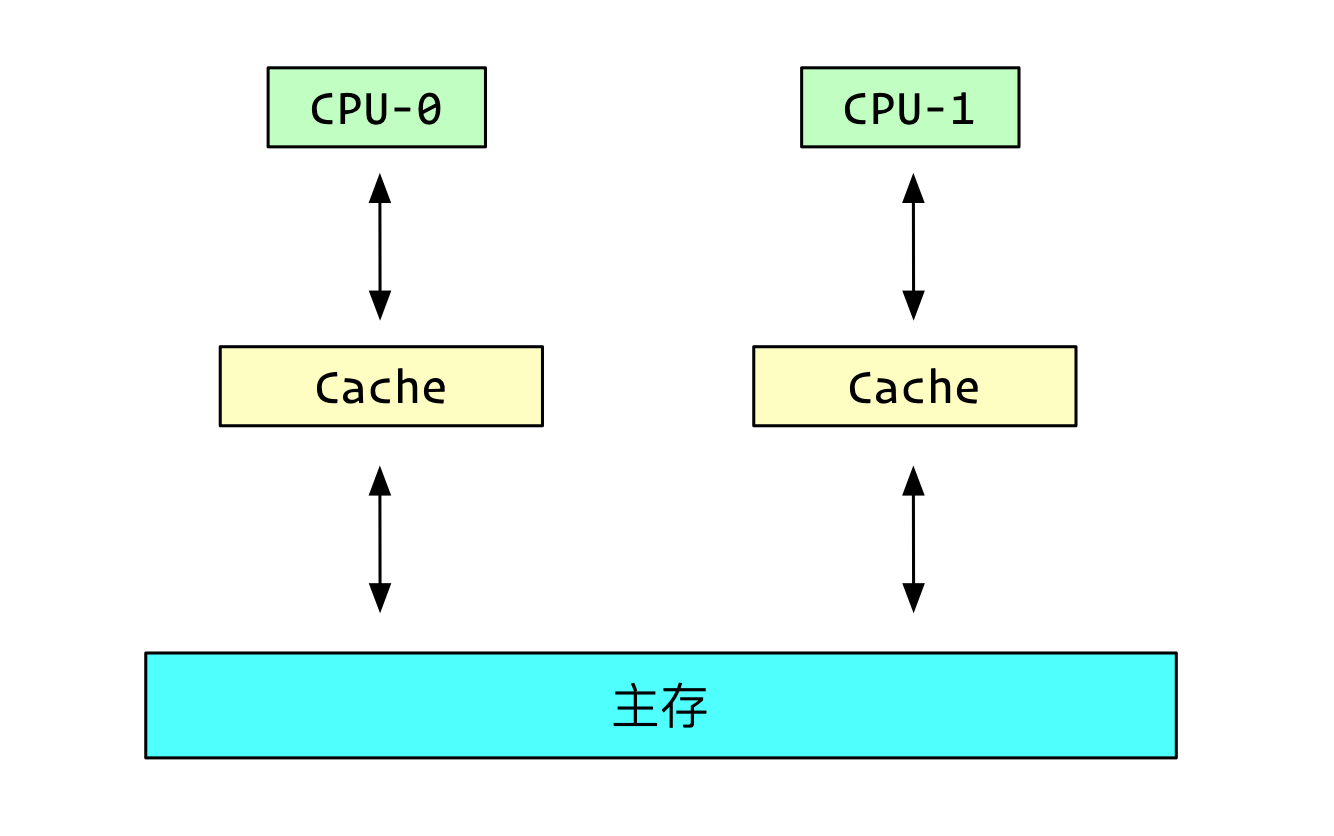
这就导致了一个问题。
我们知道Cache中的值其实是主存中的拷贝。
对一个值的修改先写到Cache中,再写到主存中,具体写入延迟不定。
对一个值的读取也是先从主存中读取到Cache中,CPU再从Cache中读取,什么时候失效也是不定。
多核的系统中,每个核心都有自己的Cache,并且是互相不可见的。
这就导致值的写入延迟和延迟失效都会导致数据不一致的问题。
怎么解决呢?
这个时候其实有个简单的方案:
- 每次写入Cache时,锁总线,同步再写入主存
- 每次读取值时,锁总线,从主存中读。
但是如果使用这种方案的话,那Cache基本就废了,毫无用处。
那怎么办呢?
那就让CPU的Cache“互相可见”吧。
于是MESI协议就诞生了。
MESI协议
MESI协议,是一种缓存一致性协议,顾名思义,就是解决各个核心的Cache之间,对于同一个值的一致性问题。
首先我们要知道,Cache其实是分块的,类似于磁盘的分页,Cache的每一块叫一个CacheLine,对于Cache的基本操作都是以CacheLine为基本单位。
MESI协议定义每个CacheLine有4种状态:
- Modified:表示这个CacheLine对应的主存数据,只在当前核心中,并且已经被当前核心修改过,和主存中不一样。
- Exclusive:该CacheLine对应的主存数据只在当前核心中,当前核心还未修改该CacheLine。
- Shared:该CacheLine对应的主存数据,也会在别的核心中,但是大家都不能修改,相当于只读。
- Invalid:协议未使用
同时定义了CPU之间可以互发的六种消息:
- Read:由某个cpu发出给其他的cpu和主存,包含要读的主存地址
- Read Response:由主存或者其他的cpu发出的对于Read的响应,收到响应后把CacheLine放入自己的核心缓存中
- Invalidate:请求中包含需要失效的数据地址,当收到Invalidate请求后,核心必须要删除这部分数据地址
- Invalidate Ack:当核心删除Invalidate请求的数据地址后,发送Ack给来源的CPU
- WriteBack:当CacheLine为Modify状态时,核心将该数据写回到主存时发出
说到这里你可以明白了MESI大致的作用:
当某个核心想要修改某个CacheLine的数据时,由于该CacheLine可能也在其他的核心中,所以必须要发消息给其他的核心,先移除对应的CacheLine。
同时,如果其他的核心有对应的CacheLine,必须先从自己的Cache中移除。以免自己读到已经被修改过的数据。
具体的操作流程有点复杂,估计读者也没耐心读完,这里就略过了。
想要详细了解的可以阅读本文的参考文章。
StoreBuffer和InvalidaQueue
有了MESI协议,Cache还是派的上用场,但是每次写入都得通知其他的核心,同时接收到其他核心的写入,还得把自己的那部分CacheLine失效。
必然会拖慢很多的性能。
比如说,当Core0想要修改a的值,但是发现a并不在CacheLine中,或者在CacheLine中,是Shared状态,这个时候他并不能直接修改a的值,他需要发消息给其他的Core, Invalidate这部分CacheLine,等所有的Core返回Ack的时候,他才能修改。
这部分时间cpu属于Stall状态。
那怎么办呢?
于是在写入Cache前,加入了一个Store Buffer。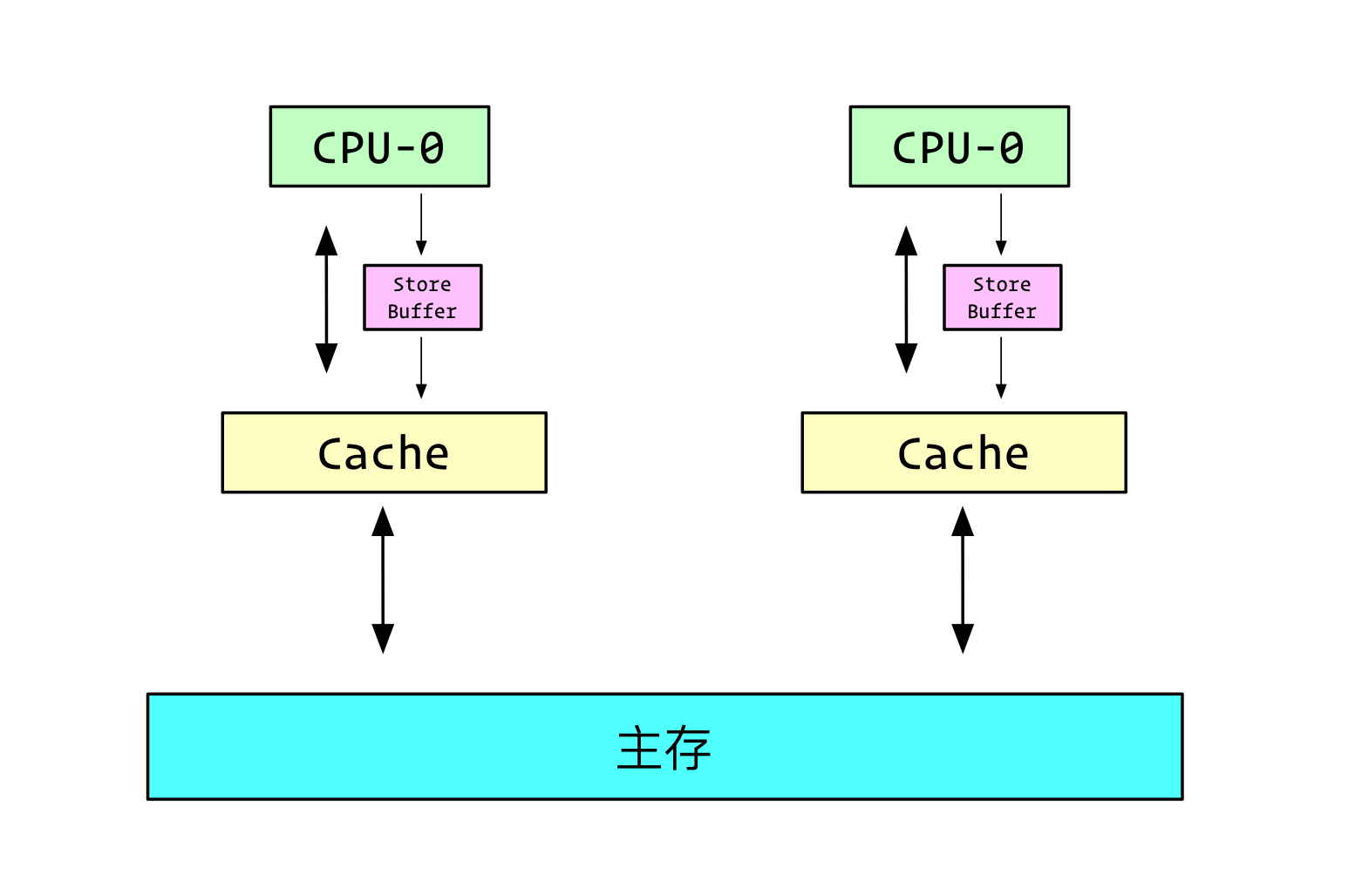
当需要写入一个值的时候,如果这个值的CacheLine并不在当前核心,或者该CacheLine并不是Modified或者Exclusive状态,先写入StoreBuffer,等其他的CPU的Ack到来时候,再择机把StoreBuffer中的值写入Cache。
同时,由于对该核心而言,一个值可能已经被修改了,但是并不在Cache中,而是在StoreBuffer中,所以读取的时候,以StoreBuffer的为准。
除了写入一个值时,需要进行等待,当收到Invalidate请求时,CPU也得放下手中的活,把CacheLine删除发送Ack才能继续。
这部分时间能不能缩减呢?
我们引入InvalidateQueue。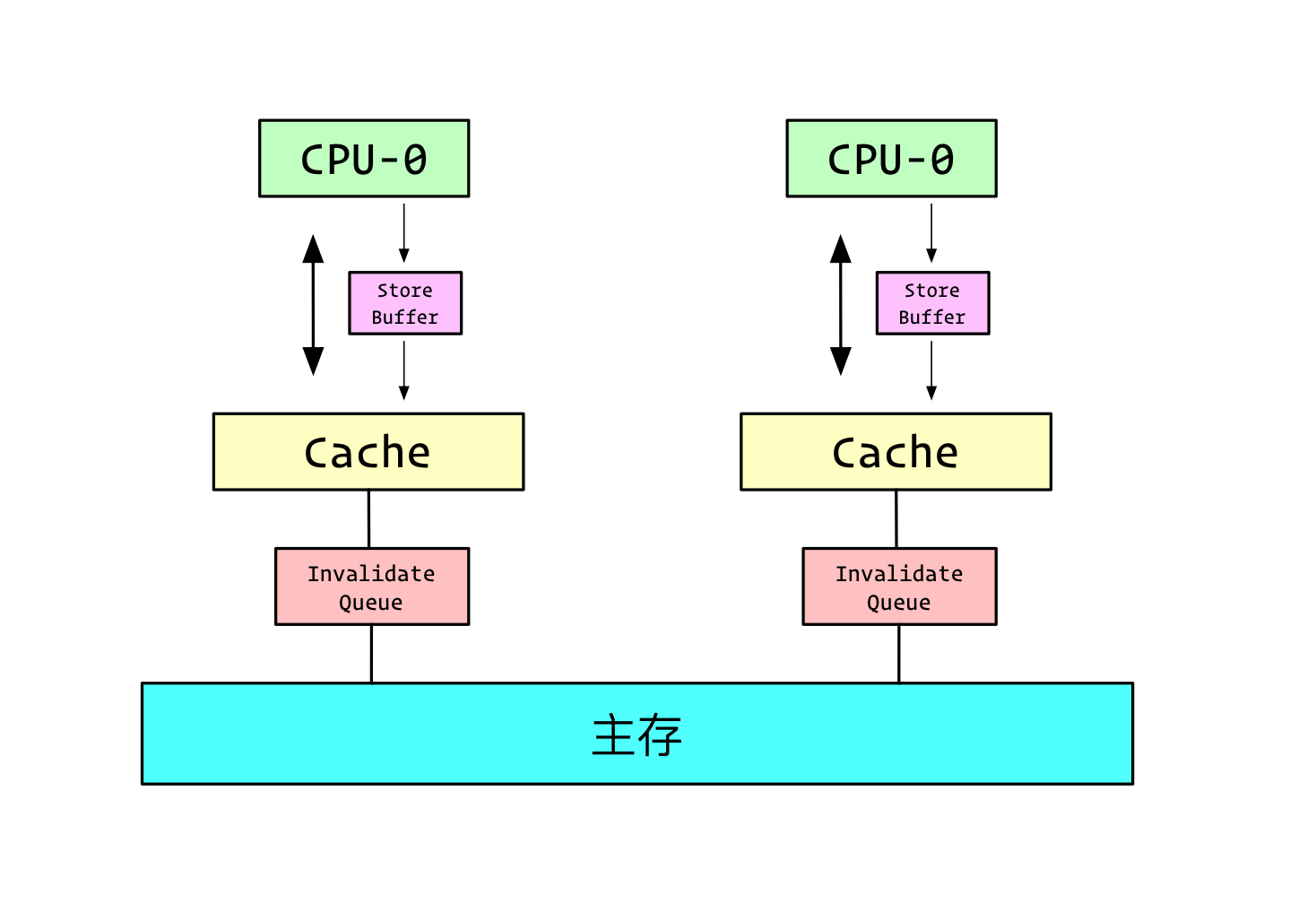
当接收到其他的Invalidate请求时,我们将请求放在InvalidateQueue中,并立马返回Ack。
再择机把InvalidateQueue中标志到的需要失效的CacheLine移除。
StoreBuffer导致的问题
我们首先看一段代码:1
2
3
4
5
6
7
8void foo(void) {
a=1; //S1
b=1; //S2
}
void bar(void) {
while (b == 0) continue; //L1
assert(a == 1); //L2
}
如果CPU0执行foo函数,CPU1执行bar函数。
同时a的值所在的CacheLine并不在CPU0中,b的值所在的CacheLine在CPU0中,并且是Exlusive状态。
- CPU0执行S1,发现a不在CacheLine中,发送Read Validate消息给主存和CPU1。同时把a=1的值放入StoreBuffer。
- CPU0执行S2,b值所在的CacheLine在CPU0中,并且是Exlusive状态,于是直接修改为1,放入CPU缓存。
- 这个时候CPU1启动运行bar函数,发现b不在CacheLine中,于是广播Read,获取b的值
- CPU0得到这个Read b的消息,把b的值发送回去
- CPU1得到b的值为1,L1通过
- CPU1执行L2,a在CacheLine中并且是0,assert fail
- CPU1得到第1步的Read Validate消息,把a所在的CacheLine移除。
步骤有点复杂,需要耐心阅读。
核心就是第1步的Read Validate消息,CPU1延迟到第7步才收到。
那怎么避免这种情况呢?
我们能不能让StoreBuffer退化到没有之前的流程?
也就是把第一步中的操作中,写入StoreBuffer后,不允许执行后续的操作,直到收到Validate Ack消息。
于是我们引入sfence()函数,遇到这个函数时,必须等到所有的Validate Ack,并且把StoreBuffer全部Flush到Cache,清空StoreBuffer。1
2
3
4
5
6
7
8
9void foo(void) {
a=1; //S1
sfence();
b=1; //S2
}
void bar(void) {
while (b == 0) continue; //L1
assert(a == 1); //L2
}
InvalidateQueue导致的问题
还是看这段代码:1
2
3
4
5
6
7
8
9void foo(void) {
a=1; //S1
sfence();
b=1; //S2
}
void bar(void) {
while (b == 0) continue; //L1
assert(a == 1); //L2
}
InvalidateQueue导致的就是,将CacheLine的移除时机变得不可确定。即使这个指示需要移除该CacheLine的Invalidate消息已经在InvalidateQueue中了,CPU还是会可能会从自己的Cache中读到旧的值。
比如例子中:
Core0执行foo函数,此时a在Core1中。
Core0发送Read Invalidate消息,Core1返回a的值,同时将Invalidate消息放入InvalidateQueue。
Core0将a=1推送到Cache中。
Core0执行b=1,放入缓存中。
Core1发送Read b的消息,Core0返回b=1;
L1执行成功,Core1获取a的值,由于移除该CacheLine的Invalidate消息还在InvalidateQueue中,所以发现a的值在Cache中,并且为0。
于是assert fail。
于是我们引入lfence()函数,该函数强制刷新InvalidateQueue。1
2
3
4
5
6
7
8
9
10void foo(void) {
a=1; //S1
sfence();
b=1; //S2
}
void bar(void) {
while (b == 0) continue; //L1
lfence();
assert(a == 1); //L2
}
总结
前文提到的sfence()和lfence(),便是内存屏障。
一个是写屏障,也就是同步刷新StoreBuffer
一个是读屏障,也就是同步刷新InvalidateQueue。
也有mfence(),既刷新StoreBuffer,也刷新InvalidateQueue。
