前言
Kafka延迟任务的实现
介绍
延迟任务的实现,一般是利用有序队列,按照执行时间的顺序排列,然后有个线程不断的去取第一个元素,如果到了需要执行的时间,就去执行。
伪代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Delay {
Queue<Comparable> taskQueue;
func add(Comparable task) {
taskQueue.add(task);
}
func pollAndRun() {
for (;;) {
var task = taskQueue.peek();
if (task.expireTime <= System.currentTime) {
run(taskQueue.poll());
} else {
Thread.sleep(task.expireTime - System.currentTime);
}
}
}
}
注意:这里的伪代码不完善,在add方法中,一般来说在某种情况下要interrupt执行pollAndRun的线程。
目前聚焦的主要问题是Queue是怎么个实现法。
在Java中有优先权队列可以进行排序,底层是基于最小堆做的,插入和删除的时间复杂度是O(logn)
当然正常情况下,这种实现可以了,Java中的标准实现也是这样。
但是呢,Kafka中有大量的低延迟的任务,如果都用最小堆去做,难免性能不太好
所以Kafka中实现了时间轮的算法,将插入和删除的时间复杂度降低到了O(1)。
下面细讲下实现:
数据结构
源码路径在:package kafka.utils.timer下。
TimerTask
Task是队列中的执行元素
1 | trait TimerTask extends Runnable { |
实现了Runnable接口,delayMs是指的需要被执行的时间戳,不是相对时间
TimerTaskList
看名字就知道是存储Task的集合类
但是其实它的定义并没有我开始想的那么简单
TimerTask在TimerTaskList内部的存储形式是双向链表
所以TimerTask其实被TimerTaskEntry的类包装了一层,增加了Prev和Next指针。
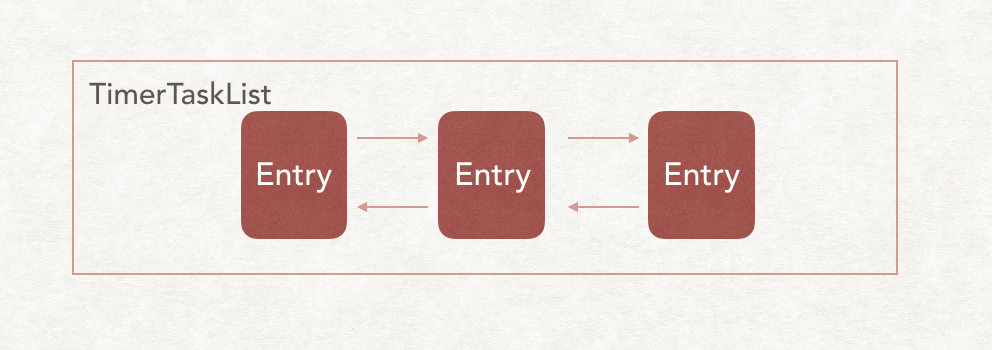
但是注意哦,这里虽然TimerTask实现了Comparable接口,但是TimerTaskList内部其实就是个简单的双向列表,并不会根据TimerTask的expireTime进行排序。
恰恰相反,TimerTaskList也实现了Comparable接口。
在TimerTaskList内部,有一个变量
1 | private[this] val expiration = new AtomicLong(-1L) |
从名字中看出其实是存放的是到期时间,TimerTask有过期时间我们可以理解,那么为什么TimerTaskList也有个过期时间?
这个过期时间是怎么定的,有什么用?
TimingWheel
来了,时间轮最主要的数据结构来了。
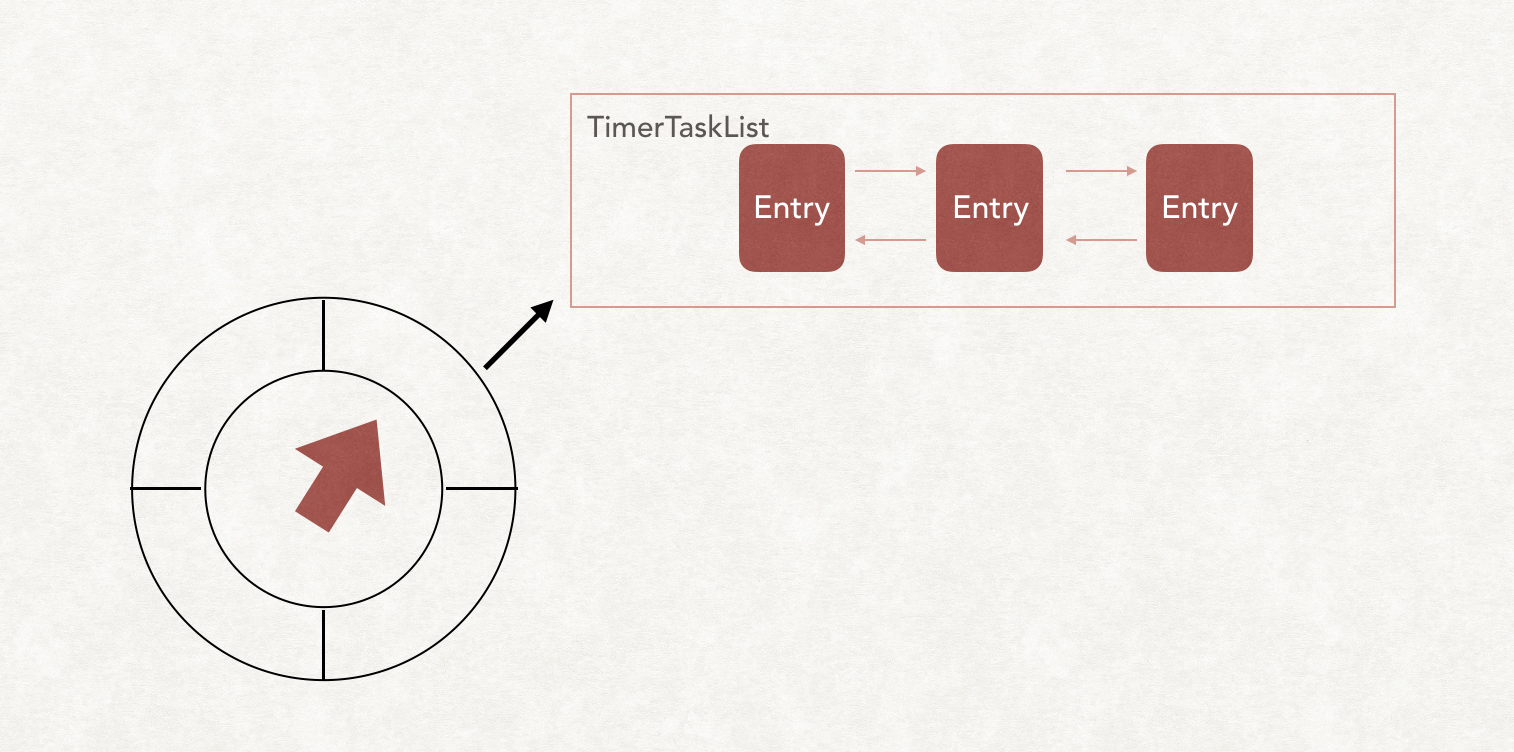
首先,看图中,模仿了一个钟表的运行图。
每tick一下,就把当前指针指向下一个格子。
其中每个格子对应着一个TimerTaskList
格子在Kafka中叫bucket1
val buckets = Array.tabulate[TimerTaskList](wheelSize) { _ => new TimerTaskList(taskCounter) }
每一格代表的时间叫TickMs,整个表最长的跨度叫Interval。
如果TickMs=5,Bucket=4,就表示这个时间轮有4个格子,总共能执行20ms内的延迟任务,同时TickMs也就是该时间轮保证的延迟任务的延迟执行的单位。
什么意思呢?就是说如果一个任务是2ms后执行,一个是4ms后执行,但是整个时间轮的TickMs是5ms,那么这两个任务在时间轮看来其实是没区别,是同时执行。
所以时间轮的TickMs最小,时间就越精确。
如果延迟时间超过了该时间轮的Interval怎么办?
比如执行50ms后才运行的任务,则需要建立跨度更大的时间轮。
而Kafka中会自动建立跨度更大的时间轮,叫overflowWheel,更大的时间轮的TickMs是下一层的Interval。
看到这里,其实可以解答TimerTaskList中的expiration有什么用了。
这里的expiration其实就是整个TimerTaskList的过期时间,是TickMs的整数倍
与在TimerTaskList中每个Task的具体延迟时间关系是
TimerTaskList.expiration <= Task.expiration <= TimerTaskList.expiration + TickMs
在Kafka中,默认的时间轮配置TickMs=1,Bucket=20,也就是20MS内的延迟任务。
运行
讲完了数据结构,下面需要讲怎么运行了。
TimingWheel的运行,交给了Timer来操作。
Timer有两个方法1
2
3
4//往时间轮中加入任务
def add(timerTask: TimerTask){}
//驱动时间轮向前Tick
def advanceClock(timeoutMs: Long){}
菜鸡的猜想方案
让我们暂时脱离源码,猜猜时间轮怎么运行的。
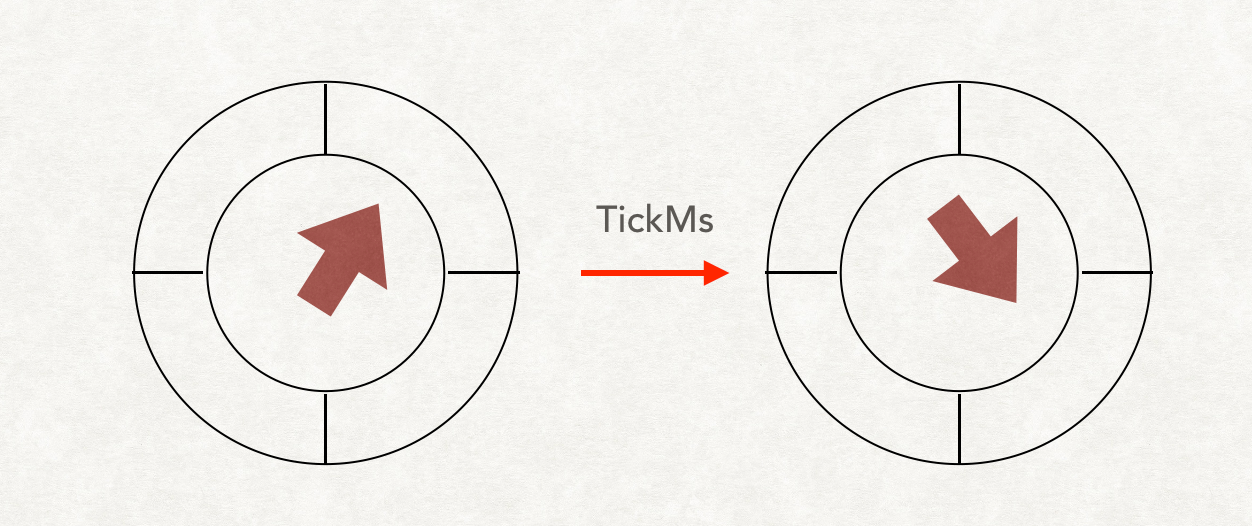
正常来说,我们把任务分到具体的Bucket中,每隔一个TickMs,将当前的指针向下运行一格。
找到这一格中的TimerTaskList,将里面的任务全部拿出来run一遍。
伪代码如下:
1 | List<TimerTaskList> buckets; |
在add元素的时候,先需要判断当前的时间轮是否能承载延迟时间,如果不能,则建立overflowWheel,加到overflowWheel中。
1 | List<TimerTaskList> buckets; |
看起来非常完美,但是问题来了,这个tick函数,怎么个运行策略呢?
如果要要跑的非常精确的话,必须要有个线程去单独驱动是肯定的,线程里还得这么跑
1 | //1 |
有方案1和方案2两种,第二种肯定是有问题的,如果出现了FullGC的情况,那么整个时间轮就不准了。
只能选择第一种方案,那么第一种肯定是不行的,这样CPU就是100%了,即使时间轮中没有任何任务,很多时间都是无用功,太浪费CPU了。
其实这里还有个很严重的问题,我们没有考虑overflowWheel。
正常情况下,在overflowWheel中的任务,如果已经到了下一层TimingWheel的interval范围内,是需要手动放到下一层的。
如果是这种实现的话,对于overflowWheel的处理会更加的复杂。
Kafka中的实现
菜鸡的猜想方案是不行的,面试都是直接挂的节奏。
所以这种思路是不成立的,那么我们能不能换个思路呢?
我们沿用最基本的最小堆来实现延迟任务的思路,建立一个优先权队列
但是队列中的元素不再是TimerTask了,而是TimerTaskList,相比较最原始的方案,队列中的元素少了一个数量级。
这样,每次单独的线程进行Tick的时候,选出最早需要执行的TimerTaskList,如果还没到执行时间,就可以进行Sleep,而不是占满CPU。
所以在TimingWheel中增加一个数据结构
1 | var queue = new PriorityQueue<TimerTaskList>() |
每次进行add时,除了把TaskEntry添加到TimerTaskEntry中,还将TimerTaskList添加到queue中。
这样线程的驱动函数就是这么写:
1 | func run() { |
虽然也使用了插入是O(logn)的最小堆结构,但是堆中元素不再是全量的Task了,而是TaskList,所以时间复杂度其实类似于O(1)了。
那么对于overflowWheel里面的Task怎么处理呢?
很简单,和第一层的timingWheel一样,将overFlowWheel中的TimerTaskList也加到queue中
但是从Queue取出的时候,就不是立即执行了,而是再走一遍add程序
下面是源码:
1 | //类似于源代码中nextBuckets的作用,这里是绝对时间,startMs是时间轮的开始的绝对时间,这里计算成tickMs的整数倍 |
timingWheel的advanceClock代码:
1 | def advanceClock(timeMs: Long): Unit = { |
主要就是调整下currentTime,其实currentTime在有了queue之后,就没有其他作用了,主要就是在add方法中拦住即将过期或者已经过期的任务
下面是伪代码中的run方法:
1 | def advanceClock(timeoutMs: Long): Boolean = { |
注意一下这里的delayQueue,其中poll方法返回的是过期的任务,并不是集合中第一个元素。
也就是说,即使queue中元素,但是没有元素要过期,返回的也是null。
当时作者在哪儿晕了半天。
