前言
作为写了好几年Java的人,自然想去深入了解一下JVM的构造,它的具体实现。
Clone了代码,运行了起来,看了《HotSpot实战》和《揭秘Java虚拟机-JVM设计原理与实现》,但是能力一般,水平有限,对JVM还是知之甚少,发现继续研究下去将是一种苦修,要做好看很久代码都毫无进展的准备。但是本人志不在此,还是想去研究分布式与数据库,精力有限,只有暂且放弃JVM的深入研究。
如此直接放弃还是有点可惜,虽然目前学到的不成体系,但是还是想写一篇Blog记录一下。
所以此博客是上文提到的两本书的摘要+自己的一些学习理解,内容会很散,同时为了省力,摘要部分不特别标出。
源码目录
HotSpot源码目录较多,有几个是比较重要的
- /c1 => 客户端解释器
- /classfile => Class文件解析
- /gc => gc相关
- /interpreter => C++解释器和模板解释器都在里面
- /oops => Java的类模型,也就是OOP-KLASS模型
- /opto => c2解释器,也就是服务端解释器
- /prims => 供外部程序访问JVM的通道,比如JNI,Perf,JMX等
- /runtime => 运行时模块,包括frame,thread,VMOptions等
- /shark => 基于LLVM实现的JIT编译器
源码
JMM开头的方法,和Memory没关系,指的是Management的意思
命令行选项
JRockit JVM中命令行选项分为三种
- 系统属性,-D开头
- 标准选项,-X,-Xms其实我觉得全拼是-X:memory-start?
- 非标准选项,-XX
Class文件解析
Class文件的解析的代码都在/classfile目录下

HotSpot构建了一个叫systemDictionary的字典,结构是[class name,class loader] -> class,用来存储系统中已经加载的类,从这个Map中我们可以看到一些类加载器的条件,双亲委派的概念。
在classFileParser.cpp中,宏定义了Class文件开头的MagicWord和Java_Version的对应关系1
2
3
4
5
6
7
8
9
10
11
文件解析后,各个Class文件是独立的,而各个类之间的联系其实是通过符号引用来串联在一起,JVM在进行符号引用的解析之后,就可以进行类型的相互引用和方法调用
JVM的链接分为三个部分:
- 验证:对方法进行一系列的检查,方法的访问控制,参数和静态类型检查等
- 准备:为类静态变量分配内存空间,但是不会初始化值
- 解析:将常量池中的4类符号引用转换为直接引用(用常量池项表示的字符串 -> 实际内存地址)
- 类
- 接口
- 字段
- 类方法和接口方法
链接完之后就是进行初始化,也就是调用static {}方法
对于方法的链接,运用的是链接解析器,LinkResolver对方法进行解析和查找
对一个方法进行解析时,需要对instanceKlass中的method表进行查找,找到目标方法后转换成MethodHandle类型句柄返回
对方法的权限检查(public,private这种)是在找到之后进行
runtime模块与Shutdown Hook
runtime模块主要定义HotSpot运行时数据
frame.hpp定义了栈帧的结构,包括Java栈帧,C栈帧。
destroy_vm的退出流程中,会运行JVM层的关闭钩子函数。
这里的关闭钩子函数就是提到的Runtime.getRuntime().addShutdownHook();
书中提到的File.deleteOnExit方法,也是调用的这个,但是获取方式看起来不太一样1
2
3
4
5
6
7
8sun.misc.SharedSecrets.getJavaLangAccess()
.registerShutdownHook(2 /* Shutdown hook invocation order */,
true /* register even if shutdown in progress */,
new Runnable() {
public void run() {
runHooks();
}
}
而且参数也是不止一个,看起来还可以指定顺序
但是不管咋样,最后两种方式其实都是调用的Shutdown.add方法
Runtime中的调用1
2
3
4
5
6
7
8Shutdown.add(1 /* shutdown hook invocation order */,
false /* not registered if shutdown in progress */,
new Runnable() {
public void run() {
runHooks();
}
}
);
看Order的参数来说的话,其实Runtime的优先级更高,而File.deleteOnExit的优先级第二。
synchronized实现
synchronized方法或者代码块,会生成两个特殊的字节码
- monitorenter
- monitorexit
对于解释器而言,具体的执行逻辑在intercepter/bytecodeIntercepter.cpp 1803行 JDK9
也就是CASE(_monitorenter)中
具体的实现分为偏向锁,轻量级锁,重量级锁
最后会调用InterpreterRuntime::monitorenter方法,这个方法定义在interpreter/interpreterRuntime.cpp中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
...
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
...
仔细看会使用到ObjectSynchronizer的两个方法,如果使用了偏向锁,那么就是fast_enter,如果不允许偏向锁,那么就是slow_enter
在slow_enter的最后,如果还是不行,就会进入锁膨胀的状态,也就是重量级锁
1 | ObjectSynchronizer::inflate(THREAD, |
这个时候就要用到ObjectMonitor类中的方法,最后还会涉及到ObjectWaiter类,这个类就是设计了一个链表,类似于ReententLock中的等待链表。
最后还是很好奇最终的互斥锁到底是怎么实现的,代码在runtime/mutex.cpp中,仔细看了一下,并没有使用到c语言中的Mutex库,最终还是依赖于CAS实现的。
其实说到底,最后所有的锁都是基于CAS + 链表。
这里有一个概念上的观念,就是https://stackoverflow.com/questions/1898374/does-the-jvm-create-a-mutex-for-every-object-in-order-to-implement-the-synchron该问题中提到的
Ask: Using only CAS instructions, how do you get the OS scheduler to put a thread to sleep?
Answer: you don’t. You only use CAS to acquire / release the lock in the uninflated / uncontended case. If contention is detected, the locking/unlocking code would then do the relevant thread scheduling syscalls … or whatever.
如果你查看ReentrentLock的最后将等待的线程放入等待链表中,对线程调用的是LockSupport.park()方法,这是一个native方法,要去源码中找实现,在hotspot/src/os/linux/vm/os_linux.cpp中,可以看到这里为了让线程能够进入os的调度,也就是放弃CPU资源,还是需要进行pthread_cond_wait的调用的。最后对线程的唤醒,还是需要进行notify的。
在synchronized的底层实现中,最后也是进行park,调用的是os::PlatformEvent::park方法,使用的类是
class ParkEvent : public os::PlatformEvent
所以,(CAS+链表+pthread_mutex)才是真正的实现机制。
而如果是多线程争用的情况,其实最终的目的还是要保证原子释放CPU资源。
说了一堆,其实核心在锁的实现上,基本都放弃了直接使用pthread_mutex的方法,而是运用CAS的方式进行自旋,而pthread_mutex的使用仅仅是为了将线程进行操作系统的重新调度。
参考文章:
偏向锁
这个名词看名字不是那么容易理解,在JRockit中描述为延迟解锁
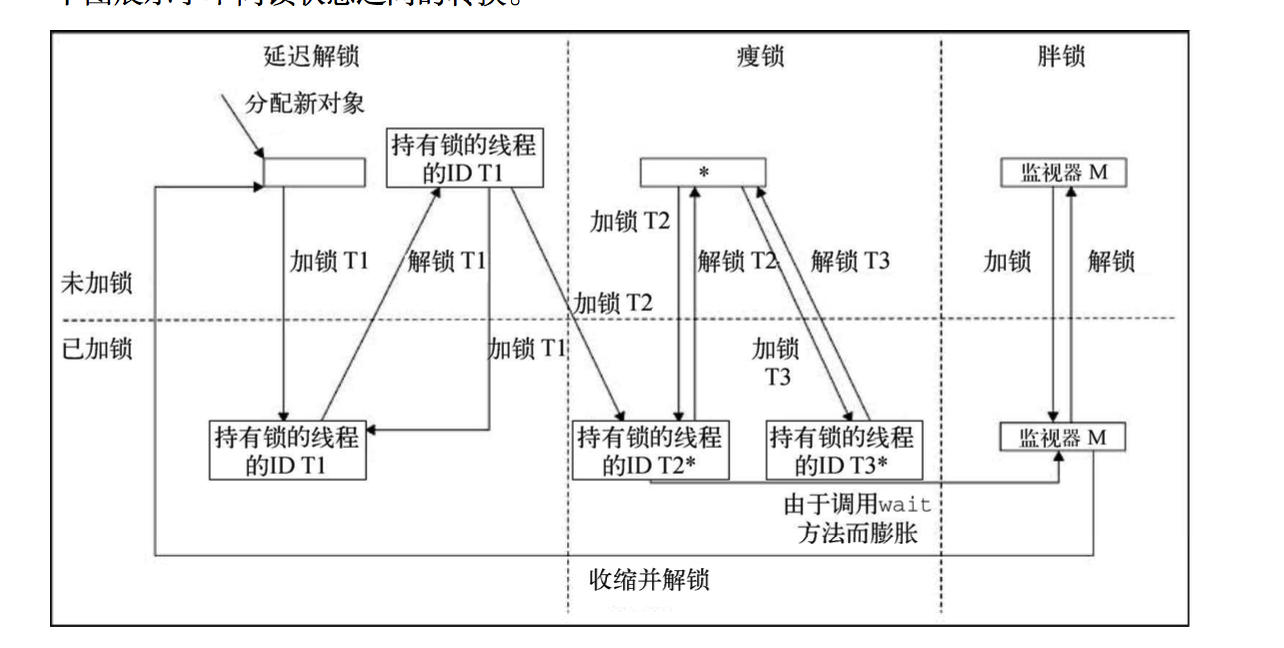
在上图中,有三种锁类型,其中胖锁和瘦锁在之前中介绍过,这里新增了延迟锁,用来解释 锁在大部分情况下都只作用于线程局部场景下的情况。
正如之前介绍过的,对象首先是未加锁状态的,然后线程 T1 执行 monitorenter 指令,使 之进入延迟加锁状态。但如果线程 T1 在该对象上执行了 monitorexit 指令,这时系统会假装 已经解锁了,但实际上仍是锁定状态,锁对象的锁字中仍记录着线程 T1 的线程 ID。在此之后, 线程 T1 如果再执行加锁操作,就不用再执行相关操作了。
如果另一个线程 T2 试图获取同一个锁,则之前所做“该锁绝大部分被线 T1 程使用”的假 设不再成立,会受到性能惩罚,将锁字中的线程 ID 由线程 T1 的 ID 替换为线程 T2 的。如果这 种情况经常出现,那么可能会禁用该对象作为延迟锁,并将该对象作为普通的瘦锁使用。假设这 是线程 T2 第一次在该对象上调用 monitorenter 指令,则程序会进入瘦锁控制流程。在上图中, 被禁用于延迟解锁的对象用星号(*)做了标记。此时,当线程 T3 试图在某个已被禁用于延迟解 锁的对象上加锁,如果该对象还未被锁定,则此时仍会使用瘦锁。
使用瘦锁时,如果竞争激烈,或者在锁对象上调用了 wait 方法或 notify 方法,则瘦锁会 膨胀为胖锁,需要等待队列来处理。从图中可以看到,处于延迟解锁状态的对象直接调用 wait 方法或 notify 方法的话,也会膨胀为胖锁
单例模式的双重校验锁的实现其实是有问题的,加了volatile能解决问题,但是会带来略微的性能问题
内存 OOP
虚拟机中内存空间按照内存的用途,可以划分为堆和非堆
- 堆:用于对象的分配空间
- 非堆:包括方法区和Code Cache
Perf Data区域,有perfMemory模块管理
为了支持虚拟机性能监控,在虚拟机中开辟了一块共享内存,专门存储一些性能指标
虚拟机使用共享内存方式向外部进程提供了一种通信手段,允许外部监控进程attach至虚拟机进程,从共享内存中读取这些perf Data
oop-klass模型
这个感觉是比较重要的点了
还是一个老生长谈的问题,why的问题
运用C++的基础模型去实现有没有问题呢?
其实我感觉是没有问题的,但是相对于C++的模型,Java这种方式,其实主要是更省内存。
同一个类的所有对象维护同一个VTable,其次就是和C++的多态方式不同,Java是模型每一个函数都是可以被子类覆盖的,而C++的只有是虚函数才能,换句话说,Java里面每个函数都是虚函数。
虚函数暴增的情况下,显然这种方式更加的省内存。
//fixMe
而且我感觉还和Java的类加载机制有关,因为Java的符号引用转换为直接引用的解析过程,是可以再运行中才进行的,如果父类的方法被动态改变了,函数的地址肯定也需要进行相应的改变,而现有子类的对于这个方法的指向,只要改变一次Klass就行。
在该模型中,Java的method也作为一种OOP存在
实例对象的创建 分为快速分配和慢速分配
- 快速分配就是必须是该类已经被加载和正确解析 因为类的解析,就是符号引用变直接引用的过程不一定就是ClassLoader的时候进行,HotSpot是类第一次被使用的时候解析
快速分配就是可以在TLAB,就是线程缓存中分配,而不必先分配到Eden区,如果开启了TLAB选项 - 慢速分配就是需要先解析,然后在Eden区分配
对象在内存中的布局,也就是OOP对象,可以分为连续的两部分,也就是MarkWord对象头和实例数据部分
而在Klass模型中,存储着对象的每个变量在实例数据部分的偏移量和长度
Klass中,有一个和Java类对应的mirror成员
JVM为每个线程分配一个PC寄存器,在真实机器中,往往提供一个PC寄存器专门用来保存程序运行的指令在内存中的位置,在HotSpot的实现中,为每个线程分配了一个字长的存储空间,以实现类似硬件级的PC寄存器
如果当前执行方法不是本地方法,那么PC寄存器就保存的是JVM正在执行的字节码指令的地址,如果是本地方法,那么PC寄存器的值是未定义的,因为本地方法的执行依赖硬件PC寄存器,其值是由操作系统维护
Java虚拟机栈的作用:存储方法执行中的局部变量,中间演算结果以及方法返回结果
JVM允许Java虚拟机栈被实现为固定大小和动态收缩
固定大小,顾名思义,如果超过,抛出StackOverflowError异常
动态扩展:OOM异常
虚拟机规范对方法区实现的位置并没有明确要求,在HotSpot中,位于永久代中。
HotSpot会收集方法区,主要是常量池的收集和类的卸载
在HotSpot内部,Java方法也是由一个内部对象表示的,对象的类型是methodOop,是Java方法在JVM内部的表示方式
methodOop内部有指向所在类的运行时常量池的指针
methodOop内部有个_constMethod指针,类型是constMethodOop,用来存储和定位方法中的只读数据,如字节码,方法引用,方法名,方法签名,异常表等信息
Perf Data区域,有perfMemory模块管理
为了支持虚拟机性能监控,在虚拟机中开辟了一块共享内存,专门存储一些性能指标
虚拟机使用共享内存方式向外部进程提供了一种通信手段,允许外部监控进程attach至虚拟机进程,从共享内存中读取这些perf Data
Java类的生命周期的第一个阶段,加载,就是为了在JVM内部创建一个与Java类结构对等的数据对象
如果想要破坏双亲委派的机制,自定义类加载器加载核心类库,还是会被拒绝,因为在defineClass方法中,会提供保护,对类名为Java开头的类,直接抛出异常
同样的,类型转换需要两个类都是同一个类加载器加载的,不然会报错,上次那个Dubbo的问题就这样,报错是两个一样的类,无法进行cast
GC
GC的几个策略
- GC工作线程:串行还是并行
- GC工作线程和应用线程:并发执行还是暂停应用
- 基本收集算法:压缩,非压缩还是拷贝
吞吐量:应用程序运行时间/(应用程序运行时间 + 垃圾收集时间)
HotSpot每个线程在Eden区都有自己的一小块区域,用于TLAB分配
通常情况下,系统中有大量连续的内存块可以用来进行分配的话,碰撞指针算法进行分配,效率很高。思路就是记录上一次分配对象的位置,当有新对象要分配的时候,只需要一次移动位置就可以完成内存的分配
在TLAB中进行分配,也就是碰撞指针(bump-the-pointer)分配,效率很高
不然就需要全局锁进行在Eden区分配
还有另外一种优化,叫栈上分配
栈上分配需要对方法的对象进行逃逸分析
如果局部变量的作用域仅限于方法内部,则JVM直接在栈帧内分配对象,避免在堆中分配
但是这里引用R大的话
嗯但是Oracle/Sun的HotSpot VM从来没在产品里实现过栈上分配,而只实现过它的一种特殊形式——标量替换(scalar replacement)。这俩是不一样的喔。栈上分配还是要分配完整的对象结构,只不过是在栈帧里而不在GC堆里分配;标量替换则不分配完整的对象,直接把对象的字段打散看作方法的局部变量,也就是说标量替换后就没有对象头了,也不需要把该对象的字段打包为一个整体。
https://book.douban.com/people/RednaxelaFX/annotation/25847620/
有个类叫GCCause,里面定义了一些枚举,就是引起GC的一些情况1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43enum Cause {
/* public */
_java_lang_system_gc,
_full_gc_alot,
_scavenge_alot,
_allocation_profiler,
_jvmti_force_gc,
_gc_locker,
_heap_inspection,
_heap_dump,
_wb_young_gc,
_wb_conc_mark,
_wb_full_gc,
_update_allocation_context_stats_inc,
_update_allocation_context_stats_full,
/* implementation independent, but reserved for GC use */
_no_gc,
_no_cause_specified,
_allocation_failure,
/* implementation specific */
_tenured_generation_full,
_metadata_GC_threshold,
_metadata_GC_clear_soft_refs,
_cms_generation_full,
_cms_initial_mark,
_cms_final_remark,
_cms_concurrent_mark,
_old_generation_expanded_on_last_scavenge,
_old_generation_too_full_to_scavenge,
_adaptive_size_policy,
_g1_inc_collection_pause,
_g1_humongous_allocation,
_dcmd_gc_run,
_last_gc_cause
};
收集算法
- 标记-清除 Mark-Sweep
- 复制算法 Copying
- 标记-压缩算法 Mark-Compact
堆的类型
不同的收集器可能对应着不同类型的堆
CollectedHeap <- ParallelScavengeHeap
CollectedHeap <- SharedHeap <- G1CollectedHeap
CMS的创新之处在于把标记分为两个阶段,初始标记和并发标记
但是引入了新的缺点,就是并发收集失败的问题,在并发标记时,内存使用过度,只有STW,采取线性标记和收集
而且只能由于并发清除的问题,只能进行标记-清除,将产生内存碎片,而新生代由于其特殊性,将产生更多的内存碎片,所以CMS在新生代并不适用,只运用在老年代
安全点
由于JVM系统运行期间的复杂性,不可能做到随时暂停,因此引入了安全点(safepoint):程序只有在运行到安全点的时候,才准暂停下来。HotSpot采取主动中断的方式,让执行线程在运行时轮询是否需要暂停的标识,若需要则中断挂起。
//fixme
其实我觉得这里说的不对,应该不是不可能做到随时暂停,而是随时暂停的消耗太大了,因为后面也写到是主动中断的方式,如果在每个字节码后面都插入check是否需要中断的代码,则消耗确实是太大了
参考文章:https://www.jianshu.com/p/c79c5e02ebe6
G1收集器
G1重新定义了堆空间,打破了原有的分代模型,将堆划分为一个个区域
在进行收集的时候,不必在全堆的范围内进行,好吃就是带来了停顿时间的可预测
G1会通过一个合理的计算模型,计算出每个region的收集成本并量化
分代模型的写屏障
这个是比较重要的一个,一开始是比较难理解的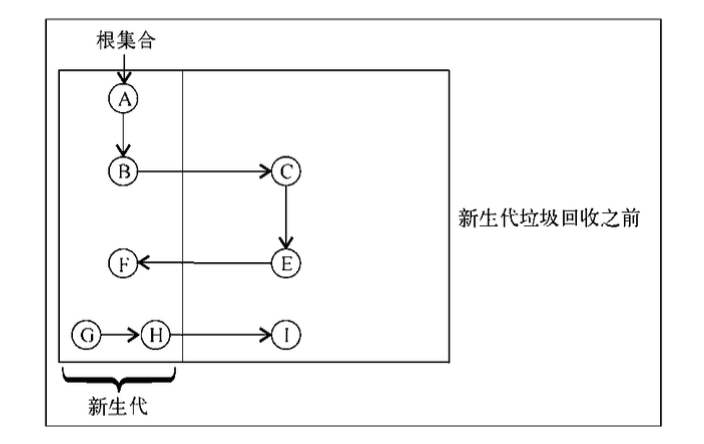
我们从正常的新生代的GC开始说,从图中看到,如果只从GCRoot出发,其实是扫描不到F的,如果扫描不到,说明F是需要被清除的
但是其实F被老年代的E所引用,也就是说他不能被清除
这就是说,GCRoot需要包含新生代中的被老年代引用的对象。
但是如果要实现这个功能,可能要扫描所有的老年代对象了,如果每次进行新生代的GC时都扫描老年代,那么分代GC的意义就不是那么明显了
所以这里用了一个写屏障,底层使用的是卡表的概念进行标记。
简单的说就是每当有老年代对象引用新生代对象时,就把老年代对象所在的位置标记一下,然后进行新生代GC时,把老年代标记了的位置进行扫描进行,而不用全部扫描
https://juejin.im/post/5c39920b6fb9a049e82bbf94
压缩指针
指针的大小一般是平台的决定的,但是在64位的机器上,但是还是可以进行一些优化,优化的基础是内存的申请是一下子一大片连续的内存
举个例子就是在64位机器上,如果我们要申请的一块内存小于4G,那么完全可以只用32位就可以进行指针的保存
JRockit里面提到了一种伪优化
就是对象池,有人认为,保留一个存活对象池来重新使用已创建的对象可以提升垃圾回收的性能
但实际上,对象池不仅增加了应用程序的复杂度,还很容易出错。对于现代垃圾收集器来说,使用 java.lang. ref.Reference 系列类实现缓存,或者直接将无用对象的引用置为 null 就好了,不用多操心。
此外,长期持有无用的对象其实是个大麻烦,分代式垃圾回收器可以很好地处理临时对象,但如果这些临时对象被人为保存下来,无法被回收掉的话,最终就会被提升到老年代,并将其挤满。
栈帧
如果函数要返回整数或者指针的话,寄存器%eax可以用来返回值
寄存器eax,edx,ecx被划分为调用者保存
而寄存器ebx,esi,edi寄存器划分为被调用者保存
栈是以帧为单位保存当前线程的运行状态
当线程执行一个方法时,它会跟踪当前常量池
栈帧存储了方法的局部变量表,操作数栈,动态链接和方法返回地址
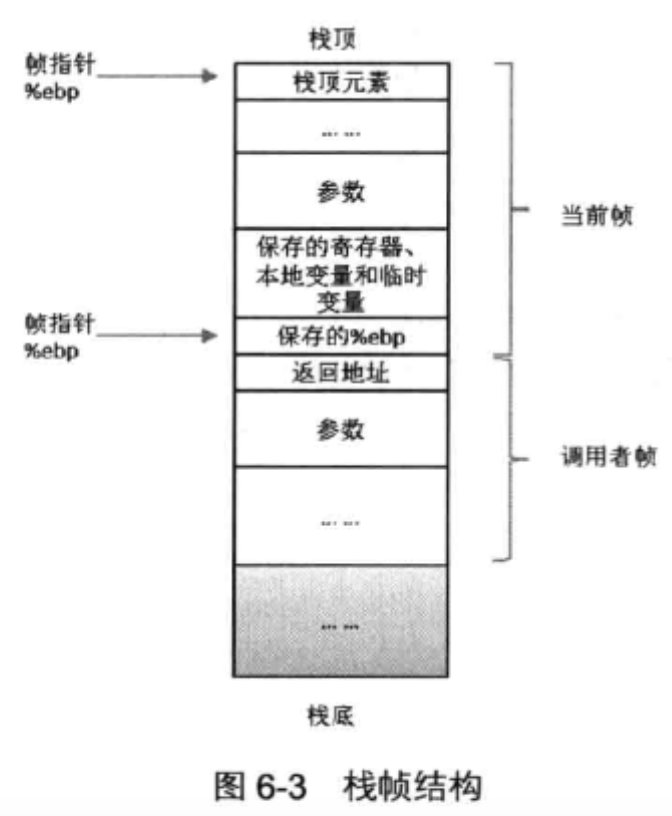
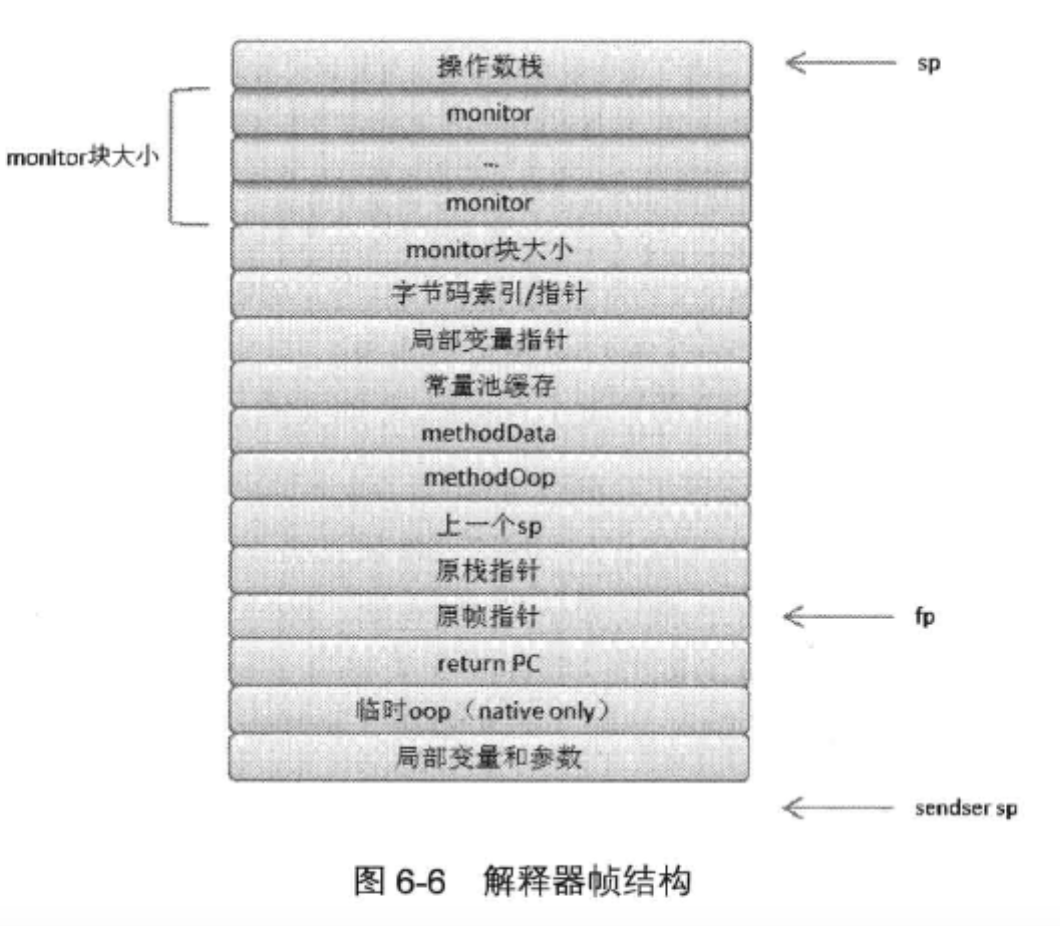
局部变量表
- 局部变量表被组织为一个字长为单位,从0开始计数的数组
- 存储时以slot为单位,一个slot一般为32位,short,byte,char在存入表中要先转换为int
- 一般会存储的类型除了基本类型和引用,还有returnAddress类型,它指向了一个字节码指令的地址
- 参数值到参数变量列表的传递依赖于局部变量表
- 第0位索引的slot默认是用于传递方法所属对象实例的引用
局部变量表的描述
- start_pc,length:描述局部变量的作用域
- name_index:描述局部变量名的常量池索引,对应Class文件中的Name
- descriptor_index:描述局部变量类型的常量池索引,对应Class文件中的Signature
- index:描述局部变量在当前栈帧的局部变量索引
局部变量表的大小在编译期就可以确定,在Code属性中明确了大小
操作数栈
- 操作数栈的深度由Code属性max_stacks在编译期确定
- 和局部变量表不同的是,操作数栈不是通过索引来访问的,而是通过入栈和出栈来访问
- 还有一个比较重要的点,就是操作数栈和下一个栈帧的参数列表是可以复用的,不然我们在HSDB调试操作数栈的时候看起来会比较迷惑
异常表
为了处理Java方法中的异常情况,帧数据区还必须保存一个对此方法异常表的引用,当异常抛出时,JVM给catch块中的代码
如果没发现,方法立即终止,然后JVM用帧区数据的信息回复发起调用的方法的帧,然后再发起调用方法的上下文重新抛出同样的异常
Hotspot解释器执行引擎在执行字节码时,实际上是执行一段已经被编译成本地机器直接运行的指令
在JVM启动期间,解释器模块就会将每个字节码转换成与之等价的机器指令,放在Code Cache中
所以HotSpot充分利用了计算机的资源,包括寄存器
JavaCalls
JavaCalls,说白了就是JVM调用Java方法
然后CallStub,是一个函数指针,在调用Java程序的Main函数时,需要使用这个函数指针
但是CallStub指向的函数是一个entry_point,是一个例程
当然这里其实是有歧义的例程在JVM的概念就是提前用机器码写好的函数,而entry_point虽然也是例程,然后它主要突出entry这个词,主要是在方法调用切换时进行调用的例程
再说回CallStub,它指向的例程,就是为所有Java程序的唯一一个Main方法构造他的前一个栈帧
1 | public static void main(String[] args) {} |
最直接的就是参数args,在栈中需要使用CallStub指向的例程构建好,然后CallStub的函数指针的函数中,还需要传入一个entry_point,这个就是在进行Java函数调用的时候,需要进行寄存器的保存等之类的操作,而这些操作由不同的entry_point来操作。
//fix me
个人理解就是在各种invoke的字节码指令中,会频繁的调用这些不同的entry_point。
常量池
其实JVM中常量池有两种不同的概念
第一种是Class文件的常量池
虚拟机在创建一个类或者接口时候,按照Class文件的定义创建相应的常量池,也就是Class文件中的constant_pool表。
第二种是方法区中的常量池,虚拟机在对类进行解析和连接之后,将在内存中为该类生成一套运行时常量池,常量池在运行时动态分配
第三种是代码中我们提到的常量池,也就是String常量池,JVM中创建了一个String的Table
参考https://blog.csdn.net/zm13007310400/article/details/77534349
那么为什么要有常量池呢
Answer:
常量池的出现,解决了JVM定位字段和方法的问题,它在不破坏指令集的简洁性的前提下,仅仅通过少量字节就能定位到目标。
更详细的说,以字符串数据aVeryLongFunctionName为例,如果在编译时每次都要重新避免这个字符串的话,那么字节码就谈不上压缩了
但是每次字段或者方法的访问都需要解析常量池项的话,将不可避免的造成性能下降
对于类文件的运行时常量池,JVM内还会有它的高速缓冲ConstantPoolCache
解释器
HotSpot的解释器分为了两种
一种是CPP解释器,也就是最原始的解释器,类似于Case,Case这种形式,文件是intercepter/bytecodeIntercepter.cpp
一种是模板解释器,现在默认是这样,这种是在JVM启动时对每一个字节码都进行了当前平台的机器码转换,具体的是维护了一个平台相关TemplateTable,可以在cpu/x86/vm中的templateTable_XX.cpp中找到,相对于CPP解释器,其实这也是一种解释的方法,虽然第一种最终执行的也是C++编译成的机器码,但是模板解释器相对于CPP解释器,机器码是手动写的,可以进行一些优化,比如TOS,还有就是对于取出下一个执行进行运行,也可以直接插入到当前字节码的机器码中
对于模板解释器的取指令的操作,其实在写在每一个字节码指令的最后。
HotSpot在为每一个字节码指令生成其机器逻辑指令时,会同时为该字节码指令生成其取址逻辑
PC计数器,在x86平台上就是esi寄存器,所以在JVM中并不是完全不使用CPU的寄存器
面向栈式的指令,可以省去很多的操作数,所以一定程度上也减少了代码体积
这话其实不对,因为相对于寄存器式的指令,寄存器式的一个指令就能完成的事,其实栈式需要多个指令
栈帧重叠
就是前面提到的上一个方法的操作数栈可以直接成为下一个方法的参数表
栈上替换 OSR
个人理解就是在一个方法里遇到了Loop非常久的情况,对方法进行了JIT编译,但是由于这个Loop非常长,JIT编译完还未结束,所以为了将当前方法替换到新的栈帧,使用栈上替换
具体的解释在R大这儿
OSR(On-Stack Replacement)是怎样的机制?
JRockit没有实现OSR,因为太复杂了
JIT编译器
为什么不直接全部aot编译一下,而是选择了解释+JIT的方式
R大这里也回答了[https://www.zhihu.com/question/37389356)(https://www.zhihu.com/question/37389356)
我总结一下
- 时间开销,aot的启动时间肯定很慢
- 空间开销,字节码到机器码会代码膨胀
- 编译时机,一些profile的收集对编译有很大的影响
JIT是一个充满希望的方向,因为它可以搜集到程序在AOT编译时得不到的runtime数据,在优化时,有更多的上下文可以依靠,理论上应该有更好的优化特性
在JRockit中,讲了aot其实在90年代就已经出现了,但是这种方式虽然快了很多,但是抛弃了很多Java的动态特性,提到了一个很重要的场景,就是在JSP的应用中,我们知道JSP其实就是b被编译成class文件,做的事也仅仅是疯狂的sout,如果aot一下,效率不会提高太多,但是代码体积会提高很多
其实aot与全部JIT编译并不是一个概念,一个好的办法是,给JIT的编译加上不同层级的编译,一开始可能是优化不高的,后面收集到profile后再进行深层次的profile
判断热方法
- counter,但是会降低效率
- 基于软件的线程采样,周期性的获取活动线程的上下文
JVM字节码的表现力其实比Java语言强,所以需要对字节码进行校验,防止一些恶意的技巧
TOS
TosState的取值范围为0-8,共计9种
- byte,bool
- char
- short
- int
- long
- float
- double
- object
- void
最后一种其实就是空,参见R大的笔记,HotSpot实战中写的是tos类型,我还去百度了tos类型是啥类型😓
VM选项
| 配置 | 解释 | 备注 |
|---|---|---|
| -XX:UseG1GC | 配置G1收集器 | |
| -Xint | 配置虚拟机以纯解释方式运行 | |
| -XX:+MaxFDLimit | 最大文件描述符数量 | |
| -XX:DisableExplicitGC | Parallel Scanvenge收集器的配置,屏蔽System.gc() |
Tools
实际的性能分析可以查看《HotSpot实战》的5.3小节,讲的很详细
- HSDB:可以用来看JVM的运行时数据,查看线程栈,对象的数据
- jps:查看Java进程信息
- jinfo:
- jmap:
- jhat:
- jstat:
- jstack:
参考
RednaxelaFX对《HotSpot实战》的笔记
HotSpot实战
JRockit权威指南:深入理解JVM
https://book.douban.com/subject/27086821/
