论文名字:Eliminating Synchronization-Related Atomic Operations with Biased Locking and Bulk Rebiasing
Bulk Rebiasing,查了一些博客,一般叫做批量重偏向
总结
- 偏向锁撤销,这里的意思是升级的意思。而重偏向,就把锁对象重置为可偏向的状态。
- 正常的博客中,对于HotSpot,其实没有提过重偏向,只有偏向锁撤销,升级为轻量级锁。
- 在一些对象中,使用重偏向是很有价值的。同样的,在一些对象中,禁用偏向锁是很有价值的。
- 这个论文介绍了一些方法,启发式的对一些对象禁用偏向锁,或者启用重偏向。
- 监测对象分配地点或者监测某一类class的对象
- 计算成本,超过阈值就禁用偏向,同时对所有class的对象禁用偏向
- 对批量重偏向和撤销的实现,论文中也提供了两种实现。基于Epoch的实现还是比较巧妙的。
对于HotSpot中的批量重偏向和批量撤销,可以看看这篇文章:
https://segmentfault.com/a/1190000023665056
摘要
The Java programming language contains built-in synchronization primitives for use in constructing multithreaded programs. Efficient implementation of these synchronization primitives is necessary in order to achieve high performance.
Java 语言内置了一些同步原语,用于构建多线程程序。为了达到高性能的目的,必须高效地实现这些同步原语。
Recent research has focused on the runtime elimination of the atomic operations required to implement object monitor synchronization primitives. This paper describes a novel technique called store-free biased locking which eliminates all synchronization-related atomic operations on uncontended object monitors. The technique supports the bulk transfer of object ownership from one thread to another, and the selective disabling of the optimization where unprofitable, using epoch-based bulk rebiasing and revocation. It has been implemented in the production version of the Java HotSpot VM and has yielded signification performance improvements on a range of benchmarks and applications. The technique is applicable to any virtual machine-based programming language implementation with mostly block-structured locking primitives.
最近的研究都集中在如何在运行时消除一些原子操作,这些原子操作用来实现对象监视器的同步原语。
本论文讲解了一个叫做无需占用存储的偏向锁的新技术,该技术消除了在无竞争的对象监视器上的所有与同步相关的原子操作。
该技术支持将对象所有权从一个线程批量转移到另一个线程,并在使用偏向锁不会产生性能提升的情况下,使用基于epoch的批量重偏向和批量撤销,选择性地禁用优化。
该技术已在Java HotSpot虚拟机的生产版本中实现,并在一系列性能测试和应用中获得了明显的性能改进。
该技术适用于任何基于虚拟机的编程语言实现,主要是块结构的锁定原语。
背景和动机
The Java programming language contains built-in support for monitors to facilitate the construction of multithreaded programs. Much research has been dedicated to decreasing the execution cost of the associated synchronization primitives.
Java编程语言包含对监控器的内置支持,以促进多线程程序的构建。
很多研究都致力于降低相关同步原语的执行成本。
A class of optimizations which can be termed lightweight locking are focused on avoiding as much as possible the use of “heavy-weight” operating system mutexes and condition variables to implement Java monitors. The assumption behind these techniques is that most lock acquisitions in real programs are un- contended. Lightweight locking techniques use atomic operations upon monitor entry, and sometimes upon exit, to ensure correct synchronization. These techniques fall back to using OS mutexes and condition variables when contention occurs.
一类可以被称为轻量级锁的优化技术集中在尽可能避免使用 “重量级 “的操作系统互斥锁和条件变量来实现Java监视器。
这些技术背后的假设是,实际程序中的大部分锁获取都是无竞争的。
轻量级锁技术在监视器进入时使用原子操作,有时在退出时也会使用,以确保正确的同步。
当发生锁争夺时,这些技术又回到了使用操作系统的互斥和条件变量。
A related class of optimizations which can be termed biased locking rely on the further property that not only are most monitors uncontended, they are only entered and exited by one thread during the lifetime of the monitor. Such monitors may be profitably biased toward the owning thread, allowing that thread to enter and exit the monitor without using atomic operations. If another thread attempts to enter a biased monitor, even if no contention occurs, a relatively expensive bias revocation operation must be performed. The profitability of such an optimization relies on the benefit of the elimination of atomic operations being higher than the penalty of revocation.
另一类相关的优化可以被称为偏向锁,依赖于进一步的程序运行特征,即大多数监视器不仅是无竞争的,而且在监视器的生命周期内只会由一个线程进入和退出。
这样的监控器可以偏向拥有的线程以获取高性能的执行效果,即允许该线程在不使用原子操作的情况下进入和退出监控器。
如果另一个线程试图进入一个偏向的监视器,即使没有发生竞争,也必须执行一个相对昂贵的偏向撤销操作。
这种优化的是否能带来收益,依赖于消除原子操作的收益高于撤销操作的消耗。
Current refinements of biased locking techniques decrease or eliminate the penalty of bias revocation, but do not optimize certain synchronization patterns which occur in practice, and also impact peak performance of the algorithm
目前对偏向锁技术的改进,减少或消除了撤销偏向锁的消耗,但没有优化实际中出现的某些同步情况,也影响了算法的峰值性能。
Multiprocessor systems are increasingly prevalent; so much so that uniprocessors are now the exception rather than the norm. Atomic operations are significantly more expensive on multi-processors than uniprocessors, and their use may impact scalability and performance of real applications such as javac by 20% or more (Section 6). It is crucial at this juncture to enable biased locking optimizations for industrial applications, and to optimize as many patterns of synchronization in these applications as possible.
多处理器系统越来越普遍;以至于单处理器现在是例外而不是标准。
原子运算在多处理器上的成本明显高于单处理器,使用原子运算可能会对实际应用(如javac)的可扩展性和性能产生20%以上的影响(第6节)。
在这个关头,为企业级应用进行偏向锁优化,并尽可能地优化这些应用中的同步模式是至关重要的。
我们的贡献
This paper presents a novel technique for eliminating atomic oper- ations associated with the Java language’s synchronization primitives called store-free biased locking (SFBL). It is similar to, and is inspired by, the lock reservation technique and its refinements. The specific contributions of our work are:
- We build upon invariants preserved by the Java HotSpot VM to eliminate repeated stores to the object header. Store elimination makes it easier to transfer bias ownership between threads.
- We introduce bulk rebiasing and revocation to amortize the cost of per-object bias revocation while retaining the benefits of the optimization.
- An epoch-based mechanism which invalidates previously held biases facilitates the bulk transfer of bias ownership from one thread to another.
改论文提供了一个新技术,叫做无存储的偏向锁(store-free biased locking,SFBL),该技术可消除Java语言的同步原语中的原子操作。
它和锁保留技术以及其改进技术类似。
我们的贡献是:
- 我们在Java HotSpot虚拟机保留的不变性基础上,消除对象头的重复存储。存储消除使得线程之间更容易转移偏向所有权。
- 我们引入批量重偏向和批量撤销机制,在保留优化收益的前提下,摊销每个对象的偏向撤销成本。
- 使用基于epoch的机制失效偏向,优化了偏向锁所有权从一个线程到另一个线程的批量转移。
Our technique is the first to support efficient transfer of bias ownership from one thread to another for sets of objects. Previous techniques do not optimize the situation in which more than one thread locks a given object. The approaches above support optimization of more synchronization patterns in applications than previous techniques, and allow biased locking to be enabled by default for all applications.
我们是第一个支持高效转移偏向锁所有权的技术。
之前的技术没有优化多线程锁定指定的对象的场景。
与之前的技术相比,上述方法支持优化更多应用使用的同步模式,并允许所有应用默认启用偏向锁。
论文的结构
The rest of this paper is organized as follows. Section 2 describes the lightweight locking technique in the Java HotSpot VM and its invariants. Section 3 describes the basic version of our biased locking technique. Section 4 describes the bulk rebiasing and revocation techniques used to amortize the cost of bias revocation. Section 5 improves the scalability of bulk rebiasing and revocation using epochs. Section 6 discusses results from various benchmarks. Section 7 provides detailed comparisons to earlier work. Section 8 describes how to obtain our implementation, and Section 9 concludes.
本文的其余部分组织如下。
第2节描述了Java HotSpot虚拟机中的轻量锁技术及其不变性(invariants,不知道咋翻译)。
第3节描述了我们偏向锁技术的基本版本。
第4节描述了用于摊销偏向撤销成本的批量重偏向和撤销技术。
第5节使用任期提高了批量重偏向和撤销的可扩展性。
第6节讨论了各种基准测试的结果。
第7节提供了与早期工作的详细比较。
第8节描述了如何获得我们的实现,第9节是结论。
Java HotSpot虚拟机中轻量级锁介绍
The lightweight locking technique used by the Java HotSpot VM has not been described in the literature. Because knowledge of some of its aspects is required to understand store-free biased locking (SFBL), we present a brief overview here.
Java HotSpot虚拟机使用的轻量级锁技术还没有论文描述。
由于理解无存储偏向锁(SFBL)需要了解它的一些方面的知识,我们在这里做一个简单的概述。
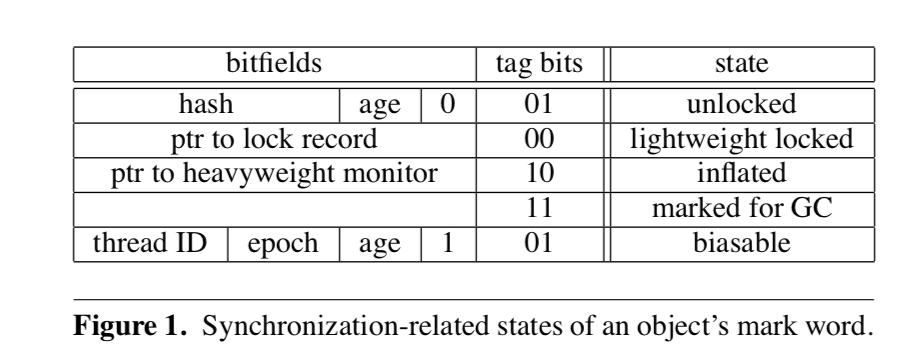
The Java HotSpot VM uses a two-word object header. The first word is called the mark word and contains synchronization, garbage collection and hash code information. The second word points to the class of the object. See figure 1 for an overview of the layout and possible states of the mark word.
Java HotSpot虚拟机使用两个字的对象头。第一个字称为Mark Word,包含同步、垃圾收集和哈希码信息。第二个字指向对象的类。请参见图1,了解MarkWord的布局和其可能的状态。
Our biased locking technique relies on three invariants. First, the locking primitives in the language must be mostly block-structured. Second, optimized compiled code, if it is produced by the virtual machine, must only be generated for methods with block-structured locking. Third, interpreted execution must detect unstructured locking precisely. We now show how these invariants are maintained in our VM.
我们的偏向锁技术依赖于三个不变条件。
第一,编程语言中的锁定原语必须大部分是块结构的。
第二,由虚拟机产生的优化后的编译代码,必须只为具有块结构化锁定的方法生成。
第三,解释执行必须精确地检测非结构化的锁。
现在我们展示一下在我们的虚拟机中是如何维护这些不变性的。
Whenever an object is lightweight locked by a monitorenter bytecode, a lock record is either implicitly or explicitly allocated on the stack of the thread performing the lock acquisition operation. The lock record holds the original value of the object’s mark word and also contains metadata necessary to identify which object is locked. During lock acquisition, the mark word is copied into the lock record (such a copy is called a displaced mark word), and an atomic compare-and-swap (CAS) operation is performed to attempt to make the object’s mark word point to the lock record. If the CAS succeeds, the current thread owns the lock. If it fails, because some other thread acquired the lock, a slow path is taken in which the lock is inflated, during which operation an OS mutex and condition variable are associated with the object. During the inflation process, the object’s mark word is updated with a CAS to point to a data structure containing pointers to the mutex and condition variable.
每当一个对象被monitorenter字节码轻量级锁锁定时,在执行锁获取操作的线程的堆栈上就会隐式或显式地分配一个锁记录(Lock Record)。
锁记录保存着对象的MarkWord的原始值,同时还必须包含一些元数据,用于识别是哪个对象被锁定。
在锁获取过程中,MarkWord被复制到锁记录中(这样的复制称为替换MarkWord),并执行原子(CAS)操作,试图使对象的MarkWord指向锁记录。
如果CAS成功,则当前线程拥有该锁。如果失败了,则表示有其他线程获得了锁,则采取缓慢加锁路径,即锁膨胀,在这个操作过程中,一个OS mutex和条件变量与锁对象相关联。
在膨胀过程中,对象的MarkWord会被CAS更新,指向一个包含mutex和条件变量指针的数据结构。
During an unlock operation, an attempt is made to CAS the mark word, which should still point to the lock record, with the displaced mark word stored in the lock record. If the CAS succeeds, there was no contention for the monitor and lightweight locking remains in effect. If it fails, the lock was contended while it was held and a slow path is taken to properly release the lock and notify other threads waiting to acquire the lock.
在解锁操作过程中,会尝试用存储在Lock Record中的数据对对象的MarkWord进行CAS。如果CAS成功,则说明监控器没有被争用,轻量级锁定仍然有效。
如果失败,则说明锁在被持有时被争夺,并采取缓慢解锁方法正确释放锁,并通知其他等待获取锁的线程。
Recursive locking is handled in a straightforward fashion. If during lightweight lock acquisition it is determined that the current thread already owns the lock by virtue of the object’s mark word pointing into its stack, a zero is stored into the on-stack lock record rather than the current value of the object’s mark word. If zero is seen in a lock record during an unlock operation, the object is known to be recursively locked by the current thread and no update of the object’s mark word occurs. The number of such lock records implicitly records the monitor recursion count. This is a significant property to the best of our knowledge not attained by most other JVM
锁重入的处理方式很简单。如果在轻量级锁获取过程中,当前线程发现其对象的MarkWord指向其堆栈,那么就会在堆栈上的Lock Record中存储一个零,而不是对象的标记字的当前值。
如果在解锁操作过程中,在Lock Record中看到零,则知道对象被当前线程递归锁定,对象的标记字不会发生更新。
这种锁记录的数量隐含了监控器递归计数。
据我们所知,这是一个重要的属性,大多数其他JVM没有实现。
The Java HotSpot VM contains both a bytecode interpreter and an optimizing compiler. The interpreter and compiler-generated code create activation records called frames on a thread’s native stack during activation (i.e., execution) of Java methods. We designate these frames as interpreted or compiled. Interpreted frames contain data from exactly one method, while due to inlining, compiled frames may include data from more than one method.
Java HotSpot虚拟机包含一个字节码解释器和一个优化编译器。
解释器和编译器生成的代码在执行Java方法的过程中,会在线程的原生栈上创建执行记录,称为栈帧。
我们说这些栈帧为解释的或编译的。是因为解释帧仅包含一个方法的数据,而编译帧,由于内联,可能包含一个以上方法的数据。
Interpreted frames contain a region which holds the lock records for all monitors owned by the activation. During interpreted method execution this region grows or shrinks depending upon the number of locks held. In compiled frames, there is no such region. Instead, lock records are allocated by the compiler in a fashion similar to register spill stack slots. During compilation, metadata is generated which describes the set of locks held and the location of their lock records at each potential safepoint in compiled code. The presence of lock records allows the runtime system to enumerate the locked objects and their displaced mark words within each frame. This information is used during various operations internal to the JVM, including bias revocation, which will be described later.
解释帧包含一个区域,该区域保存着方法执行过程中所拥有的Lock Record。
在解释执行过程中,这个区域会根据所持有的锁的数量而增长或缩小。
在编译的框架中,没有这样的区域。相反,锁记录是由编译器以类似于寄存器溢出堆栈插槽(register spill stack slots,啥意思?)的方式分配的。
元数据在编译过程中被生成,它描述了所持有的锁的集合,以及它们在编译代码中每个潜在安全点的Lock Record的位置。
Lock Records的存在使得运行时系统可以枚举出每个栈帧内被锁定的对象和它们的位移标记字。
这些信息在JVM内部的各种操作过程中被使用,包括后面将介绍的偏向撤销。
The Java Virtual Machine Specification requires that an IllegalMonitorStateException be thrown if a monitorexit bytecode is executed without having previously executed a matching monitorenter. The interpreter detects this situation by checking that a lock record exists for an object being unlocked. It is not specified what happens when a monitorenter bytecode is executed in a method followed by removal of the corresponding frame from the stack without executing a monitorexit bytecode. In this case a JVM may legally either throw an exception or not. The Java Hotspot VM’s interpreter eagerly detects this situation by iterating through the lock records when removing an interpreted frame and forcibly unlocking the corresponding objects. It then throws an exception if any locked objects were found.
Java虚拟机规范要求,如果执行monitorexit字节码时,之前没有匹配的monitorenter,就会抛出IllegalMonitorStateException。
解释器通过检查被解锁的对象是否存在Lock Record来检测这种情况。
当一个monitorenter字节码在方法中执行后,没有执行monitorexit字节码就从堆栈中删除相应的栈帧时,会发生什么情况呢?
在这种情况下,JVM可以合法地抛出异常或不抛出异常。
Java Hotspot虚拟机的解释器急切地检测到这种情况,在删除一个解释帧时,通过迭代锁记录,强行解锁相应的对象。
然后,如果发现任何锁定的对象,它就会抛出一个异常。
The Java HotSpot client and server optimizing compilers will only compile and inline methods if dataflow analysis has proven that all monitorenter and monitorexit operations are properly paired; in other words, every lock of a given object has a matching unlock on the same object. Attempts to leave an object locked after the method returns, or to unlock an object not locked by that method, are detected by dataflow analysis. Such methods, which almost never occur in practice, are never compiled or inlined but always interpreted.
Java HotSpot客户端和服务器优化编译器只有在数据流分析证明所有的monitorenter和monitorexit操作都是成对的情况下才会编译和内联方法;
换句话说,一个给定对象的每一个锁都有一个匹配的解锁在同一个对象上。
在方法返回后试图让一个对象被锁定,或者解锁一个没有被该方法锁定的对象,都会被数据流分析检测到。
这样的方法,在实践中几乎不会出现,从来不会被编译或内联,而总是被解释。
Because interpreted execution precisely detects unstructured locking, and because compiled execution is proven through monitor matching to perform correct block-structured locking, it is guaranteed that an object’s locking state matches the program’s execution at all times. It is never the case that an object’s locking state claims that it is owned by a particular thread when in fact the method which performed the lightweight lock has already exited. A method may not unlock an object unless precisely that activation, and not one further up the stack, locked the object. These are essential properties enabling both the elimination of the recursion count described above as well as our biased locking technique in general. Complications arise in monitor-related optimizations such as lock coarsening in JVMs which do not maintain such invariants.
由于解释执行能够精确地检测到非结构化锁定,而且编译执行通过监控器匹配证明能够执行正确的块结构锁定,因此可以保证对象的锁定状态与程序的执行始终匹配。
在任何情况下,如果执行轻量级锁定的方法已经退出了,锁定对象的状态都不会还被该线程持有。
一个方法可能不会解锁一个对象,除非恰恰是那个激活,而不是堆栈上的进一步激活锁定了这个对象。(没看懂)
这些都是必不可少的特性,既能消除上面描述的递归数,也能消除我们一般的偏向锁定技术。
在与监控相关的优化中会出现一些复杂的情况,比如在JVM中的锁粗化,因为JVM并不维护这种不变性。
In summary, the following invariants in a programming language and virtual machine are essential prerequisites of our biased locking technique. First, the locking primitives in the language must be mostly block-structured. Second, compiled code, if it ex- ists in the VM, must only be produced for methods with block- structured locking. Third, interpreted execution must detect illegal locking states eagerly. These three invariants imply that an explicit recursion count for the lock is not necessary. Additionally, some mechanism must be present to record a “lock record” for the object externally to the object. In the Java HotSpot VM a lock record is allocated on the stack, although it might be allocated elsewhere.
综上所述,编程语言和虚拟机中的以下不变条件是我们的偏向锁技术的基本前提。
首先,语言中的锁定基元必须大部分是块结构的。
第二,编译后的代码,如果在虚拟机中运行,必须只为具有块结构锁的方法生成。
第三,解释执行必须急切地检测非法锁定状态。
这三个不变量意味着,锁的显式递归计数是不必要的。此外,必须存在某种机制,以便在对象外部记录对象的 “锁记录”。
在Java HotSpot虚拟机中,锁记录是在堆栈上分配的,尽管它可能在其他地方分配。
不占存储(Store free)的偏向锁
Assuming the invariants in Section 2, the SFBL algorithm is simple to describe. When an object is allocated and biasing is enabled for its data type (discussed further in Section 4), a bias pattern is placed in the mark word indicating that the object is biasable (figure 1). The Java HotSpot VM uses the value 0x5 in the low three bits of the mark word as the bias pattern.
如果假设第2节中提到的不变条件,不占存储的偏向锁讲解起来很简单。
当分配一个对象并且偏向锁是启用状态时(在第4节中进一步讨论),一个偏向模式被放置在标记字中,表示该对象是可偏向的(图1)。
Java HotSpot虚拟机使用标记字低三位中的值0x5作为偏向模式。
The thread ID may be a direct pointer to the JVM’s internal representation of the current thread, suitably aligned so that the low bits are zero. Alternatively, a dense numbering scheme may be used to allow better packing of thread IDs and potentially more fields in the biasable object mark word.
线程ID可以是指向JVM的当前线程的内部表示的指针,适当地对齐,使低位为零。
另外,可以使用编号方案,以便更好地包装线程ID,并在可偏向对象标记字中可以存储更多的字段。
During lock acquisition of a biasable but unbiased object, an attempt is made to CAS the current thread ID into the mark word’s thread ID field. If this CAS succeeds, the object is now biased to- ward the current thread, as in figure 2. The current thread becomes the bias owner. The bias pattern remains in the mark word along- side the thread ID.
在一个可偏向但目前还不是偏向状态的对象的锁获取过程中,一个尝试是将当前线程ID CAS到markword的线程ID字段中。
如果CAS成功,对象就会偏向于当前线程,如图2所示。当前线程成为偏向所有者。偏向模式与线程ID一起保留在标记字中。
If the CAS fails, another thread is the bias owner, so that thread’s bias must be revoked. The state of the object will be made to appear as if it had been locked by the bias owner using the JVM’s underlying lightweight locking scheme. To do this, the thread attempting to bias the object toward itself must manipulate the stack of the bias owner. To enable this a global safepoint is reached, at which point no thread is executing bytecodes. The bias owner’s stack is walked and the lock records associated with the object are filled in with the values that would have been produced had lightweight locking been used to lock the object. Next, the object’s mark word is updated to point to the oldest associated lock record on the stack. Finally, the threads blocked on the safepoint are released. Note that if the lock were not actually held at the present moment in time by the bias owner, it would be correct to revert the object back to the “biasable but unbiased” state and re-attempt the CAS to acquire the bias. This possibility is discussed further in section 4.
如果CAS操作失败了,另外一个线程是偏向锁持有者,导致必须撤销那个线程的偏向。
对象的状态要被弄成好像它已经被偏向所有者使用JVM的底层轻量级锁定方案锁定了一样。
要做到这一点,试图将对象偏向自己的线程必须操纵偏向所有者的栈。
为了实现这一点,需要达到一个全局安全点,此时没有线程在执行字节码。
偏向所有者的堆栈被遍历,与对象相关联的锁记录被填入轻量级锁的值。
接下来,对象的markword被更新为指向锁持有者堆栈上最古老的锁记录。
最后,安全点上被阻塞的线程被释放。
需要注意的是,如果锁在当前时间点没有被偏向所有者实际持有,那么正确的做法是将对象恢复到 “可偏向但无偏置 “的状态,并重新尝试CAS来获取偏向。
这种可能性将在第4节中进一步讨论。
If the CAS succeeded, subsequent lock acquisitions examine the object’s mark word. If the object is biasable and the bias owner is the current thread, the lock is acquired with no further work and no updates to the object header; the displaced mark word in the lock record on the stack is left uninitialized, since it will never be examined while the object is biasable. If the object is not biasable, lightweight locking and its fallback paths are used to acquire the lock. If the object is biasable but biased toward another thread, the CAS failure path described in the previous paragraph will be taken, including the associated bias revocation.
如果CAS成功,后续的锁获取会检查对象的标记字。如果对象是可偏向的,且偏向所有者是当前线程,则锁的获取不需要再做任何工作,也不需要更新对象头;
堆栈上的锁记录中的位移标记字不被初始化,因为在对象可偏向时,它永远不会被检查。
如果对象不可偏置,则使用轻量级锁及其后备方案来获取锁。
如果对象是可偏向的,但偏向另一个线程,则会采取上一段描述的CAS失败路径,包括相关的偏向撤销。
When an object is unlocked, the state of its mark word is tested to see if the bias pattern is still present. If it is, the unlock operation succeeds with no other tests. It is not even necessary to test whether the thread ID is equal to the current thread’s ID. If another thread had attempted to acquire the lock while the current thread was actually holding the lock and not just the bias, the bias revocation process would have ensured that the object’s mark word was reverted to the unbiasable state.
当一个对象被解锁时,将查看其标记字的状态,以确定偏向模式是否仍然存在。
如果存在,则解锁操作成功,无需其他操作。
甚至不需要测试线程ID是否等于当前线程的ID。
如果另一个线程试图在当前线程实际持有锁而不仅仅是偏向的情况下获取锁,偏向撤销过程就会确保对象的markword恢复到不可偏向的状态。
Since the SFBL unlock path does no error checking, the correctness of the unlock path hinges on the interpreter’s detection of unstructured locking. The lock records in interpreter activations ensure that the body of the monitorexit operation will not be executed if the object was not locked in the current activation. The guarantee of matched monitors in compiled code implies that no error check- ing is required in the SFBL unlock path in compiled code.
由于SFBL解锁路径不进行错误检查,所以解锁路径的正确性取决于解释器对非结构化锁定的检测。
解释执行中的锁记录保证了如果对象在当前执行中没有被锁定,那么monitorexit操作的主体将不会被执行。
保证监视器的匹配,意味着在编译代码中的SFBL解锁路径中不需要进行错误检查。
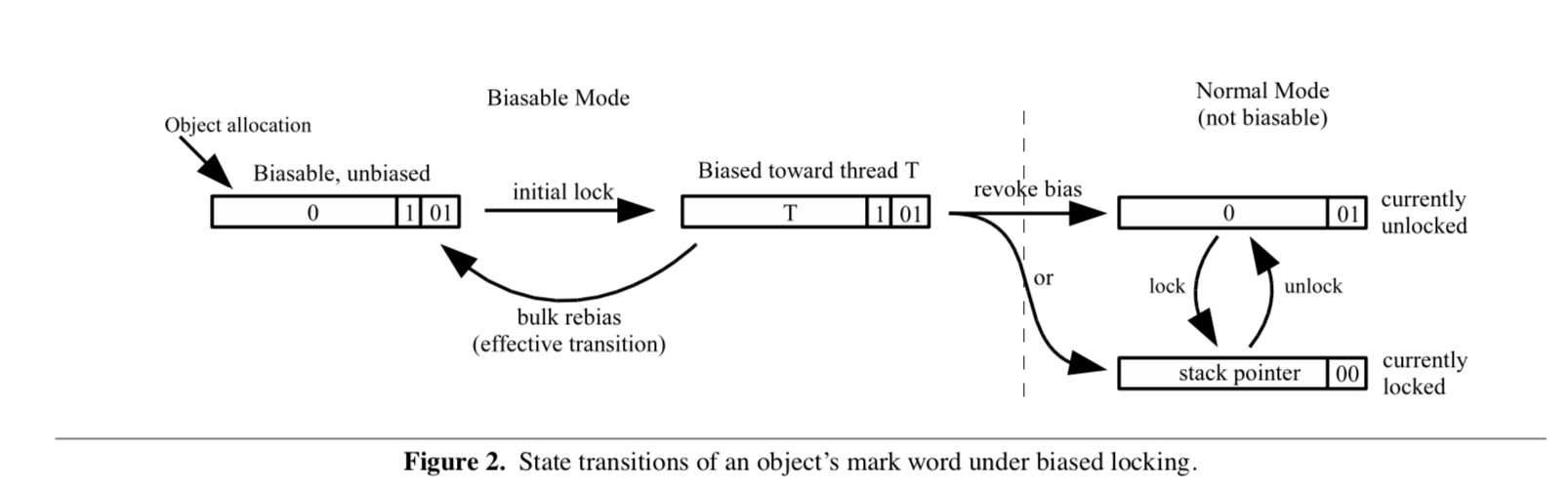
Figure 2 shows the state transitions of the mark word of an object under the biased locking algorithm. The bulk rebiasing edge, which is described further in sections 4 and 5, is only an effective, not an actual, transition and does not necessarily involve an update to the object’s mark word. Recursive locking edges, which update the on-stack lock records but not the mark word, and the heavy-weight locking state, which involves contention with one or more other threads, are omitted for clarity.
图2显示了偏向锁定算法下对象的标记字的状态转换。
在第4节和第5节将进一步描述的批量重偏向锁技术,只是一种有效的转换,而不是实际的转换,不一定会对对象的markword进行更新。
为了清楚起见,省略了更新栈上锁记录但不更新markword的递归锁技术,以及处理多个其他线程争夺的重量级锁状态。
批量偏向和撤销
Analysis of execution logs of SFBL for the SPECjvm98, SPECjbb- 2000, SPECjbb2005 and SciMark benchmark suites yields two insights. First, there are certain objects for which biased locking is obviously unprofitable, such as producer-consumer queues where two or more threads are involved. Such objects necessarily have lock contention, and many such objects may be allocated during a program’s execution. It would be ideal to be able to identify such objects and disable biased locking only for them. Second, there are situations in which the ability to rebias a set of objects to another thread is profitable, in particular when one thread allocates many objects and performs an initial synchronization operation on each, but another thread performs subsequent work on them.
我们使用SPECjvm98、SPECjbb-2000、SPECjbb2005和SciMark的基准套件对SFBL进行测试,查看和分析执行日志,得到了两个启示。
首先,对某些对象来说,使用偏向锁定显然是无利可图的,比如涉及两个或多个线程的生产者-消费者队列。这样的对象必然存在锁争用,而且很多这样的对象可能在程序执行过程中被分配。
如果能够识别出这样的对象,并且只将它们禁用偏向,那将是非常理想的。
其次,在某些情况下,能够将一组对象重新偏向给另一个线程是有利可图的,特别是当一个线程分配了许多对象,并对每个对象执行了初始同步操作,但另一个线程对它们执行了后续工作。
When attempting to selectively disable biased locking, we must be able to identify objects for which it is unprofitable. If one were able to associate an object with its allocation site, one might find patterns of shared objects; for example, all objects allocated at a particular site might seem to be shared between multiple threads. Experiments indicate this correlation is present in many programs[6]. Being able to selectively disable the insertion of the biasable mark word at that site would be ideal. However, due to its overhead, allocation site tracking is to the best of our knowledge not currently exploited in production JVMs.
当有选择地禁用偏向锁时,我们必须能够识别使用偏向锁无利可图的对象。
如果能够将一个对象与它的分配点关联起来,我们可能会发现共享对象的模式;
例如,所有分配在特定地方的对象可能看起来是在多个线程之间共享的。
实验表明,这种关联性存在于许多程序中。
能够有选择地禁止在该地方插入可偏向的标记字是非常理想的。
然而,据我们所知,由于其开销,分配点跟踪目前在生产的JVM中还没有被利用。
We have found empirically that selectively disabling SFBL for a particular data type is a reasonable way to avoid unprofitable situations. We therefore amortize the cost of rebiasing and individual object bias revocation by performing such rebiasing and revoking in bulk on a per-data-type basis.
同时,根据经验我们发现,有选择地禁用某类的SFBL是避免无利可图情况的合理方法。
因此,我们通过在每个类的基础上批量执行这种重偏向和批量撤销,来摊销重偏向和单个对象偏向撤销的成本。
Heuristics are added to the basic SFBL algorithm to estimate the cost of individual bias revocations on a per-data-type basis. When the cost exceeds a certain threshold, a bulk rebias operation is attempted. All biasable instances of the data type have their bias owner reset, so that the next thread to lock the object will reacquire the bias. Any biasable instance currently locked by a thread may optionally have its bias revoked or left alone.
我们在基本的SFBL算法中增加了启发式算法,以估计每个类的单个偏向撤销的成本。
当成本超过某个阈值时,就会尝试进行批量重偏向操作。
该类的所有可偏向实例的偏向所有者都会被重置,这样下一个锁定对象的线程就会重新获得偏向。
任何当前被线程锁定的可偏向实例都可以选择撤销其偏向或什么也不做。
If bias revocations for individual instances of a given data type persist after one or more bulk rebias operations, a bulk revocation is performed. The mark words of all biasable instances of the data type are reset to the lightweight locking algorithm’s initial value. For currently-locked and biasable instances, the appropriate lock records are written to the stack, and their mark words are adjusted to point to the oldest lock record. Further, SFBL is disabled for any newly allocated instances of the data type.
如果给定类的单个实例的偏向撤销在一个或多个批量重偏向操作后持续存在,则执行批量撤销。
该数据类型的所有可偏向实例的标记字被重置为轻量级锁定算法的初始值。
对于当前锁定的和可偏向的实例,锁记录会被写入堆栈,它们的markword被调整为指向最老的锁定记录。
此外,对于该类的任何新分配的实例,SFBL被禁用。
The most obvious way of finding all instances of a certain data type is to walk through the object heap, which is how these techniques were initially implemented (Section 5 describes the current implementation). Despite the computational expense involved, bulk rebiasing and revocation are surprisingly effective.
寻找某种类的所有实例的最明显的方法是遍历堆,这就是这些技术最初的实现方式(第5节介绍了当前的实现)。尽管涉及到计算费用,但对批量重偏向和撤销却出奇的有效。
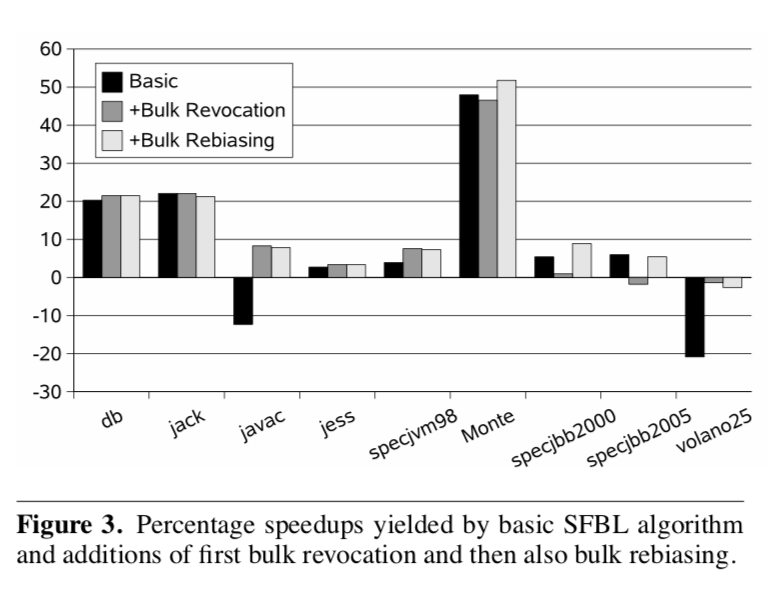
Figure 3 illustrates the benefits of the bulk revocation and rebiasing heuristics compared to the basic biased locking algorithm . The javac sub-benchmark from SPECjvm98 computes many identity hash codes, forcing bias revocation of the affected objects since there are no bits available to store the hash code in the biasable state (see figure 1). Bulk revocation benefits this and similar situations, here in particular because our early implementations performed relatively inefficient bias revocation in this case. SPECjbb2000 and SPECjbb2005 transfer a certain number of objects between threads as each warehouse is added to the benchmark, not enough to impact scores greatly but enough to trigger the bulk revocation heuristic. The addition of bulk rebiasing, which is then triggered at the time of addition of each warehouse, reclaims the gains to be had.
图3说明了与基本的偏向锁定算法相比,批量撤销和重偏向启发式算法的好处。
SPECjvm98中的javac子基准计算了许多哈希码,强制受影响对象进行偏向撤销,因为没有存储空间可用于在可偏向状态下存储哈希码(见图1)。
批量撤销有利于这种情况和类似的情况,这里特别是因为我们的早期实现在这种情况下执行了相对低效的偏向撤销。
SPECjbb2000和SPECjbb2005在每个仓库加入基准时,都会在线程之间传输一定数量的对象,虽然不足以对分数产生很大影响,但足以触发批量撤销启发式算法。
在每个仓库增加的时候再触发批量重偏向,就可以把要获得的收益收回来。
Note that the addition of both bulk revocation and rebiasing does not reduce the peak performance of biased locking compared to the basic algorithm without these operations. This is discussed further in Section 7.
请注意,与不进行这些操作的基本算法相比,增加批量撤销和重偏向并不会降低偏向锁定的峰值性能。这将在第7节中进一步讨论。
基于epoch的批量重偏向和撤销
Though walking the object heap to implement bulk rebias and revocation algorithms is workable for relatively small heaps, it does not scale well as the heap grows. To address this problem, we introduce the concept of an epoch, a timestamp indicating the validity of the bias. As shown in figure 1, the epoch is a bitfield in the mark word of biasable instances. Each data type has a corresponding epoch as long as the data type is biasable. An object is now considered biased toward a thread T if both the bias owner in the mark word is T, and the epoch of the instance is equal to the epoch of the data type.
虽然遍历对象堆来实现批量重偏向和撤销对于相对较小的堆来说是可行的,但随着堆的增长,它的扩展性并不好。
为了解决这个问题,我们引入了epoch的概念,epoch是一个表示偏向有效性的时间戳。
如图1所示,epoch是可偏向对象的markword中的一个bit位。
只要类是可偏向的,每个类都有一个相应的epoch。
如果markword中的偏向所有者是线程T,并且实例的epoch等于该数据类型的epoch,那么现在就认为一个对象偏向于线程T。
With this scheme, bulk rebiasing of objects of class C becomes much less costly. We still stop all mutator threads at a safe-point; without stopping the mutator threads we cannot reliably tell whether or not a biased object is currently locked. The thread performing the rebiasing:
有了这个方案,类C的对象的批量重偏向成本就会大大降低。
我们仍然在一个安全点停止所有的突变器线程;如果不停止突变器线程,我们就无法可靠地判断一个偏向的对象当前是否被锁定。线程执行重偏向操作:
Increments the epoch number of class C. This is a fixed-width integer, with the same bit-width in the class as in the object headers. Thus, the increment operation may cause wrapping, but as we will argue below, this does not compromise correct- ness.
增大class C的epoch数字。这是一个固定宽度的整数,在类中的位宽与对象头中的位宽相同。因此,增量操作可能会导致封装,但正如我们在下面所论证的,这并不影响正确性。
Scans all thread stacks to locate objects of class C that are currently locked, updating their bias epochs to the new current bias epoch for class C. Alternatively, based on heuristic consideration, these objects’ biases could be revoked.
扫描所有线程的堆栈,定位当前被锁定的C类对象,将它们的偏向epoch更新为C类新的当前偏向epoch,另外,基于启发式考虑,可以撤销这些对象的偏向。
No heap scan is necessary; objects whose epoch numbers were not changed will, for the most part, now have a different epoch number than their class, and will be considered to be in the biasable but unbiased state.
不进行堆扫描是十分有必要的。
大部分情况下,其epoch未被改变的对象,现在的epoch将与它们的class不同,并将被认为是处于可偏向但无偏向的状态。
The pseudocode for the lock-acquisition operation then looks much like:
然后,锁获取操作的伪代码即这样:

Above we made the qualification that incrementing a class’s bias epoch will “for the most part” rebias all objects of the given class. This qualification is necessary because of the finite width of the epoch field, which allows integer wrapping. If the epoch field is N bits wide, and X is an object of type T, then if 2ˆN bulk rebiasing operations for class T occur without any lock operation updating the bias epoch of X to the current epoch, then it will appear that X is again biased in the current epoch, that is, that its bias is valid. Note that this is purely a performance concern – it is perfectly permissible, from a correctness viewpoint, to consider X biased. It may mean that if a thread other than the bias holder attempts to lock X, an individual bias revocation operation may be required. But a sufficiently large value of N can decrease the frequency of this situation significantly: objects that are actually locked between one epoch and the next have their epoch updated to the current epoch, so this situation only occurs with infrequently-locked objects. Further, we could arrange for operations that naturally visit all live objects, namely garbage collection, to normalize lock states, convert- ing biased objects with invalid epochs into biasable-but-unbiased objects. (If done in a stop-world collection this can be done with non-atomic stores; in a concurrent marker, however, the lock word would have to be updated with an atomic operation, since the marking thread would potentially compete with mutator threads to modify the lock word.) Therefore, wrapping issues could also be prevented by choosing N large enough to make it highly likely that a full-heap garbage-collection would occur before 2ˆN bulk rebias operations for a given type can occur.
上面我们做了一个假设,即递增一个类的偏向epoch将 “在大多数情况下 “导致重偏向给定类的所有对象。
这个假设是必要的,因为epoch字段的宽度是有限的,它允许整数包装。如果epoch字段是N位宽,X是T类型的对象,那么如果对T类进行2ˆN次批量重偏向操作,而没有任何锁操作将X的偏置epoch更新为当前epoch,那么X在当前epoch中又会出现偏向,也就是说,它的偏向是有效的。
请注意,这纯粹是对性能的考虑,从正确性的角度来看,完全可以认为X是有偏差的。
这可能意味着,如果偏置持有者以外的线程试图锁定X,可能需要进行单独的偏置撤销操作。
但是一个足够大的N值可以大大降低这种情况的频率:在一个epoch和下一个epoch之间被实际锁定的对象会将其epoch更新为当前epoch,所以这种情况只发生在不经常锁定的对象上。
此外,我们可以安排自然访问所有实时对象的操作,即垃圾收集,以规范化锁定状态,将具有无效纪元的偏向对象转换为可偏向但无偏向的对象。(如果在STW阶段,这可以用非原子存储来完成;但是在并发标记中,markword必须用原子操作来更新,因为标记线程有可能与突变器线程竞争修改锁字)。
因此,包装问题也可以通过选择足够大的N来预防,以使在给定类型的2ˆN批量重偏向操作发生之前,极有可能发生fullGC。
In practice, wrapping of the epoch field can be ignored. Bench-marking has not uncovered any situations where individual bias revocations are provoked due to epoch overflow. The current implementation of biased locking in the Java HotSpot VM normalizes object headers during GC, so the mark words of biasable objects with invalid epochs are reverted to the unbiased state. This is done purely to reduce the number of mark words preserved during GC, not to counteract epoch overflow.
在实践中,对epoch的包装可以被忽略。
压测过程中并没有发现任何由于epoch溢出而引发个别偏向撤销的情况。
目前Java HotSpot VM中的偏置锁定的实现在GC过程中对对象头进行了归一化处理,因此具有无效epoch的可偏置对象的标记字会恢复到无偏置状态。
这样做纯粹是为了减少GC过程中保存的标记字数量,而不是为了抵消epoch溢出。
It is a straightforward extension to support bulk revocation of biases of a given data type. Recall that in bulk revocation, unlike bulk rebiasing, it is desired to completely disable the biased locking optimization for the data type, instead of allowing the object to be potentially rebiased to a new thread. Rather than incrementing the epoch in the data type, the “biasable” property for that data type may be disabled, and a dynamic test of this property added to the lock sequence:
支持对给定class的批量撤销偏向是一种直接的扩展功能。
回想一下,在批量撤销中,与批量重偏向不同的是,批量撤销希望完全禁用某数据类型的偏向锁定优化,而不是让对象有可能被重偏向到一个新的线程。
所以需要直接禁用该class的“可偏向”属性,而不是递增该class的epoch,同时一个判断需要加在加锁流程中:

This variant of the lock sequence is the one currently implemented in the Java HotSpot VM.
这个锁流程的变体是目前在Java HotSpot虚拟机中实现的。
Epoch-based rebiasing and revocation may also be extended to rebias objects at a granularity between the instance and class level. For example, we might distinguish between objects of a given class based on their allocation site; JIT-generated allocation code could be modified to insert an allocation site identifier in the object header. Each allocation site could have its own epoch, and the locking sequence could check the appropriate epoch for the object:
基于epoch的重偏向和撤销也可以扩展到在实例和class之间的粒度上重偏向对象。
例如,我们可以根据对象的分配点来区分给定类的对象;
JIT生成的分配代码可以被修改为在对象头中插入一个分配点标识符。
每个分配点都可以有自己的epoch,锁定流程可以检查对象的纪元。

To simplify the allocation path for new instances as well as storage of the per-data-type epochs, a prototype mark word is kept in each data type. This is the value to which the mark word of new instances will be set. The epoch is stored in the prototype mark word as long as the prototype is biasable.
为了简化新实例的分配路径以及每个class的epoch的存储,每个class中都保留了一个原型markword。
这是新实例的markword将被设置为的值。只要原型是可偏向的,就会在原型标记字中存储纪元。
In practice, a single logical XOR operation in assembly code computes the bitwise difference between the instance’s mark word and the prototype mark word of the data type. A sequence of tests are performed on the result of the XOR to determine whether the bias is held by the current thread and currently valid, whether the epoch has expired, whether the data type is no longer biasable, or whether the bias is assumed not held, and the system reacts appropriately. Listing 4 shows the complete SPARC assembly code for the lock acquisition path of SFBL with epochs.
在实际应用中,汇编代码中的一个逻辑XOR操作就可以计算出实例的markword和class的原型标记字之间的位差。
对XOR的结果进行一系列的测试,以确定偏向是否被当前线程持有且当前有效,是否过期,class是否不再可偏向,或者假设偏向不持有,系统做出适当的反应。
清单4显示了SFBL带纪元的锁获取路径的完整SPARC汇编代码。
(注:清单4有点长,就不贴了,都是汇编)
结果
(注:都是测试结果对比,非原理性讲解,就不翻译了)
与前人工作的对比
SFBL is similar to, and is inspired by, lock reservation and its refinements. Lock reservation is directly comparable to our basic biased locking technique described in Section 3. Both techniques eliminate all atomic operations for uncontended synchronization and have a severe penalty for bias revocation. Our technique avoids subtle race conditions because objects’ headers are not repeatedly updated with non-atomic stores. However, because an explicit recursion count is not maintained, it is more difficult in our technique to determine at any given point in time whether a biased lock is actually held by a given thread.
SFBL与锁保留及其改进方案类似,并受其启发。
锁保留与我们在第3节中描述的基本偏向锁定技术直接相当。这两种技术都消除了所有无竞争同步的原子操作,并且对偏向撤销有严重的惩罚。
我们的技术避免了微妙的竞争条件,因为对象头不会用非原子存储重复更新。
然而,由于没有维护明确的递归计数,在我们的技术中,在任何给定的时间点确定一个偏向锁是否真的被一个给定的线程持有是比较困难的。
The global safepoint required for bias revocation in our technique is more expensive than the signal used in lock reservation. It can be a barrier to scalability in applications such as Volano with many threads, many contended lock operations, and ongoing dynamic class loading. However, our experience has been that the combination of these characteristics in an application is rare. We have prototyped a per-thread safepoint mechanism and are investigating its performance characteristics. We also believe a less ex- pensive per-object bias revocation technique is possible for uncontended locks while maintaining the useful locking invariants in the Java HotSpot VM, and plan to investigate this in the future.
在我们的技术中,偏向撤销所需的全局安全点比锁保留中使用的信号更昂贵。
在Volano这样有许多线程、许多争夺的锁操作和持续的动态类加载的应用中,这可能是一个扩展性的障碍。
然而,我们的经验是,在一个应用程序中这些特性的组合是罕见的。我们已经建立了一个每个线程安全点机制的原型,并且正在研究它的性能特点。
我们还认为,对于无争夺锁,同时保持Java HotSpot虚拟机中有用的锁定不变性,可以采用一种不那么昂贵的每对象偏向撤销技术,并计划在未来对此进行研究。
Reservation-based spin locks [12, 10] are comparable to our addition of bulk rebiasing and revocation described in Section 4. Both techniques build on top of an underlying biased locking algorithm to reduce the impact of bias revocation. An advantage of reservation-based spin locks is that they largely eliminate, rather than reduce or amortize, the cost of bias revocation. However, reservation-based spin locks do not support transfer of bias ownership between threads. The first thread to lock a given object will always be the bias owner, and other threads will still need to use atomic operations to enter and exit the lock, eliminating the benefits of the optimization for these other threads. In contrast, epoch-based bulk rebiasing allows direct transfer of biases in the aggregate from one thread to another, at the cost of a small number of per-object revocations. Our experience indicates this supports optimization of significantly more synchronization patterns in real programs.
基于保留的自旋锁与我们在第4节中所描述的增加了大量的偏向和撤销技术相类似。
这两种技术都建立在底层的偏向锁算法之上,以减少偏置撤销的影响。
基于保留的自旋锁的一个优点是,它们在很大程度上消除而不是减少或摊销了偏向撤销的成本。
但是,基于保留的自旋锁不支持线程之间转移偏向所有权。
第一个锁定给定对象的线程将始终是偏向所有者,其他线程仍然需要使用原子操作来进入和退出锁,从而消除了这些其他线程的优化好处。
相比之下,基于epoch的批量重偏向允许直接将集合中的偏置从一个线程转移到另一个线程,而代价是少量的每个对象撤销。
我们的经验表明,这支持在实际程序中对更多的同步模式进行优化。
Neither reservation-based spin locks nor our algorithm optimize the case of a single object or small set of objects being locked and unlocked multiple times sequentially by two or more threads, but always in uncontended fashion. Our bulk rebiasing technique optimizes this case in the aggregate, when many such objects are locked in this pattern. Efficient optimization of this synchronization pattern is an important area for future research.
基于保留的自旋锁和我们的算法都不能优化单个对象或一小组对象被两个或多个线程连续多次锁定和解锁的情况,但总是以无竞争的方式。
当许多这样的对象被锁定在这种模式下时,我们的批量重偏向技术对这种情况进行了总体优化。
高效优化这种同步模式是未来研究的一个重要领域。
Reservation-based spin locks appear to adversely impact the peak performance of the lock reservation optimization as can be seen in the published results for db and jack [12, 10]. In contrast, epoch-based bulk rebiasing and revocation appear to reduce the adverse impacts of the biased locking optimization without impact- ing peak performance, as shown in Sections 4 and 6. We believe the high cost of per-object bias revocation in our system is responsible for the negative impact on the Volano benchmark, and plan to reduce this cost in the future. Nonetheless, feedback from customers indicates that our current biased locking implementation yields good results in the field with no pathological performance problems.
基于保留的自旋锁似乎会对锁保留优化的峰值性能产生不利影响,这可以从已发布的db和jack的结果中看出。
相比之下,如第4节和第6节所示,基于epoch的批量重偏向和撤销似乎可以减少偏向锁优化的不利影响,而不影响峰值性能。
我们认为,我们系统中每个对象偏向撤销的高成本是造成Volano基准负面影响的原因,并计划在未来降低这一成本。
尽管如此,来自客户的反馈表明,我们目前的偏置锁定实施在现场产生了良好的结果,没有出现病理性能问题。
Speculative locking [7], another biased locking technique, eliminates all synchronization-related atomic operations, but requires a separate field in each object instance to hold the thread ID. This space increase makes the technique unsuitable for most data types. Additionally, speculative locking does not support the transfer of bias ownership from one thread to another, nor selective disabling of the optimization where unprofitable.
推测性锁定是另一种偏向性锁定技术,它消除了所有与同步相关的原子操作,但需要在每个对象实例中单独设置一个字段来保存线程ID。
这种空间的增加使得该技术不适合大多数数据类型。
此外,推测性锁定不支持将偏向所有权从一个线程转移到另一个线程,也不支持在无利可图的情况下选择性地禁用优化。
Previous lightweight locking techniques[1, 2, 5] exhibit quite different performance characteristics for contended and uncontended locking and contain very different techniques for falling back to heavyweight operating system locks under contention. Some of these techniques use only one atomic operation per pair of lock/unlock operations rather than two. Nonetheless, all of these techniques use at least one atomic operation per lock/unlock sequence so are not directly comparable to SFBL. Potentially, any of these techniques could be used as the underlying synchronization technique for SFBL or a similar biased locking technique.
以前的轻量级锁定技术在有争夺和无争夺的锁定中表现出完全不同的性能特征,并且包含了在争夺下回落到重量级操作系统锁的非常不同的技术。其中一些技术在每对锁/解锁操作中只使用一个原子操作,而不是两个。尽管如此,所有这些技术都在每个锁/解锁序列中使用至少一个原子操作,因此不能直接与SFBL进行比较。这些技术中的任何一种都有可能被用作SFBL或类似的偏向锁定技术的基础同步技术。
使用
Our technique is implemented in the current development version of the Java HotSpot VM. Binaries for various architectures and source code can be downloaded from http://mustang.dev.java.net/. The current build contains the per-data-type epoch-based rebiasing and revocation presented here. The biased locking optimization is currently enabled by default and can be disabled for comparison purposes by specifying -XX:-UseBiasedLocking on the command line.
我们的技术是在当前开发版本的Java HotSpot VM中实现的。
各种架构的二进制文件和源代码可以从 http://mustang.dev.java.net/ 下载。
当前的构建版本包含了这里介绍的基于数据类型的epoch的重偏向和撤销。
偏向锁定优化目前是默认启用的,可以通过在命令行指定-XX:-UseBiasedLocking来禁用,以便进行比较。
结论
Current trends toward multiprocessor systems in the computing industry make synchronization-related atomic operations an increasing impediment to the scalability of applications. Biased locking techniques are crucial to continued performance improvement of programming language implementations.
目前计算行业中多处理器系统的趋势使得与同步相关的原子操作越来越阻碍应用程序的可扩展性。
偏向锁技术是持续提高编程语言实现性能的关键。
We have presented a new biased locking technique which optimizes more synchronization patterns than previous techniques:
我们提出了一种新的偏向锁定技术,它比以前的技术优化了更多的同步模式。
It eliminates repeated stores to the object header. Store elimination makes it easier to transfer bias ownership between threads.
它消除了对对象头的重复存储。存储优化使得线程之间转移偏向所有权更容易。
It introduces bulk rebiasing and revocation to amortize the cost of per-object bias revocation while retaining the benefits of biased locking.
它引入了批量重偏向和撤销,以摊销每个对象偏向撤销的成本,同时保留了偏向锁定的优点。
Epoch-based bulk rebiasing and revocation yield efficient bulk transfer of bias ownership from one thread to another.
基于epoch的批量重偏向和撤销产生了从一个线程到另一个线程的高效批量转移偏向所有权。
Our technique is applicable to any programming language and virtual machine with mostly block-structured locking and a few invariants in the interpreter and dynamic compiler. It yields good performance increases on a range of benchmarks with few penalties, and customer feedback indicates that it performs well on Java programs in the field. We believe our technique can be extended to optimize even more synchronization patterns.
我们的技术适用于任何编程语言和虚拟机,只依赖解释器和动态编译器中使用块结构化锁和一些不变条件。
它在一系列基准上产生了很好的性能提升,而且几乎没有惩罚,客户的反馈表明它在现场的Java程序上表现良好。
我们相信我们的技术可以扩展到优化更多的同步模式。
