一. 前言
Disruptor几乎是每个Java开发绕不过去的坎,其实我想学习这个框架很久了,之前打开看了几次,但是有点复杂就放弃了。
这一次看到了Mpsc,心里在构思多生产者多消费者的队列怎么怎么做,自然就想到了RingBuffer。
有了上文的基础,下面我们就Disruptor来看看多生产者多消费者是怎么实现的。
注意:这个文章并不是特别的分析Disruptor是怎么实现高性能的,诸如网上说的那些伪共享之类,
就是带大家看看源码实现。
二. 使用
先定义Event和它的Factory,就是承载在队列中的元素
1 | public class LongEvent { |
之所以要定义这2个,是因为RingBuffer在初始化的时候,会为数组中的每个元素预先分配Event。
这样我们加入元素的时候,实际上RingBuffer会直接返回LongEvent给你,你要做的就是把Value给Set进去就行了。
下面你要定义EventHandler,就是处理这个事件的类,重写他的onEvent方法:
1 | public static class LongEventHandler implements WorkHandler<LongEvent> { |
下面就可以把整个Disruptor跑起来了:
1 | public static void run() { |
这个方法的原始定义是
public EventHandlerGroup<T> handleEventsWithWorkerPool(final WorkHandler<T>... workHandlers)也就是说我们是传一个Handler数组进去,具体有什么区别,是disruptor使用的区别。
我们这里就假设,我们这么传入,就是有3个Consumer并发的去消费就好。
生产事件并且写入RingBuffer:
1 | RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); |
三. Sequence和数组序号
这个类,单独领出来说,因为容易和Sequencer混淆。
其实我感觉这里的取名不是很好。
Sequence简单说就是个AtomicLong,主要就是个计数器。
但是它不做减法,只做加法。
这里所有用到Sequence的地方,无一例外的都是用来标志数组的位置的。
假设数组的长度是N,那么某一时刻Sequence指向的数组的第(seq & mask)个元素
其中mask = length - 1
四. Sequencer
这里的Sequencer是核心组件,主要是为生产者使用,我们知道循环数组是维护在RingBuffer中的。
但是生产者原子占领Position,都在Sequencer中,在Sequencer中执行成功了,
就可以直接去RingBuffer得到相应的数组元素,往里面set数值。
对应这句话:
1 | long sequence = ringBuffer.next(); |
就是托管至Sequencer操作的。
正常我们来想,对ReadIndex需要维护自己的Seq,所有的消费者都只要一个就够了
但是Disruptor并不是,他为每个消费者都维护了一个Seq。
在消费者中的Seq表示从它的视角中的ReadIndex。
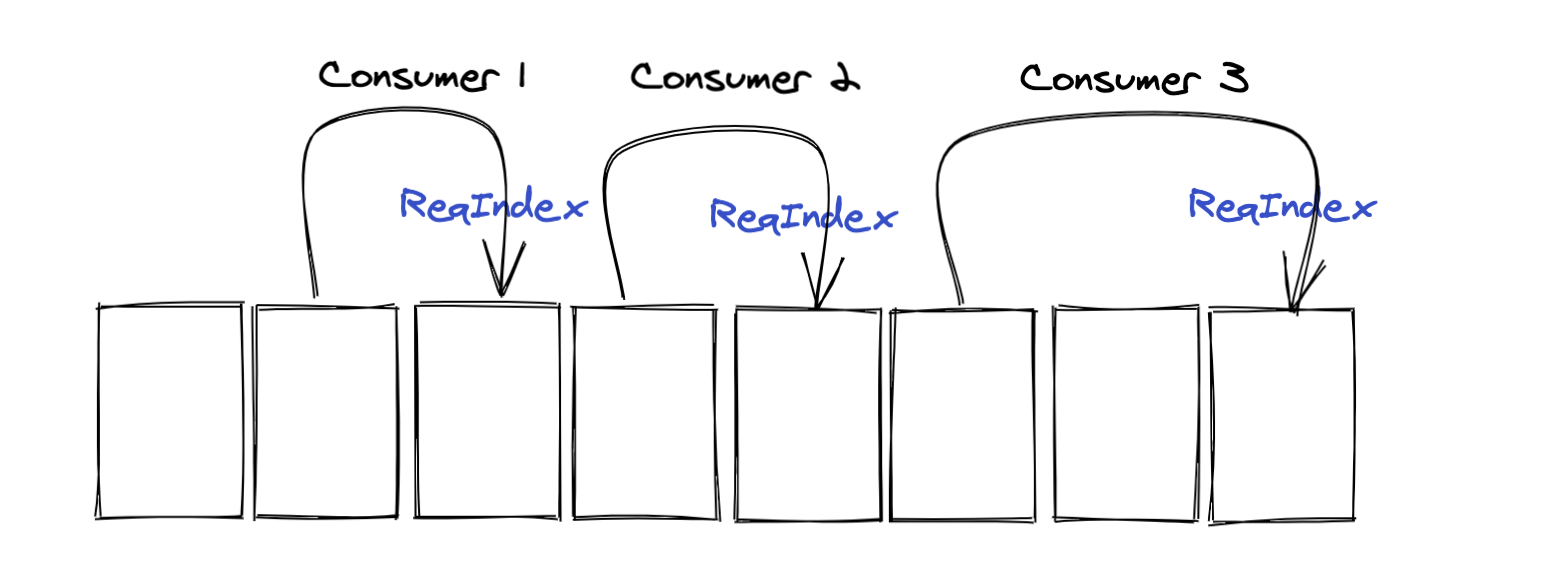
如上图,我们有三个Consumer,对于每个Consumer而言,因为每次获取的一批的可消费事件不同,所以在他们眼中的ReadIndex也是不同的。
我们如果要知道整体的ReadIndex是啥,就是取这三个中最大的一个Seq就行。
在Sequencer初始化的时候,它会收集所有的Consumer的Seq,放在gatingSequences数组中。
1 | public abstract class AbstractSequencer implements Sequencer { |
下面我们来看看public long next(int n)的具体实现。
4.1 SingleProducerSequencer
这个Sequencer表示的是单生产者,所以它的生产方法不用考虑线程并发的问题。
next
他只要往下分配就行了,但是因为是循环数组,所以他需要考虑不能把还没来得及消费的Position给覆盖了。
1 | protected long nextValue = -1; |
我说实话,不太好理解。写的真绕人。
这里的nextValue就是上一次Produce完的Position位置,而nextSequence表示我们要取下N个后的位置,
比如下图中n=4时,next和nextSequence的关系,而wrapPoint指的是上一级的位置。
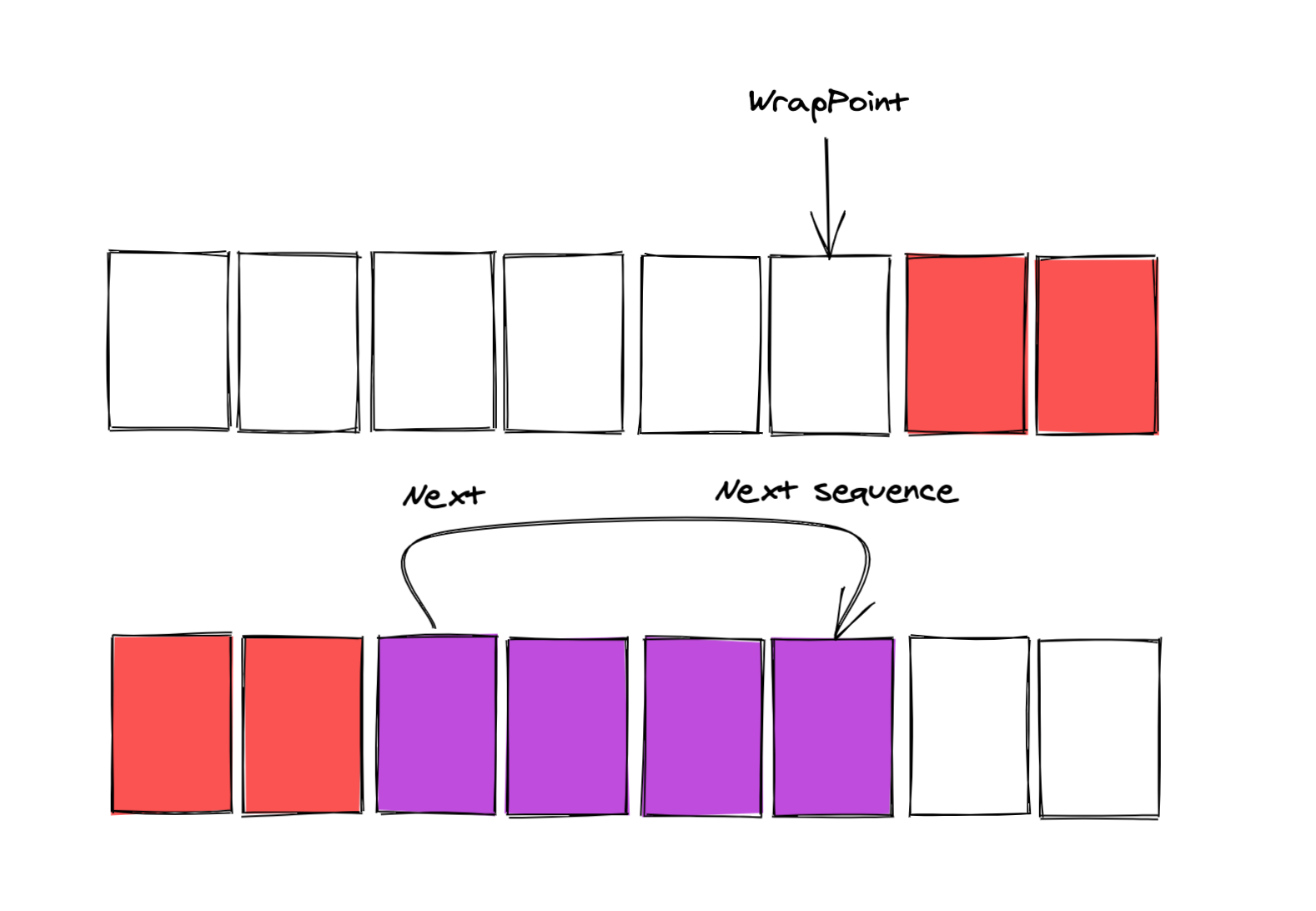
这里的cacheValue,其实就是minSequence的缓存,而minSequence的值是
1 | Util.getMinimumSequence(gatingSequences, next) |
就是所有消费者的Seq和nextValue中的最小的一个。
我们照着上面这个bufferSize=8的图,其中紫色的格子表示我们想要获取的,而红色格子表示还未被消费的。
我们申请成功,至少要保证这种关系的正确。
- WrapPoint要小于所有消费者的Seq
但是为什么swapPoint还要小于nextValue呢?这个不是显而易见的吗?
其实我们n是有限制的,对于n的限制,也是不能大于bufferSize的长度的。
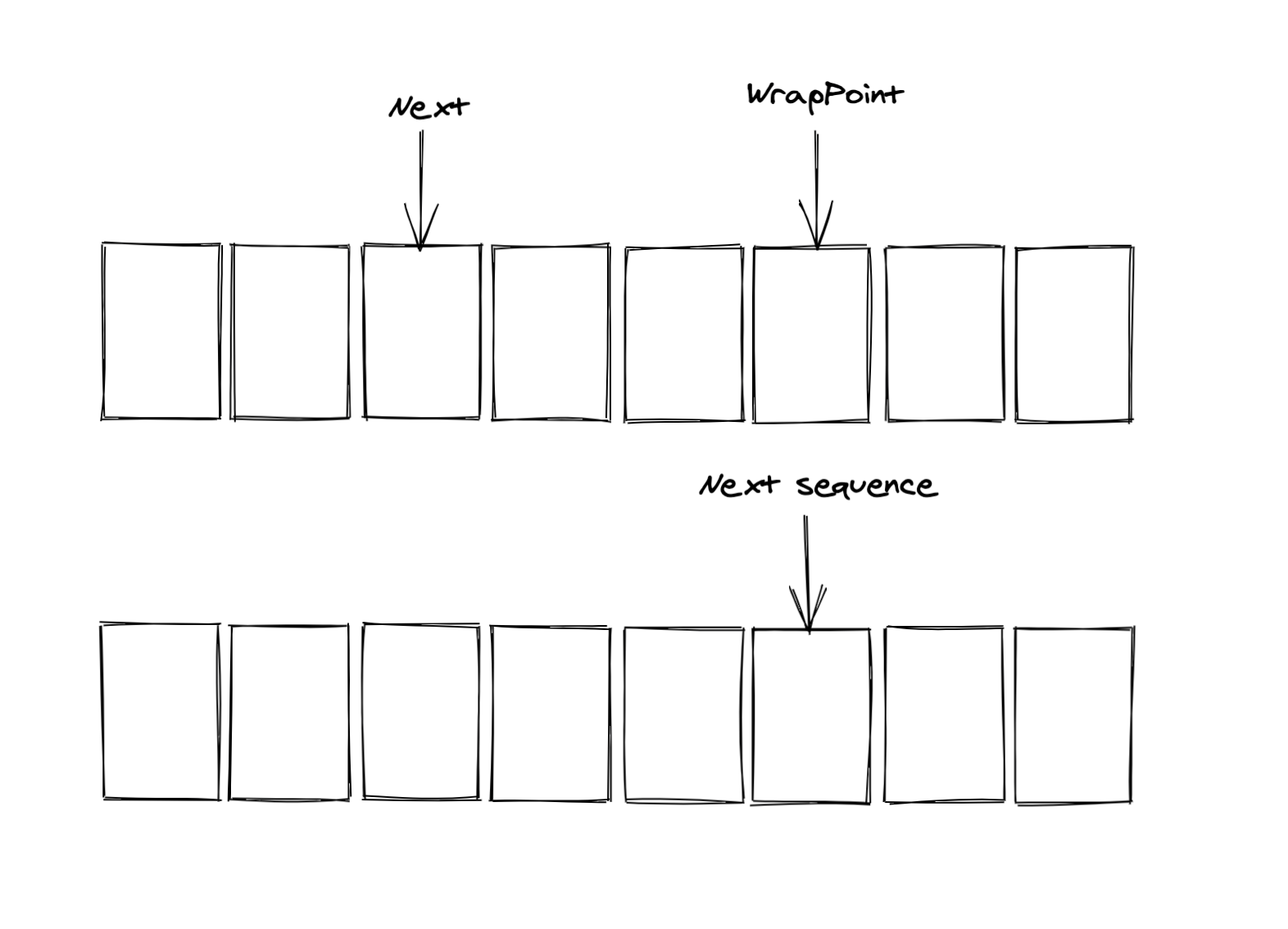
比如上面这种情况,直接bufferSize + 3个position,导致swapPoint比next还大,显然是不行的。
所以条件2:
- wrapPoint要小于nextValue,也即保证n不能大于bufferSize。
这里比较困惑的地方可能就是cachedGatingSequence这个值了,
这个值就是上述两个条件的缓存,这里缓存一下估计也是为了优化吧。
不过写的确实看不太明白。
注意这里的AbstractSequencer中的Sequence cursor这个变量。
这个就是我们说的Sequencer这个变量。
但是在Next方法中,完全没用到这个变量,而是直接用的SingleProducerSequencer中的nextValue
但是在MultiProducerSequencer的实现中,确实强依赖cursor这个变量的。
怎么说呢,可以说设计得不是很友好吧。
我感觉SinleProducerSequencer其实也可以用cursor标记producer的位置,但是这样就引入了CAS,性能并没有那么好。
publish
获取next成功,下面就是publish操作了,让我们看看publish中做了什么
1 | public void publish(long sequence) |
这里的publish比较简单,就是直接设置新的cursor指针就行。
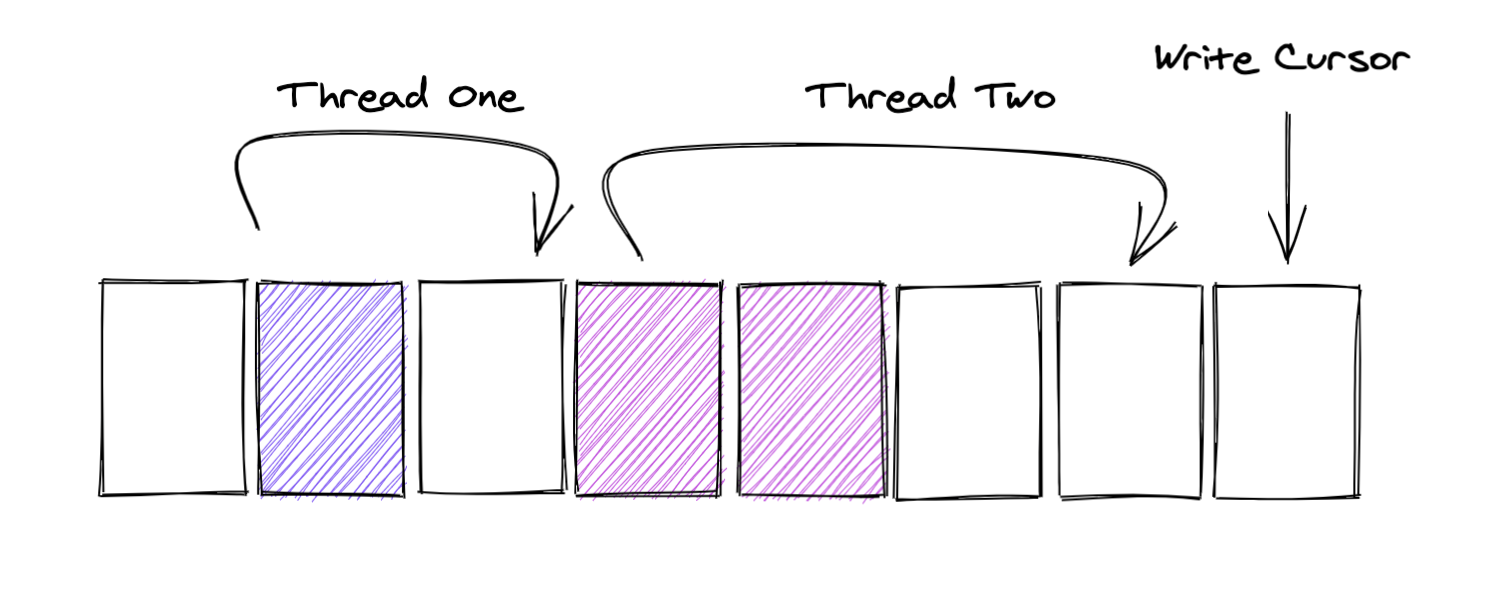
如果你看过上一篇文章,你可能会记得这张图,这里的cursor是大于两个Producer线程的。
但是WriteCursor之前的元素可能还没写入进入。
但是在本地的SingleProducer中,其实流程和这个还不太一致。
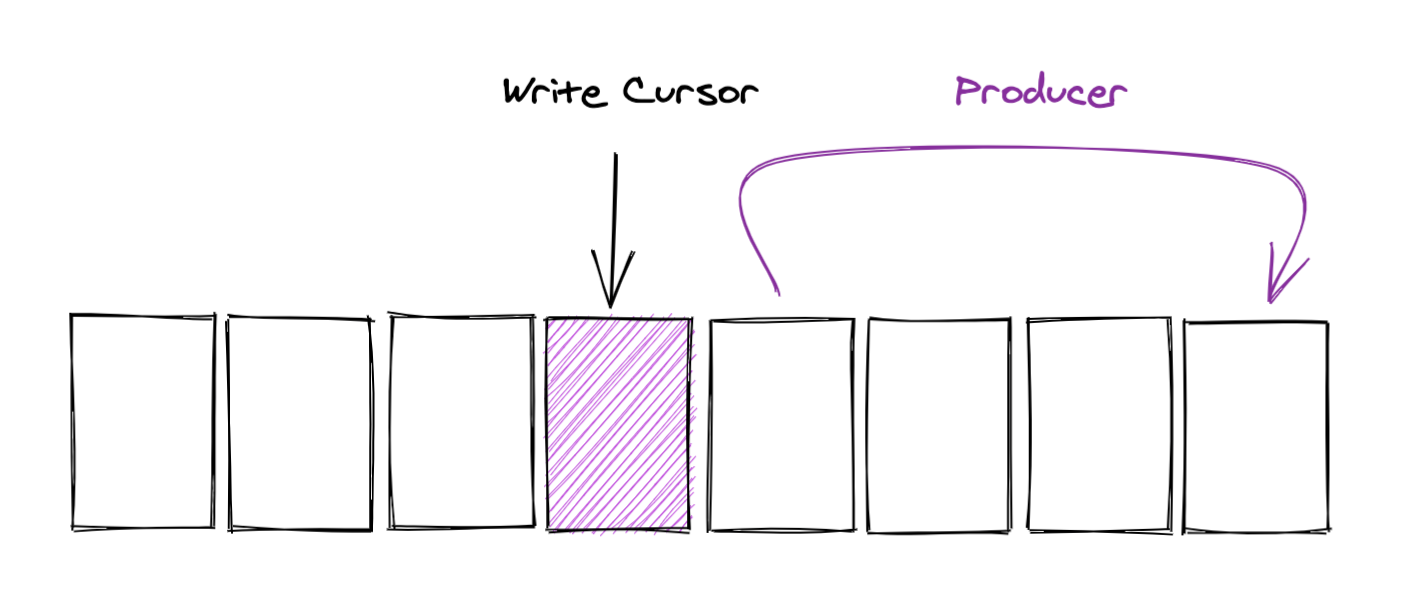
在SingleProducerSequencer中,虽然Producer已经调用成功了next,但是writeCursor仍然停留在之前的位置,每次publish一个position的元素后,writeCusor就往前加一格。
所以使用SingleProducerSequencer时,消费者每次读取的位置中,元素肯定已经被写入了。不会出现读到空的情况。
getHighestPublishedSequence
这个方法,其实是为了对照下面的MultiProducerSequencer而加的。
这个方法的原型是
1 | public long getHighestPublishedSequence(long lowerBound, long availableSequence) |
传入lowerBound和availableSequence,返回最大可用的Seq是什么。
显然就是给消费者使用的。
对于SingleProducer而言,显然是直接返回availableSequence就行。
4.2 MultiProducerSequencer
这个实现类是针对多个Producer。
这里多个Producer争夺Index的变量,就是AbstractSequencer中的Sequence cursor。
next
来看看它的next方法:
1 | public long next(int n) |
是不是感觉很亲切。
其实这里和SinpleProducer的方法并没有什么大的区别。
唯一的问题就是这里的current是可能被多线程访问的,所以每次wrapPoint > gatingSequence,都要重新获取一次。
满足条件后,设置新的WriteIndex,要使用cursor的cas操作,防止多线程操作。
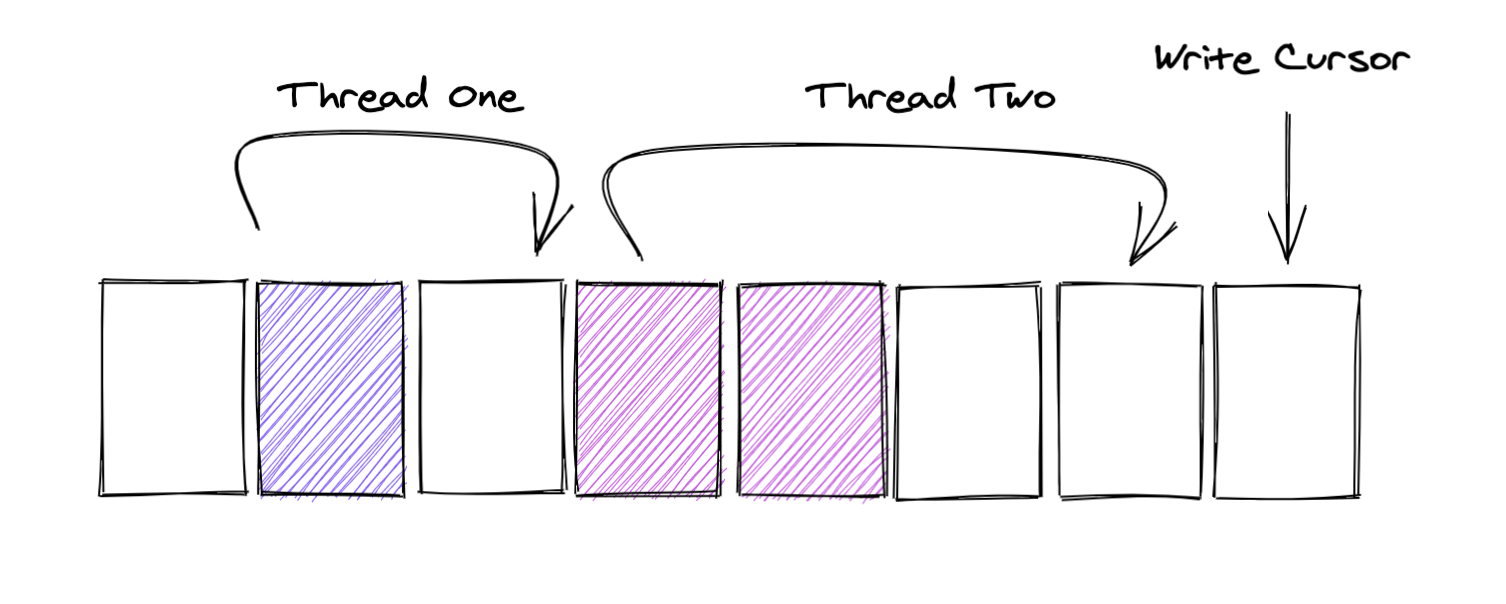
注意这里,在获取next的时候,就已经改动了WriteCursor,所以和SingleProducerSequencer相比,这里有可能出现上图的状态。
如果消费者这个时候,直接读WriteCursor之前的元素,很可能还没有写入成功。
那怎么办呢?
在MultiProducerSequencer中,额外定义了一个数组
private final int[] availableBuffer;
这个数组表示的就是对应的循环数组中元素的写入情况。
具体得我们看看它的publish方法做了什么?
publish
1 | public void publish(final long sequence) |
怎么用一个int表示这个位置的元素已经被写入成功了呢?
我们记得我们的offset计算公式((int) sequence) & indexMask;
而Sequence是每次递增的,不会重复的。
所以原理类似,calculateAvailabilityFlag方法,就是把将Seq稍作变化。
在整个publish方法中,就是把availableBuffer中响应的位置置为写入成功。
getHighestPublishedSequence
对于SingleProducer而言,直接返回availableSequence。
而对于MultiProducer,虽然WriteCursor已经分配好了,但是可能Producer还没有完成赋值。
所以我们需要查阅availableBuffer,看看具体有没有被赋值成功。
1 | public long getHighestPublishedSequence(long lowerBound, long availableSequence) |
具体的实现就是从lowerBound开始,查看每个Seq是否已经可用了,找到第一个不可用的Position。
五. Consumer
这里的Consumer的设计比较复杂,因为需要支持chain的操作。
类似于first().then().finally()的链式处理。
同时还支持不同的EventHandler都处理到同一个消息。
类似于消息队列的消费组的概念。
这里我们简单点,就看三个消费者并发消费的模型。
源码的使用中,我们传入了三个一样的WorkHandler。
最后每个WorkHandler都会通过WorkPool被包装成一个WorkProcessor。
在每个WorkProcessor中,都会有2个Seq。
1 | public final class WorkProcessor<T> { |
- 第一个是自己的,每一个WorkProcessor都会有一个自己的。
- 第二个是所有的WorkProcessor都共享的一个。
SequenceBarrier
这个叫做序号栅栏。
他是消费者和生产者沟通的桥梁。
消费者不能直接读取到生产者的循环数组和WriteCursor。
而是通过Barrier来获取下一段的消费序号。
在这个类中,有个重要的方法叫long waitFor(long sequence)
就是消费者在需要消费时调用的。
比如消费者目前的seq是12,他想要消费13的数据,于是调用waitFor(13)去申请。
1 | public long waitFor(final long sequence) { |
这里的cursorSequence就是AbstractSequencer中的cursor,而dependentSequence是为了支持链式调用而传入的,这里没有相关的依赖,所以它的值和cursorSequence一样。
对于waitStrategy而言,其实就是Consumer等待Producer生产消息的过程。
主要功能就是等待Cursor的Seq是否已经到了我们所要申请的Seq。
并不会做任何同步的逻辑。
但是具体怎么等待,其实是个策略。具体的实现分为下面集中:

有等待超时,忙等待,不满足条件自动block的等待,Sleep的等待方式。
我们简单看一下BusySpinWaitStrategy等待方式:
1 | public final class BusySpinWaitStrategy implements WaitStrategy { |
代码也比较简单,就是不断的轮询Cursor的值,看是否已经生产到想要获取的Cursor。
看完了waitStrategy,我们再回过头看查看序号栅栏的waitFor方法:
1 | public long waitFor(final long sequence) { |
调用waitStrategy查看Cursor是否已经生产到sequence的序列了
因为有Timeout的waitStrategy,所以也可能是超时返回了,并没有满足条件,这里需要做一个判断。
说到这儿,再思考个问题,availableSequence会不会大于sequence呢?
答案是会的,因为这里有Block的waitStrategy,就是等待Producer生产消息后唤醒自己,唤醒完自己后,去读取Cursor的位置,很可能已经比sequence大了。
如果满足了条件,但是因为前文提到过的MultiProducer的问题,我们要找出这段Seq中已经被赋值的最早的位置并返回。
WorkProcessor
WorkProcessor实现了Run方法,在Disruptor调用了start之后,就会提交一份死循环的任务给ThreadPool,在ThreadPool中调用WorkProcessor的run方法:
1 | public void run() |
整体的逻辑分为两段:
- 因为workSequence是所有的WorkProcessor共享的,所以先去获取下一个Position的权限,具体的实现就是CAS不断的读取当前的WorkSequence的值,然后尝试设置下一个值。
- 调用WaitFor,得到availableSequence,看能否执行步骤一获取的Position的元素。
这里的cachedAvailableSequence,就是序号栅栏返回值的缓存。
