20200818补充
- LSM Tree的Leveling 和 Tiering Compaction 文章讲了LSM的多种Compact策略,写的很好
前言
这一节讲述最复杂的Version以及Compact的部分
一. Version和VersionSet
LevelDB算是实现了功能上的多版本控制。利用的是Version和VersionSet两个类。
当然这里的多版本控制肯定不是MVCC那么复杂,这里实现多版本的功能,我理解是为了解决两个操作的冲突:
- 读取和迭代操作
- 后台异步Compact操作
因为LevelDB的compact操作,其实是把多个文件合并成多个文件。
从SSTable那一章节,我们其实知道,一个SSTable就是对应一个文件。
如果我们直接修改文件,那么如果前台有线程正在迭代这个SSTable,就会出现不可预知的错误。
所以这就导致我们的Compact结果的文件需要重新生成,不能动以前的文件。
结果就是每个Level的SSTable集合是随着Compact操作会变化的。
迭代可能是个很长的操作,这中间不能保证不会发生Compact,所以干脆就搞个Version,把每次Compact后的SSTable集合存储起来。
这样迭代的时候,先拿到当前的Version。
DBImpl的Versions和CurrentVersion的初始化变量如下:
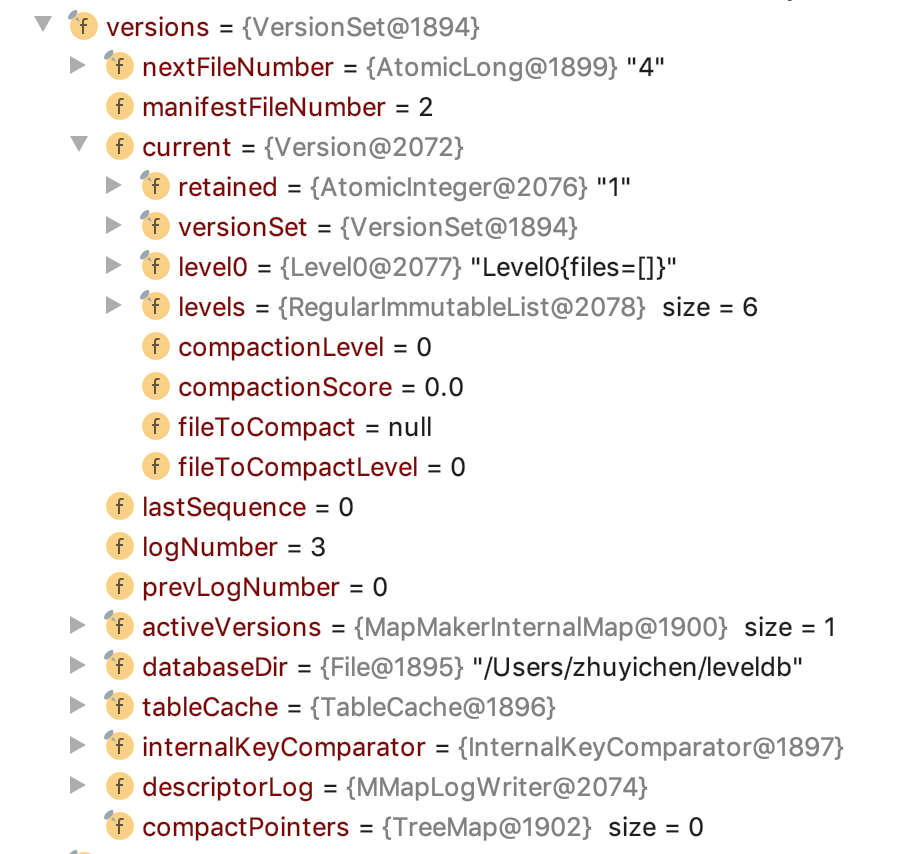
我们先来看Version类中存储的变量:
存储每个Level的SSTable集合:
其中Level0比较特殊,是个单独的类,其他的Level是用了个List存储。
retained表示目前这个Version有没有被正在运行的迭代器使用
剩余的四个都是和Compact有关,下面再讲
再来看看VersionSet中的存储的变量:
- 全局的文件名变量:nextFileNumber,LevelDB创建文件时,根据文件类型和FileNumber就可以定位到具体的File。这里存储这个,类似于数据库中的主键生成器,这里是自增的文件名生成器。
- ManifestFileNumber:Manifest文件可以理解为是存储的当前的Version的持久化信息
- lastSequence:每个写入的Key,都有一个唯一的序号与之对应
- Log模块的配置:logNumber和prevLogNumber,类似于数据库中的WAL模块
- activeVersions:当前被使用的Version有哪些
- compactPointers:进行Compact时,为了保证每个SSTable都有被Compact机会,这个类似于游标,对于同一个Level,每次新Compact时,选择下一批SSTable。
二. Compact
讲完了Version,还有好多坑没填,主要是因为Version和Compact的联系太紧密了,这里将Compact的流程顺便把Version的坑填了。
LevelDB的Compact的代码在DbImpl的backgroundCompaction()中。
具体的Compact其实分为两步:
- 找出需要compact的SSTable集合
- 对这些SSTable进行compact
2.1 SSTable多路归并
其中第一步的代码主要是VersionSet::pickCompaction中,但是触发Compact的情况比较多,这里先不谈了。
直接先来看第二步,我们经过pickCompaction已经找到了需要Compact的SSTable,并且已经生成了Compaction对象:
1 | public class Compaction { |
得到了这些文件之后,下一步就是对这么文件进行合并。
合并的过程其实就是多路归并的过程。
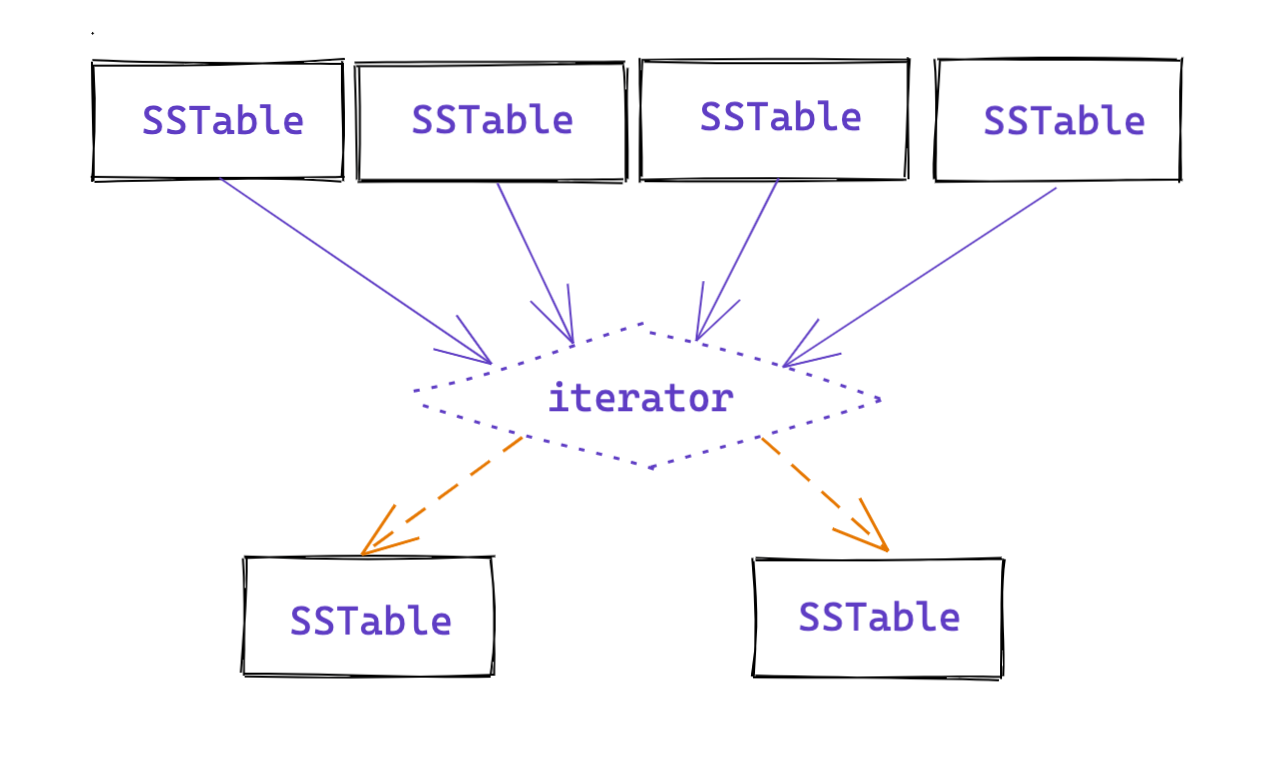
从iterator的视角来看,其实相同的UserKey已经按照seqNum的顺序从大到小排列好了。
所以我们进行迭代的时候,看到的数据大致如下:
1 | 1. UserKey = "foo123", seq = 34,Type=VALUE |
这里我们根据UserKey把数据分为两段,第一段是1-4,UserKey都是”foo123”。
同时由于1的SEQ最大,剩余的都要被drop掉。
第二段是5-7,UserKey都是”foo456”。
这里由于5的seq最大,所以6-7需要被drop掉。
但是5能不能drop呢?
能不能drop需要查找下面所有的Level,是否是该UserKey了,如果没有了,那么可以drop,否则需要保留。
所以这里对迭代的每行数据而言,都需要判断是否能drop。
简略代码如下:
1 | boolean hasCurrentUserKey = false; |
2.2 新的Table生成
讲完了合并是,判断某个Key是否能丢,下面就是生成新SSTable的逻辑了。
对于一个KV,如果drop=false,那么建立一个Table,把它放进去就行了。
这里我们主要关注:
- 新的SSTable在哪一层
- Version是怎么链接到新的SSTable的
顺着源码往下看:
1 | if (!drop) { |
这里的builder就是TableBuilder,如果TableBuilder为空,则新建一个TableBuilder。
openCompactionOutputFile这个方法属于DbIMPL。
1
2
3
4
5
6
7
8
9
10
11
12private void openCompactionOutputFile(CompactionState compactionState) {
long fileNumber = versions.getNextFileNumber();
compactionState.currentFileNumber = fileNumber;
compactionState.currentFileSize = 0;
compactionState.currentSmallest = null;
compactionState.currentLargest = null;
File file = new File(databaseDir, Filename.tableFileName(fileNumber));
compactionState.outfile = new FileOutputStream(file).getChannel();
compactionState.builder = new TableBuilder(options, compactionState.outfile, new InternalUserComparator(internalKeyComparator));
}这个方法中主要做了一件事:初始化新的SSTable的一些信息到compactionState中
当当前的SSTable的大小超过阈值时,结束往这个SSTable添加,准备重启一个SSTable
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27private void finishCompactionOutputFile(CompactionState compactionState) {
long outputNumber = compactionState.currentFileNumber;
long currentEntries = compactionState.builder.getEntryCount();
compactionState.builder.finish();
long currentBytes = compactionState.builder.getFileSize();
compactionState.currentFileSize = currentBytes;
compactionState.totalBytes += currentBytes;
FileMetaData currentFileMetaData = new FileMetaData(compactionState.currentFileNumber,
compactionState.currentFileSize,
compactionState.currentSmallest,
compactionState.currentLargest);
compactionState.outputs.add(currentFileMetaData); //1
compactionState.builder = null;
compactionState.outfile.force(true);
compactionState.outfile.close();
compactionState.outfile = null;
if (currentEntries > 0) {
tableCache.newIterator(outputNumber);
}
}这个方法中,我们主要关注位置1的代码,在CompactionState中,有一个List,用来存储新生成的SSTable的信息。
到这儿,合并过程结束了,我们生成了多个SSTable,在CompactionState的outputs中保存
然后进行最后一步:installCompactionResults(compactionState);
说到这儿,你可能猜到了,下面就是与Version构建连接关系的过程了。
2.3 保存Compact结果
这里不得不插入一个很重要的类,就是VersionEdit。
我们知道后一个Version和前一个Version的主要区别就是SSTable会发生变化,而VersionEdit就是记录这个变化的。
我们可以理解为 NewVersion = OldVersion + VersionEdit;
而在VersionEdit中,也存有两个变量表示SSTable的增减。
1 | public class VersionEdit { |
在installCompactionResults中:主要就是构建VersionEdit。
1 | private void installCompactionResults(CompactionState compact) { |
- 将之前的输入的SSTable放到
VersionEdit的deletedFiles中 - 将新产生的SSTable放到
newFiles中,这里可以看到,新生成的SSTable,放到了level+1层,也就是levelUp层,也就是下一层。
下面就是进入versions.logAndApply方法了,这个方法属于VersionSet类。
在这个方法中,最重要的有几句话:
1 | public void logAndApply(VersionEdit edit) { |
这里的逻辑之前已经分析过了,这里再过一遍整体的流程,主要就是2步:
- 根据当前的Version和传入的VersionEdit,构造新的Version。并且在appendVersion方法中替换current。
- 把VersionEdit写入Manifest文件
2.4 彩蛋
彩蛋:
前面的多路归并生成新的SSTable的流程,具体的某个SSTable结束Build逻辑其实就是判定新的SSTable的大小。
其实源代码中不然,还有一种情况也会触发SSTable生成结束。
不过这种场景,我想了很久都没想通,这里先抛出来:TODO
2.5 Compact触发策略
写到这里,Version,VersionSet和Compact的耦合流程已经理清楚了。
下面就是重点了,设计到策略方面的:如何选择需要合并的SSTable。
我们知道,LevelDB最多有7层Level,每个Level可能有很多SSTable,其中Level0的SSTable的KV是无序的。
如果我们每次都合并某个Level,或者我们每次都合并每个Level的前几个SSTable,必然会导致KV不均的情况。
同时我们还需要机制触发合并流程,不能是配死的规则。
2.5.1 针对Level0的searchMiss的情况
我们知道Level0的SSTable之间的Key并不是顺序的,互相之间可能overlap。那么在查找一个Key的时候,仅仅从最大key和最小key才判断,可能命中好几个SSTable。
比如如下场景的Level0:

我们要查找19这个Key,会发现符合条件的有3个。
我们要查找22这个Key,会发现符合条件的有2个。
遇到超过一个SSTable需要查找的情况,我们认为情况不太好,但是只谈性质不谈次数就是耍流氓。
所以我们给每个SSTable维护一个计数器,指示SearchMiss的次数。
比如我们搜索20,最终在第二个SSTable中搜索到了,那么第一个SSTable就是SearchMiss了,计数器减一。
但是注意,每次搜索,只会将第一个SearchMiss的SSTable的计数器减一。
比如我们查找19这个Key,最终在第三个SSTable中搜索到了,或者3个都没搜索到,也只会将第一个SSTable的SearchMiss计数器减一。
来看源代码:
1 | Version::get(LookupKey key) |
- 这里的ReadStats保存的是第一个SearchMiss的SSTable。
- 搜索Level0
- 搜索Level1往下的,但是这里面因为SSTable都是有序的,所有不会出现SearchMiss的情况,也就是不会更新ReadStats
- 更新stats,传入的是SearchMiss的SSTable的Level和FileMetaData
- 在updateStats方法中,将SearchMiss的数值减一,这个值初始为1 << 30,不是很小其实,这个阈值还是很难达到的,达到了表示有热点Key了。
- fileToCompact和fileToCompactLevel是Version的成员变量,在下一个pickCompact时会考虑这两个值。
2.5.2 根据每个Level的文件个数和字节大小
从Level0到Level7,作为LSM来看的话,越往下的Level的KV数应该是越多的。所以如果中间某个Level的KV数超过某个阈值,就要Compact到下一个Level。
同时Level0因为无序,对他而言,SSTable如果超过一定的个数,也要进行Compact。
总结一下就是,选择下一次的Compact的SSTable:
- Level0的SSTable个数
- 其他Level的KV个数,也就是等价于Bytes个数
于是我们给每个Level打个分,分越高表示越需要尽快Compact。
在VersionSet的finalizeVersion方法中,就是给每个Level打分,选出下一个需要Compact的Level。
1 | private void finalizeVersion(Version version) { |
假如我们选出了得分最高的,比如Level3,但是Level3中可能有100个SSTable,具体怎么选择呢?
是固定选择第一个SSTable,但是最后一个,还是中间1个?
或者选择其中的几个?随机几个吗?
LevelDB为为每个Level维护了一个Compact进度的游标,这个变量叫compactPointers,维护在VersionSet和VersionEdit中,因为维护在了VersionEdit中了,所以每次Compact完会写入Manifest文件中,重新启动的时候会恢复出来。
1 | private final Map<Integer, InternalKey> compactPointers = new TreeMap<>(); |
定义如上,Key是Level的值,Value是具体的InternalKey。
具体流程如下:
- 根据finalizeVersion的结果,找个该Level。
- 遍历该Level下的所有文件,找到第一个LargestKey大于compactPointers中该Level的Value的SSTable
- 以这一个SSTable作为Base,寻找Level + 1 层有overlap的SSTable
- 更新compactPointers该Level的结果,Value更新为pick中的SSTable的LargestKey。下一次查找的时候就是顺位的下一个SSTable。
- 将这些SSTable进行Compact。
这里为什么维护这种游标呢?是让每个SSTable都有机会进行Compact吗?
其实我理解是为了LevelDB中所有的Key的分布在每个Level都更均匀。
如果每次都Compact第一个SSTable,那么所有Key靠前的都会被优先Compact到下一层。
查询的时候很容易就找到了最后一个Level。
维护了这种游标之后,每个Level的Key分布都均匀的向下Compact。
2.6 pickCompact方法源码
综合上面的两种情况,我们最后可以来看pickCompact方法了,代码比较多,但是如果上面的都理解了,还是比较好懂的。
1 | public Compaction pickCompaction() { |
