标题
What’s Really New with NewSQL?
Andrew Pavlo Carnegie Mellon University pavlo@cs.cmu.edu
Matthew Aslett 451 Research matthew.aslett@451research.com
摘要
一类新的数据库管理系统(DBMSs)被称为NewSQL,它声称自己有能力以传统系统所不具备的方式扩展现代在线交易处理(OLTP)的工作负载。
这篇论文的作者之一(论文的两位作者分别是pavlo和matthew.aslett)在2011年的一份商业分析报告中首次使用了NewSQL这个术语,该报告讨论了新的数据库系统作为对这些老牌厂商(Oracle、IBM、微软)的挑战者的崛起。
而另一位作者则是第一批研究NewSQL DBMS的人。
从那时起,一些公司和研究项目都用这个词来描述他们的系统(无论他们是否使用正确)。
考虑到关系型DBMS已经有四十多年的历史,我们有理由问一下,NewSQL的优越性的说法是真的,还是仅仅是营销手段。
如果它们确实能够获得更好的性能,那么接下来的问题是,它们是否有什么新技术使它们能够获得这些优势,还是说硬件已经进步了很多,以至于现在早些年的瓶颈不再是问题。
为了做到这一点,我们首先讨论数据库的历史,以说明NewSQL系统是如何产生的。
然后,我们将详细解释NewSQL这个词的含义,以及属于这个定义下的不同类别的系统。
1. DBMS简史
最早的DBMS是在1960年代中期上线的。
最早的其中一个是IBM的IMS系统,用于跟踪土星五号和阿波罗太空探索项目的物资和零件库存。
它引入了应用程序的代码应该和它所操作的数据分开的理念。这使得开发人员可以编写的应用程序只关注数据的访问和操作,而不是与如何实际执行这些操作相关的复杂性和开销。
IMS之后,在20世纪70年代初,IBM公司的System R和加州大学的INGRES等第一批关系型DBMS的开创性工作也随之而来。INGRES很快被其他大学的信息系统所采用,并在70年代末实现了商业化。
大约在同一时间,甲骨文公司发布了他们的第一个DBMS版本,与System R的设计相似。
1980年代初,其他的公司也纷纷成立,试图重复第一批商业化DBMS的成功,包括Sybase和Informix。
尽管IBM从未向公众提供过System R,但它后来在1983年发布了一个新的关系型DBMS (DB2),其使用了System R的部分代码库。
20世纪80年代末和90年代初诞生了一类新的DBMS,这些DBMS的设计是为了克服关系模型和面向对象编程语言之间的阻抗不匹配的问题。
然而,这些面向对象的DBMS从未在市场上得到广泛的应用,因为它们缺乏像SQL那样的标准接口。
但是当十年后各大厂商增加了对对象和XML的支持时,其中的许多想法最终被纳入到了面向对象的
DBMS中,20多年后又在面向文档的NoSQL系统中再次被纳入。
在90年代,另一个值得注意的事件是今天的两个主要的开源DBMS项目的开始。
MySQL是1995年在瑞典开始的,它是基于早期基于ISAM的mSQL系统。
PostgreSQL开始于1994年,当时两个伯克利大学的研究生fork了20世纪80年代原始的基于QUEL的Post-gres代码,增加了对SQL的支持。
2000年代,互联网应用的出现,对硬件资源的要求比前几年的应用更具挑战性。
它们需要扩大规模以支持大量的并发用户,并且必须一直在线。
但这些新应用使用的数据库一直是一个瓶颈,因为资源需求远远超过了当时的DBMS和硬件所能支持的范围。
许多人尝试了最简单的选择,即通过将数据库移动到具有更好的硬件的机器上,垂直扩展他们的DBMS。
然而,这样做只能提高性能,回报率却越来越低。
此外,将数据库从一台机器移动到另一台机器是一个复杂的过程,往往需要大量的停机时间,这对于这些基于Web的应用来说是不可接受的。
为了克服这个问题,一些公司创建了定制的中间件,将单节点的DBMS分片到成本较低的机器集群上。这样的中间件向应用程序展示了一个存储在多个物理节点上的单一逻辑数据库。
当应用程序针对这个数据库发出查询时,中间件会重定向和/或重写它们,将它们分配到集群中的一个或多个节点上执行。
节点执行这些查询,并将结果发送回中间件,中间件再将其汇总成一个单一的响应给应用。
这种中间件方法的两个显著例子是eBay的基于Oracle的集群和Google的基于MySQL的集群。
这种方法后来被Facebook采用,他们自己的MySQL集群至今仍在使用。
Sharding 中间件对于简单的操作,如读取或更新一条记录,效果很好。
但要在事务或联接表中执行更新一条以上记录的查询则比较困难。
因此,这些早期的中间件系统并不支持这些类型的操作。例如,eBay在2002年的中间件,要求其开发人员在应用级代码中实现所有的join操作。
最终,这些公司中的一些脱离了中间件,开发了自己的分布式DBMS。
这样做的动机有三个方面。
最重要的是,当时传统的DBMS注重一致性和正确性,而牺牲了可用性和性能。但这种权衡被认为不适合于需要一直在线并需要进行大量并发操作的基于Web的应用程序。
其次,有人认为使用像MySQL这样的全功能DBMS作为 “哑巴 “数据存储,会有太多的开销。
同样,也有人认为关系型模型不是表示应用程序数据的最佳方式,使用SQL对于简单的查询查询来说是一种过度的做法。
这些问题被证明是2000年代中后期NoSQL1运动的推动力的起源。
这些NoSQL系统的核心是放弃了传统DBMS的强大的事务保证和关系模型,而倾向于最终的一致性和替代性数据模型(例如,键/值、图、文档)。
这是因为有些人认为,现有的DBMS的特点抑制了它们的扩展能力和实现Web的应用所需的高可用
性。
最早遵循这一信条最著名的两个系统是Google的BigTable和Amazon的Dynamo。
这两个系统一开始都不在各自公司之外出现(尽管它们现在是以云服务的形式出现),因此,其他组织创建了自己的开源克隆系统。
这些包括Facebook的Cassandra(基于BigTable和Dynamo)和PowerSet的Hbase(基于BigTable)。
其他初创公司创建了自己的系统,这些系统不一定是Google或Amazon的系统的复制品,但仍然遵循NoSQL哲学的原则;其中最著名的是MongoDB。
到了2000年代末,现在已经有了多种多样的、可扩展的、更实惠的分布式DBMS。
使用NoSQL系统的好处是,开发人员可以专注于他们的应用中对他们的业务或组织更有利的方面,而不必担心如何扩展DBMS。
然而,许多应用无法使用这些NoSQL系统,因为它们不能放弃强大的交易和一致性要求。
这种情况对于处理高等级数据的企业系统(例如,财务和订单处理系统)很常见。
一些组织,最明显的是Google,发现NoSQL DBMS导致他们的开发人员花了太多时间编写代码来处理一致的数据,而使用事务使他们的工作效率更高,因为它们提供了一个有用的抽象,更容易被人类理解。
因此,这些组织唯一的选择是,要么购买更强大的单节点机器,并对DBMS进行动态扩展,要么开发自己的支持事务的自定义分片中间件。
这两种方法都非常昂贵,因此对很多人来说都不是一个选择。正是在这种环境下,NewSQL系统应运而生。
2. NewSQL的崛起
我们对NewSQL的定义是,它们是一类现代关系型DBMS,试图为OLTP读写工作负载提供与NoSQL相同的可扩展性能,同时仍然保持事务的ACID保证。
换句话说,这些系统希望实现与2000年代的NoSQL DBMS一样的可扩展性,但仍然保持1970-80年代的传统DBMS的关系模型(带SQL)和事务支持。
这使得应用程序可以执行大量的并发事务来获取新的信息,并使用SQL(代替专有的API)修改数据库的状态。
如果一个应用程序使用了NewSQL DBMS,那么开发人员就不需要像在NoSQL系统中那样编写逻辑来处理最终一致的更新。
正如我们在下面讨论的那样,这种解释涵盖了许多学术和商业系统。
我们注意到,在2000年代中期,有一些人认为符合这个标准的数据仓库DBMS出现了(如Vertica、Greenplum、Aster Data)。
这些DBMS针对的是在线分析处理(OLAP)工作负载,不应该被认为是NewSQL系统。
OLAP DBMS专注于执行复杂的只读查询(即聚合、多路join),这些查询需要很长时间来处理大数据集(例如,几秒钟甚至几分钟)。
这些查询中的每个查询都可能与前者有明显的不同。
另一方面,NewSQL DBMS所针对的应用的特点是执行读写事务,这些事务(1)是短暂的(即没有用户停顿),(2)使用索引查找触及一小部分数据(即没有完整的表扫描或大型分布式join),(3)是重复性的(即用不同的输入执行相同的查询)。
其他的人认为,NewSQL系统的实现必须使用(1)无锁并发控制方案和(2)无共享的分布式架构。
所有我们在第3节中将其归类为NewSQL的DBMS确实具有这些属性,因此我们同意这一定义。
3. NewSQL分类
鉴于上述定义,我们现在来看看今天的NewSQL DBMS的情况。
为了简化分析,我们将根据系统的优点对系统进行分类。
我们认为最能代表NewSQL系统的三类是:(1)使用新的架构从头开始构建的新型系统,(2)重新实现与Google等人在2000年代开发的分片基础架构相同的中间件,以及(3)同样基于新架构的云计算供应商提供的数据库即服务。
两位作者之前都将替换现有的单节点DBMS的存储引擎的方案纳入了我们对NewSQL系统的分类中。
其中最常见的例子是对MySQL默认的InnoDB存储引擎的替代(例如TokuDB、ScaleDB、Akiban、deepSQL)。
使用新引擎的好处是,企业可以获得更好的性能,而不需要改变他们的应用中的任何东西,并且仍然可以利用DBMS的现有生态系统(如工具、API)。
其中最有趣的是ScaleDB,因为它通过在存储引擎之间重新分配执行,在不使用中间件的情况下提供了透明的分片,而不需要使用中间件;不过,该公司后来转向了另一个领域。
除了MySQL之外,还有其他类似的系统扩展。
微软为SQL Server的内存中的Hekaton OLTP引擎几乎与传统的磁盘驻留表无缝集成。
其他的引擎则使用Postgres的外来数据封装器和API钩子来实现相同类型的集成,但以OLAP工作负载为目标(如Vitesse、CitusDB)。
我们现在断定,这样的存储引擎和单节点DBMS的扩展并不代表NewSQL系统,因此我们将其从我们的分类中省略。
MySQL的InnoDB在可靠性和性能方面已经有了很大的改进,所以切换到另一个引擎用于OLTP应用的好处并不明显。
我们承认,从面向行的InnoDB引擎切换到OLAP工作负载的列存储引擎的好处更明显(例如Infobright、InfiniDB)。
但总的来说,针对OLTP工作负载的MySQL存储引擎替换业务是失败的数据库项目的墓地。
3.1 采用新型架构
这一类包含了对我们来说最有趣的NewSQL系统,因为它们都是从头开始构建的。
也就是说,它们不是扩展现有的系统(例如,基于微软SQL Server的Hekaton),而是从一个新的代码库中设计出来的,没有传统系统的任何架构包袱。
这一类中的所有DBMS都是基于分布式架构的,它们在shared-nothing的架构上运行,并包含支持多节点并发控制、基于复制的错误容忍、流程控制和分布式查询处理的组件。
使用为分布式处理而构建的新DBMS的优势在于,系统的所有部分都可以针对多节点环境进行优化。
这包括查询优化器和节点之间的通信协议等。
例如,大多数NewSQL DBMS能够在节点之间直接发送节点内的查询数据,而不是像一些中间件系统那样将数据路由到中心位置。
这类DBMS中的每一个DBMS(除了Google Spanner之外)也都管理着自己的主存储系统,无论是内存中的还是磁盘上的。
这意味着他们用一个定制的存储引擎,并在其中分配数据库,而不是依赖现成的分布式文件系统(如HDFS)或存储结构(如Apache Ignite)。
这是它们的非常重要的一点,因为它允许DBMS “把查询送到数据中去”,而不是 “把数据带到查询中去”,这样做的结果是大大减少了网络流量,因为传输查询通常比必须把数据(不仅仅是图元,还包括索引和物化视图)传输到计算中去的网络流量要少得多。
管理自己的存储也使 DBMS 能够采用比 HDFS 中使用的基于块的复制方案更复杂的复制方案。
一般来说,它允许这些DBMS比其他建立在其他现有技术之上的系统获得更好的性能;这方面的例子包括像Trafodion和Splice Machine这样的 “SQL on Hadoop “系统,它们在Hbase之上提供事务处理。
因此,我们认为这样的系统不应该被认为是NewSQL。
但是,使用基于新架构的DBMS也有其弊端。
最重要的是,很多公司对采用太新的技术抱有戒心,还未被大规模使用。
这意味着与更受欢迎的DBMS厂商相比,有经验的人要少得多。
这也意味着企业将有可能无法访问现有管理和报告工具。
一些DBMS,如Clustrix和MemSQL,通过保持与MySQL线协议的兼容性来避免这个问题。
比如: Clustrix, CockroachDB, Google Spanner, H-Store, HyPer, MemSQL, NuoDB, SAP HANA, VoltDB.
3.2 透明的分片中间件
现在有一些产品可以提供与eBay、Google、Facebook和其他公司在2000年代开发的同类分片中间件功能。
这些产品允许一个公司将数据库分割成多个分片,这些分片存储在一个单节点的DBMS实例集群中。
Sharding技术与20世纪90年代的数据库联盟技术不同,因为每个节点(1)运行着相同的DBMS,(2)只有整体数据库的一部分,(3)不是由应用程序独立地访问和更新。
集中化的中间件组件负责路由查询、协同管理事务,以及管理节点间的数据放置、复制和分区。
通常,每个DBMS节点上都安装有一个与中间件通信的shim层。
这个组件负责在其本地DBMS实例中代表中间件执行查询并返回结果。
所有这些加在一起,使得中间件产品可以向应用程序展示一个单一的逻辑数据库,而不需要修改底层DBMS。
使用分片式中间件的关键优势在于,它们通常是对已经在使用现有单节点DBMS的应用程序的即插即用替代。
开发人员不需要对他们的应用程序做任何改动,就可以使用新的分片数据库。
中间件系统最常见的目标是MySQL。
这意味着,为了与MySQL兼容,中间件必须支持MySQL线协议。
Oracle提供了MySQL Proxy和Fabric工具包来完成这个任务,但其他的人也编写了自己的协议处理程序库,以避免GPL许可问题。
尽管中间件使企业很容易将数据库扩展到多个节点上,但这样的系统仍然必须在每个节点上使用传统的DBMS(如MySQL、Postgres、Oracle)。
这些DBMS是基于20世纪70年代开发的面向磁盘的架构,因此它们不能像一些基于新架构的NewSQL系统中那样,使用面向内存的存储管理器或并发控制方案进行优化。
之前的研究表明,面向磁盘的架构的组件是一个重要的障碍,使这些传统的DBMS无法扩展到更高的CPU内核数和更大的内存容量。
中间件的方法也会在碎片化的节点上产生冗余的查询规划和优化(即在中间件上和单个DBMS节点上分别进行一次查询),但这也允许每个节点对每个查询应用自己的本地优化。
例如: AgilData Scalable Cluster 2, MariaDB MaxScale, ScaleArc, ScaleBase3.
3.3 Database-as-a-Service
最后,还有一些云计算供应商提供NewSQL数据库即服务(DBaaS)产品。
通过这些服务,企业无需在自己的私有硬件或云托管的虚拟机(VM)上维护DBMS。
相反,DBaaS提供商负责维护数据库的物理配置,包括系统调整(如缓冲池大小)、复制和备份。
客户将获得一个连接到DBMS的URL,以及一个仪表板或API来控制数据库系统。
DBaaS的用户根据其预期的应用程序的资源利用率支付费用。
由于数据库不同的查询语句在使用计算资源的方式上有很大的差异,因此DBaaS提供商通常不会像在面向块的存储服务(如亚马逊的S3、谷歌的云存储)中那样,以同样的方式来计量查询调用。
取而代之的是,客户订阅一个定价层,该定价层指定了提供商将保证的最大资源利用率阈值(例如,存储大小、计算能力、内存分配)。
与云计算的因素一样,由于经济规模限制,DBaaS领域的主要参与者仍然是最大的那几个公司。
但几乎所有的DBaaS都只是提供了传统的单节点DBMS(如MySQL)的托管实例:著名的例子包括Google Cloud SQL、Microsoft Azure SQL、Rackspace云数据库和Sales-force Heroku。
我们不认为这些都是NewSQL系统,因为它们使用的是基于20世纪70年代架构的面向磁盘的DBMS。
一些厂商,如微软,对他们的DBMS进行了改造,为多租户部署提供了更好的支持。
相反,我们只把那些基于新架构的DBaaS产品视为NewSQL。
最显著的例子是Amazon的Aurora为他们的MySQL RDS。
与InnoDB相比,它的显著特点是使用日志结构化存储管理器来提高I/O并行性。
还有一些公司不维护自己的数据中心,而是销售运行在这些公共云平台之上的DBaaS软件。
ClearDB提供了自己的定制DBaaS,可以部署在所有主要的云平台上。
这样做的好处是可以将数据库分布在同一地理区域的不同供应商之间,避免因服务中断而造成的停机。
截至2016年,Aurora和ClearDB是这个NewSQL类别中仅有的两个产品。
我们注意到,这个领域的几家公司已经失败了(例如,GenieDB、Xeround),迫使他们的客户争相寻找新的提供商,并在这些DBaaS被关闭之前将数据迁移出这些DBaaS。
我们将其失败的原因归结为超前于市场需求,以及被各大厂商压价。
Examples: Amazon Aurora, ClearDB.
4. NewSQL现状
接下来,我们讨论NewSQL DBMS的特点,以说明这些系统中的新奇之处(如果有的话)。
我们的分析总结如表1所示。
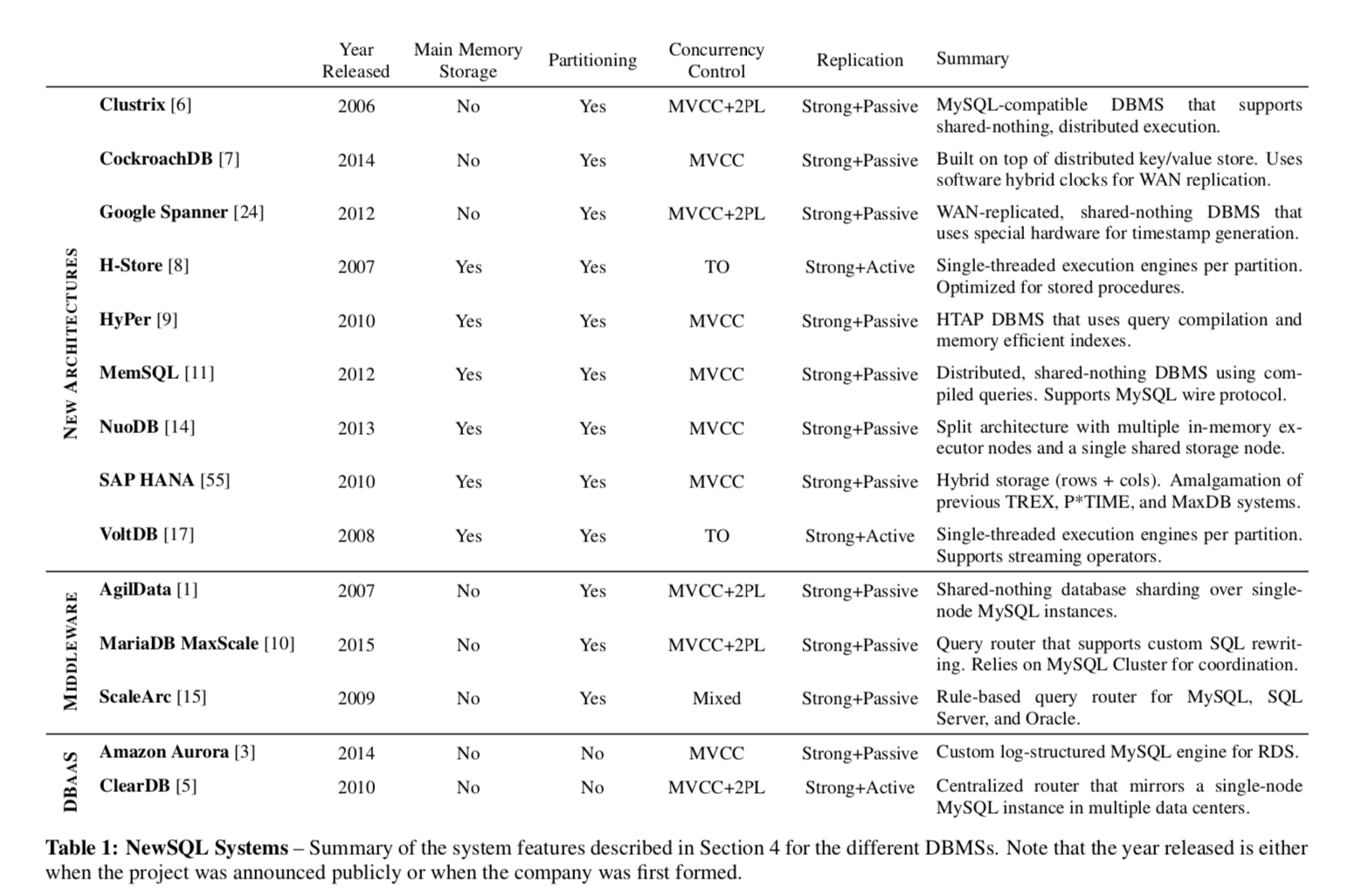
4.1 内存存储
所有主要的DBMS都使用了基于70年代原始DBMS的面向磁盘的存储架构。
在这些系统中,数据库的主要存储位置被认为是在一个可块寻址的耐用存储设备上,如SSD或HDD。
由于对这些存储设备的读写速度很慢,因此DBMS使用内存来缓存从磁盘上读取的块,并缓冲事务的更新。
这是很有必要的,因为历史上,内存的价格要贵得多,而且容量有限。
然而,当下容量和价格已经到了可以完全用内存来存储所有的OLTP数据库的地步,但最大的OLTP数据库除外。
这种方法的好处是,它可以实现某些优化,因为DBMS不再需要假设一个事务可能在任何时候访问不在内存中的数据而不得不停滞不前。
因此,这些系统可以获得更好的性能,因为许多处理这些情况所需要的组件,如缓冲池管理器或重量级并发控制方案等,都不需要了。
有几种基于内存存储架构的NewSQL DBMS,包括学术型(如H-Store、HyPer)和商业型(如MemSQL、SAP HANA、VoltDB)系统。
这些系统在OLTP工作负载方面的表现明显优于基于磁盘的DBMS,因为使用内存的原因。
完全在内存中存储数据库的想法并不是一个新的想法。
20世纪80年代初,威斯康星大学麦迪逊分校的开创性研究为主内存DBMS的许多方面奠定了基础,包括索引、查询处理和恢复算法。
在这十年中,第一个分布式主内存DBMS->PRISMA/DB,也是在这十年中开发出来的。
第一批商业化的主内存DBMS出现在20世纪90年代,如Altibase、Oracle的TimesTen和AT&T的DataBlitz。
在内存NewSQL系统中,有一件事是具有创新的,那就是能够将数据库的子集持久化到持久化存储中,以减少其内存占用。
这使得DBMS能够支持比可用内存更大的数据库,而不必切换回面向磁盘的架构。
一般的方法是在系统内部使用一个内部跟踪机制来识别哪些数据行不再被访问,然后选择它们进行持久化。
H-Store的反缓存组件将冷数据移动到磁盘存储,然后在数据库中安装一个带有原始数据位置的 “墓碑 “记录。
当一个事务试图通过其中一个墓碑访问一行记录时,它会被中止,然后一个单独的线程异步检索该记录并将其移回内存。
另一个支持大于内存的数据库的变体是EPFL的一个学术项目,它在VoltDB中使用操作系统虚拟内存分页。
为了避免误报,所有这些DBMS都在数据库的索引中保留了被持久化的数据行的键,这抑制了那些有许多二级索引的应用程序的潜在内存节省。(就是有许多二级索引的表的也没怎么节省内存)
虽然不是NewSQL DBMS,但微软为Hekaton开发的Project Siberia在每个索引中保留了一个Bloom过滤器,以减少跟踪被持久化的数据行的内存存储开销。
另一个对内存数据库采取不同的方法的是MemSQL,管理员可以手动指示DBMS以列式格式存储一个表。
MemSQL不为这些磁盘驻留的数据行维护任何内存跟踪元数据。
它以日志结构化(log-structured)存储的方式组织这些数据,以减少更新的开销,因为在OLAP数据仓库中,更新速度传统上是很慢的。
4.2 分区/分片
几乎所有的分布式NewSQL DBMS 的扩展方式都是将数据库分割成不相干的子集,称为分区或分片。
基于分区数据库上的分布式事务处理并不是一个新概念。
这些系统的许多基本原理来自于伟大的Phil Bernstein(和其他人)在1970年代末的SDD-1项目中的开创性工作。
在20世纪80年代初,两个开创性的单节点DBMS的背后团队—System R和INGRES,也都创建了各自系统的分布式版本。
IBM的R*是一个类似于SDD-1的shared-nothing、面向磁盘的分布式DBMS。
INGRES的分布式版本的动态查询优化算法将分布式查询递归分解成更小的块而被人记住。
后来,威斯康星大学麦迪逊分校的GAMMA项目探索了不同的分区策略。
但是,这些早期的分布式DBMS始终没有得到普及,原因有两个。
其中第一个原因是20世纪的计算硬件非常昂贵,以至于大多数公司无法负担得起在集群机器上部署数据库。
第二个问题是,对高性能分布式DBMS的应用需求根本不存在。
当时,DBMS的预期峰值吞吐量通常以每秒几十到几百个事务来衡量。
而当今社会,这两种假设都不存在了。
现在创建一个大规模的、数据密集型的应用比以往任何时候都要容易,部分原因在于开源的分布式系统工具、云计算平台和大量的廉价的移动设备的出现。
数据库的表被水平地分成多个分片,其边界基于表的一个(或多个)列的值(即分区属性)。
DBMS根据这些属性的值将每行数据分配到一个分片,使用范围或哈希分区法将每行记录分配到一个分片。
来自多个表的相关分片被组合在一起,形成一个由单个节点管理的分区。
该节点负责执行任何需要访问其分区中存储的数据的查询。
只有DBaaS系统(Amazon Aurora、ClearDB)不支持这种类型的分区。
理想情况下,DBMS也应该能够将一个查询的执行分配到多个分区,然后将它们的结果合并成一个结果。
除了ScaleArc之外,所有支持原生分区的NewSQL系统都提供了这种功能。
许多OLTP应用的数据库都有一个关键的属性,使其可以进行分区。
它们的数据库模式可以被移植到类似于树状的结构中,其中树的子节点与树根有外键关系。
然后根据这些关系中所涉及的属性对表进行分区,这样一来,单个实体的所有数据都被共同定位在同一个分区中。
例如,树的根可以是客户表,而数据库的分区是这样的,每个客户以及他们的订单记录和账户信息都存储在一起。
这样做的好处是,它允许大多数(如果不是全部)事务只需要在一个分区访问数据。
这反过来又降低了系统的通信开销,因为它不需要使用原子承诺协议(例如,两阶段承诺)来确保事务在不同的节点上正确完成。
偏离同源集群节点架构的NewSQL DBMS有NuoDB和MemSQL。
对于NuoDB来说,它指定一个或多个节点作为存储管理器(SM),每个节点存储数据库的一个分区。
SM的分区分为块(NuoDB中称为 “原子”)。
集群中所有其他节点都被指定为事务引擎(TE),作为原子的内存缓存。
为了处理一个查询,一个TE节点会检索它所需要的所有原子(从相应的SMs或其他TE中检索)。
TE 会在数据行上获取写锁,然后将原子的任何更改广播给其他 TE 和 SM。
为了避免原子在节点之间来回移动,NuoDB采用了负载平衡方案来确保一起使用的数据经常驻留在同一个TE上。
这意味着NuoDB最终采用了和其他分布式DBMS一样的分区方案,但不需要预先对数据库进行分区,也不需要识别表之间的关系。
MemSQL也使用了类似的异构架构,由只执行的聚合节点和存储实际数据的叶子节点组成。
这两个系统的区别在于它们如何减少从存储节点拉到执行节点的数据量。
在NuoDB中,TE缓存数据(atoms)来减少从SM读取的数据量。
MemSQL的聚合器节点不缓存任何数据,但叶子节点执行部分查询,以减少发送至聚合器节点的数据量;而在NuoDB中,这一点是不可能的,因为SM只是一个数据存储。
这两个系统能够在DBMS的集群中增加额外的执行资源(NuoDB的TE节点、MemSQL的聚合节点),而不需要重新划分数据库。
SAP HANA的一个研究原型也探索了使用这种方法。
然而,这样的异构架构在性能或操作复杂性方面是否优于同源架构(即每个节点既存储数据又执行查询),还有待观察。
NewSQL系统中分区的另一个创新的方面是,有些系统支持实时迁移。
这使得DBMS可以在物理资源之间移动数据来重新平衡和缓解热点,或者在不中断服务的情况下增加/减少DBMS的容量。
这与NoSQL系统中的再平衡类似,但难度较大,因为NewSQL DBMS在迁移过程中必须保持事务的ACID。
DBMS有两种方法来实现这个目标。
第一种是将数据库组织成许多粗粒度的 “虚拟”(即逻辑)分区,这些分区分布在物理节点之间。
然后,当DBMS需要重新平衡时,它将这些虚拟分区在节点之间移动。这是Clustrix和AgilData,以及Cassandra和DynamoDB等NoSQL系统中使用的方法。
另一种方法是DBMS通过范围分区来重新分配单个图例或图例组,以执行更精细的再平衡。这类似于MongoDB NoSQL DBMS中的自动分片功能。它在ScaleBase和H-Store等系统中得到了应用。
4.3 并发控制
并发控制方案是事务处理DBMS中最重要的实现细节,因为它几乎影响到系统的所有方面。
并发控制允许终端用户并发的访问数据库,同时给每个用户一种假象,让他们以为在只有自己在单独执行事务。
它本质上提供了系统中的原子性和隔离保证,因此它影响着整个系统的行为。
除了系统采用哪种并发控制方案外,分布式DBMS设计的另一个重要方面是系统采用中心化还是去中心化事务协调协议。
在一个采用中心化协调器的系统中,所有事务的操作都必须经过协调器,然后由协调器决定是否允许事务进行。
这与20世纪70-80年代的TP监控器(如IBM CICS、Oracle Tuxedo)采用的方法相同。
在一个去中心化的系统中,每个节点维护访问它所管理的数据的事务的状态。
然后,各节点之间必须相互协调,以确定并发事务是否冲突。
去中心化协调器的可扩展性更好,但要求DBMS节点中的时钟高度同步,以产生全局性的事务排序。
1970-80年代的第一批分布式DBMS使用了两阶段锁定(2PL)方案。
SDD-1是第一个专门为分布式事务处理而设计的DBMS,它是由一个中心化协调器管理的共享节点集群。
IBM的R*与SDD-1类似,但主要的区别在于R*中事务的协调是完全去中心化的;它使用分布式的2PL协议,即事务直接在节点上锁定其访问的数据项。
分布式版本的INGRES也使用了去中心化2PL,并采用了中心化死锁检测。
因为处理死锁的复杂性,几乎所有基于新架构的NewSQL系统都放弃了2PL。
相反,目前的趋势是使用时间戳顺序(TO)并发控制的各种变体方案,此方案中,DBMS假定事务不会以非线性顺序的执行。
NewSQL系统中最广泛使用的协议是去中心化的多版本并发控制(MVCC),当一行数据被事务更新时,DBMS会在数据库中创建一行新版本的数据。
维护多个版本允许某个事务在另一个事务更新相同的数据时仍能完成。
它还允许长期运行的、只读的事务不对写入者进行阻塞。
几乎所有基于新架构的NewSQL系统,如MemSQL、HyPer、HANA和CockroachDB,都使用了这个协议。虽然这些系统在其MVCC实现中使用了一些工程优化和微调来提高性能,但该方案的基本概念并不新鲜。
第一个描述MVCC的已知工作是1979年的一篇MIT博士论文[49],而最早使用MVCC的商用DBMS是Digital公司的VAX Rdb和80年代初的InterBase。
我们注意到,InterBase的架构是由Jim Starkey设计的,他也是NuoDB和失败的Falcon MySQL存储引擎项目的原设计者。
其他系统则组合了2PL和MVCC。
使用这种方案,事务仍然必须在2PL方案下获得锁来修改数据库。
当一个事务修改一条记录时,DBMS会创建一个新的记录版本,就像使用MVCC一样。
这种方案允许只读查询,从而避免了获取锁,从而不阻塞写事务。这种方法最著名的实现是MySQL的InnoDB,但它也在Google的Spanner、NuoDB和Clustrix中使用。
NuoDB在原有的MVCC的基础上进行了改进,采用了gossip协议在节点之间广播版本信息。
所有的中间件和DBaaS服务都继承了其底层DBMS体系结构的并发控制方案;
由于它们大多使用MySQL,这使得它们都是带MVCC的2PL方案。
我们认为Spanner中的并发控制实现(连同它的后代F1和SpannerSQL)是NewSQL系统中最新颖的方案之一。
实际方案本身是基于前几十年开发的2PL和MVCC组合。但Spanner的不同之处在于,它使用硬件设备(如GPS、原子钟)进行高精度时钟同步。
DBMS使用这些时钟来为事务分配时间戳,以便在广域网络上实现多版本数据库的一致视图。
CockroachDB也声称要为跨数据中心的事务提供与Spanner相同的一致性,但没有使用原子钟。
相反,它们依赖于一种混合时钟协议,将松散同步的硬件时钟和逻辑计数器结合在一起。
Spanner还有一点值得注意,就是它预示着Google重新转向使用事务处理最关键的服务。
Spanner的作者甚至表示,让他们的应用程序员来处理由于过度使用事务而导致的性能问题,比起像NoSQL DBMS那样编写代码来处理缺乏事务的问题要好得多。
最后,唯一没有使用MVCC变体的商用NewSQL DBMS是VoltDB。
这个系统仍然使用TO并发控制,但它没有像MVCC那样将事务交织在一起,而是安排事务在每个分区一次执行。
它还采用了混合架构,其中单分区事务以分散的方式进行调度,但多分区事务则由集中式协调器调度。
VoltDB根据逻辑时间戳对事务进行排序,然后在轮到事务时安排它们在某个分区执行。
当一个事务在一个分区执行时,它对该分区的所有数据都有独占的访问权限,因此系统不需要在其数据结构上设置细粒度的锁和锁存。
这使得只需要访问单一分区的事务能够有效地执行,因为没有来自其他事务的争夺。
基于分区的并发控制的缺点是,如果事务跨越多个分区,它的工作效果并不好,因为网络通信延迟会导致节点在等待消息的时候闲置。
这种基于分区的并发控制并不是一个新的想法。
它的一个早期变体是由Hector Garcia-Molina[34]在1992年的一篇论文中首次提出,并在20世纪90年代末的kdb系统[62]和H-Store(也就是VoltDB的学术前身)中实现。
总的来说,我们发现NewSQL系统中的核心并发控制方案除了让这些算法在现代硬件和分布式操作环境下很好地运行外,并没有什么明显的新意。
4.4 二级索引
二级索引是一个表所有属性的子集,这些属性和主键不同。
这使得DBMS能够支持超过主键或分区键查询性能的快速查询。
在非分区DBMS中支持二级索引是不值得拿出来说的,因为整个数据库位于单一节点上。
二级索引在非分区DBMS中面临的挑战是,它们不能以与数据库其他部分相同的方式进行分区。
举个例子,假设数据库的表是根据客户表的主键来分区的。
但又有一些查询想要进行从客户的电子邮件地址到账户反向查询。
由于表是根据主键分区的,所以DBMS必须将这些查询广播到每一个节点,这显然是低效的。
在分布式DBMS中支持二级索引的两个设计问题是:
(1)系统将在哪里存储二级索引;(2)如何在事务的上下文中维护它们。
在一个具有中心化协调器的系统中,就像sharding中间件一样,二级索引可以同时驻留在协调器节点和分片节点上。
这种方法的优点是,整个系统中只有一个版本的索引,因此更容易维护。
所有基于新架构的NewSQL系统都是去中心化的,并且使用分区二级索引。
这意味着每个节点存储索引的一部分,而不是每个节点都有一个完整的副本。
分区索引和复制索引之间的权衡是,对于前者,查询可能需要跨越多个节点才能找到他们要找的东西,但如果一个事务更新一个索引,它只需要修改一个节点。
在复制索引中,角色是相反的:查找查询可以只由集群中的一个节点来满足,但任何时候一个事务修改二级索引底层表中引用的属性(即键或值)时,DBMS必须执行一个分布式事务,更新索引的所有副本。
Clustrix是一个混合了这两个概念的去中心化二级索引的例子。
DBMS首先在每个节点上存储一个冗余的,粗粒度的(即,基于范围的)索引,它将值映射到分区。
这个映射让DBMS使用一个不是表的分区属性的属性将查询路由到适当的节点。
然后,这些查询将访问该节点的第二个分区索引,该索引将精确值映射到某一行数据。
这种两层方法重新减少了在整个集群中保持复制索引同步所需的协调量,因为它只映射范围而不是单个值。
当使用不支持二级索引的NewSQL DBMS时,开发人员创建二级索引最常见的方法是使用内存中的分布式缓存部署索引,例如Memcached。
但是使用外部系统需要应用程序维护缓存,因为DBMS不会自动失效外部缓存。
4.5 副本
一个公司能够保证其OLTP应用的高可用和数据持久化的最好方法是为他们的数据库建立副本。
所有现代DBMS,包括NewSQL系统,都支持某种副本机制。
DBaaS在这方面具有明显的优势,因为它们向客户隐藏了设置副本的所有粗暴细节。
它们使得部署一个有副本的DBMS变得很容易,管理员不必担心日志传输和确保节点同步。
在数据库复制方面,有两个设计方案需要决策。
第一个是DBMS如何在节点间确保数据一致性。
在一个强一致性的DBMS中,所有的写入操作必须在所有的副本中被确认和执行,这个事务才算成功执行。
这种方法的优点是,副本在执行读查询时仍然是一致的。
也就是说,如果应用程序收到了一个事务已经提交的确认,那么该事务所做的任何修改对未来的任何后续事务都是可见的,无论他们访问的是哪个DBMS节点。
这也意味着,当一个副本失败时,不会丢失更新,因为所有其他节点都是同步的。
但是维持这种同步重新要求DBMS使用原子承诺协议(例如,两阶段提交)来确保所有的副本与事务的结果一致,这有额外的开销,并且如果一个节点失败或者有网络分区延迟,可能会导致停滞。
这就是为什么NoSQL系统选择弱一致性模型(也称为最终一致性),在这种模型中,即使有副本没有确认修改成功,DBMS也可以通知应用程序已经执行成功。
我们所知道的所有NewSQL系统都支持强一致的复制。
但是这些系统如何保证这种一致性并没有什么创新。
DBMS的状态机复制的基本原理早在20世纪70年代就被研究出来了(引用37,42)。
NonStop SQL是20世纪80年代建立的第一批使用强一致性复制以这种同样的方式提供容错的分布式DBMS之一(引用59)。
除了DBMS何时向副本传播更新的策略外,对于DBMS如何执行这种传播,还有两种不同的执行模式。
第一种,称为主动-主动复制,即每个副本节点同时处理同一个请求。
例如,当一个事务执行一个查询时,DBMS会在所有的副本节点上并行执行该查询。
这与主动-被动复制不同,主动被动复制是先在单个节点处理一个请求,然后DBMS将结果状态传输到其他副本。
大多数NewSQL DBMS实现了第二种方法,因为它们使用了一个非确定性的并发控制方案。
这意味着它们不能在查询到达leader副本时向其他副本发送查询,因为它们可能会在其他副本上以不同的顺序被执行,导致数据库的状态会在每个副本上出现分歧。
这是因为它们的执行顺序取决于几个因素,包括网络延迟、缓存停顿和时钟偏移。
而确定性的DBMS(如H-Store、VoltDB、ClearDB)则不执行这些额外的协调步骤。
这是因为DBMS保证事务的操作在每个副本上以相同的顺序执行,从而保证数据库的状态是相同的[44]。
VoltDB和ClearDB还确保应用程序不会执行利用DBMS外部信息源的查询,而这些信息源在每个副本上可能是不同的(例如,将时间戳字段设置为本地系统时钟)。
NewSQL系统与以往学术界以外的工作不同的一个方面是考虑在广域网(WAN)上进行复制。
这是现代操作环境的一个副产品,现在,将系统部署在地理差异较大的多个数据中心是轻而易举的事情。
任何NewSQL DBMS都可以被配置为通过广域网提供数据的同步更新,但这将会对正常的操作造成明显的减速。
因此,它们反而提供了异步复制方法。
据我们所知,Spanner和CockroachDB是唯一的提供了一个优化的复制方案的NewSQL系统,他们可以在广域网上进行强一致的复制。
同样的,它们通过原子钟和GPS硬件时钟(在Spanner[24]的情况下)或混合时钟(在CockroachDB[41]的情况下)的组合来实现的。
4.6 崩溃恢复
NewSQL DBMS提供容错性的另一个重要功能是其崩溃恢复机制。
但与传统的DBMS不同的是,传统DBMS容错的主要关注点是确保不丢失更新[47],新的DBMS还必须尽量减少停机时间。因为现代网络应用系统要一直在线,而网站中断的代价很高。
在没有副本的单节点系统中,传统的恢复方法是,当DBMS在崩溃后重新上线时,它从磁盘上加载最后一个检查点,然后重播它的写前日志(WAL),重新将数据库的状态转到崩溃时的状态。
这种方法的典范方法被称为ARIES[47],由IBM研究人员在20世纪90年代发明。所有主要的DBMS都实现了ARIES的某种变体。
然而,在有副本的分布式DBMS中,传统的单节点方法并不直接适用。
这是因为当主节点崩溃时,系统会将其中一个从节点作为新的主节点。当上一个主节点重新上线时,它不能只加载它的最后一个检查点并重新运行它的WAL,因为DBMS还在继续处理事务,因此数据库的状态已经向前移动。
恢复中的节点需要从新的主节点(以及可能的其他副本)获取它在宕机时错过的更新。
有两种潜在的方法可以做到这一点。
第一种是让恢复节点从本地存储中加载它的最后一个检查点和WAL,然后从其他节点提取它错过的日志条目。
只要该节点处理日志的速度能快于新更新附加到它身上的速度,该节点最终会收敛到与其他复制节点相同的状态。
如果DBMS使用物理或逻辑日志,这是有可能的,因为将日志更新直接应用于数据行的时间远远小于执行原始SQL语句的时间。
为了减少恢复所需的时间,另一种选择是让恢复中的节点丢弃它的检查点,让系统取一个新的检查点,节点将从中恢复。这种方法的另外一个好处是,在DBMS中也可以使用这种相同的机制来增加一个新的复制节点。
中间件和DBaaS系统依赖于其底层单节点DBMS的内置机制,但增加了额外的基础设施,用于领导者选举和其他管理功能。
基于新架构的NewSQL系统使用现成的组件(如ZooKeeper、Raft)和自己对现有算法的定制实现(如Paxos)相结合。
所有这些都是20世纪90年代以来商业分布式系统中的标准程序和技术。
未来趋势
我们预计,在不久的将来,数据库应用的下一个趋势是能够在新数据上执行分析查询和机器学习算法。
这种工作方式,通俗地讲就是 “实时分析 “或混合事务分析处理(HTAP),试图通过分析历史数据集与新数据的组合来推断洞察力和知识[35]。
不同于前十年的传统商业智能业务只能对历史数据进行这种分析。
在现代应用中,拥有较短的周转时间是很重要的,因为数据刚创建时具有巨大的价值,但这种价值会随着时间的推移而减少。
在数据库应用中支持HTAP管道的方法有三种:最常见的是部署单独的DBMS:一个用于事务,另一个用于分析查询。
在这种架构下,前端OLTP DBMS存储了所有事务中产生的新信息。
然后在后台,系统使用提取-转换-加载的方式将数据从这个OLTP DBMS迁移到第二个后端数据仓库DBMS。
应用程序在后端 DBMS 中执行所有复杂的 OLAP 查询,以避免减慢 OLTP 系统的速度。
从 OLAP 系统生成的任何新信息都会被推送到前端 DBMS 中。
另一种盛行的系统设计,即所谓的lambda架构[45],是使用一个独立的批处理系统(如Hadoop、Spark)来计算历史数据的综合视图,同时使用一个流处理系统(如Storm[61]、Spark Streaming[64])来提供传入数据的视图。
在这种分体式架构中,批处理系统定期重新扫描数据集,并将结果进行批量上传至流处理系统,然后流处理系统根据新的更新进行修改。
这两种方法的分叉环境本身就存在几个问题。
最重要的是,在不同的系统之间传播变化所需的时间通常是以分钟甚至以小时为单位的。
这种数据传输抑制了应用程序在数据库中输入数据时立即采取行动的能力。
其次,部署和维护两个不同的DBMS的管理开销是不小的,因为据估计,人员费用几乎占到了一个大型数据库系统总成本的50%[50]。
如果应用开发者要将不同数据库的数据结合起来,还需要为多个系统编写查询。
一些系统,试图通过隐藏这种拆分系统架构来实现单一平台;一个例子是Splice Machine[16],但这种方法还有其他技术问题,因为要把数据从OLTP系统(Hbase)复制到OLAP系统(Spark)中去。
第三种(我们认为更好的)方法是使用单一的HTAP DBMS,它支持OLTP工作负载的高吞吐量和低延迟需求,同时还允许复杂的、运行时间较长的OLAP查询对热数据(事务性)和冷数据(历史)进行操作。
这些较新的HTAP系统与传统的通用DBMS的不同之处在于,它们结合了过去十年中专门的OLTP(如内存存储、无锁执行)和OLAP(如列式存储、矢量执行)系统的进步,但却在一个DBMS中。
SAP HANA和MemSQL是第一个以HTAP系统自居的NewSQL DBMS。
HANA通过在内部使用多个执行引擎来实现:一个引擎用于面向行的数据,更适合交易;另一个不同的引擎用于面向列的数据,更适合分析查询。
MemSQL使用两个不同的存储管理器(一个用于行,一个用于列),但将它们混合在一个执行引擎中。
HyPer从专注于OLTP的H-Store式并发控制的面向行的系统,转而使用带有MVCC的HTAP列存储架构,使其支持更复杂的OLAP查询[48]。
甚至VoltDB也将其市场策略从单纯的OLTP性能转向提供流式语义。
同样,S-Store项目也试图在H-Store架构之上增加对流处理操作的支持[46]。
从2000年中期开始,专门的OLAP系统(如Greenplum)将开始增加对更好的OLTP的支持。
然而,我们注意到,HTAP DBMS的兴起确实意味着巨大的单体OLAP仓库的结束。
这种系统在短期内仍然是必要的,因为它们是一个组织所有前端OLTP孤岛的通用后端数据库。
但最终,数据库联合的复兴将使公司能够执行跨越多个OLTP数据库(甚至包括多个供应商)的分析查询,而无需移动数据。
6. 总结
从我们的分析中得到的主要启示是,NewSQL数据基础系统并不是对现有系统架构的彻底背离,而是代表了数据库技术持续发展的下一个篇章。
这些系统所采用的大部分技术都存在于学术界和工业界以往的DBMS中。
但其中许多技术只是在单个系统中逐一实现,从未全部实现。
因此,这些NewSQL DBMS的创新之处在于,它们将这些思想融入到单一的平台中。
实现这一点绝不是一个微不足道的工程努力。
它们是一个新时代的副产品,在这个时代,分布式计算资源丰富且价格低廉,但同时对应用的要求也更高。
此外,考虑NewSQL DBMS在市场上的潜在影响和未来发展方向也很有意思。
鉴于传统的DBMS厂商已经根深蒂固,而且资金充裕,NewSQL系统要想获得市场份额,将面临一场艰苦的战斗。
自我们首次提出NewSQL这个术语[18]以来,在过去的五年里,有几家NewSQL公司已经倒闭(如GenieDB、Xeround、Translattice),或者转而专注于其他领域(如ScaleBase、ParElastic)。
根据我们的分析和对几家公司的访谈,我们发现NewSQL系统的被接受的速度相对较慢,特别是与开发者驱动的NoSQL吸收相比。
这是因为NewSQL DBMS的设计是为了支持事务性工作场景,而这些工作场景大多出现在企业应用中。
与新的Web应用工作场景相比,这些企业应用的数据库选择决策可能更加保守。
这一点从以下事实也可以看出,我们发现NewSQL DBMS被用来补充或替换现有的RDBMS部署,而NoSQL则被部署在新的应用工作场景中[19]。
与2000年代的OLAP DBMS初创公司不同,当时几乎所有的厂商都被大型技术公司收购,到目前为止,只有一家收购NewSQL公司。
2016年3月,Tableau宣布收购了为HyPer项目组建的初创公司。
另外两个可能的例外是:(1)Ap-ple在2015年3月收购了FoundationDB,但我们把它们排除在外,因为这个系统的核心是一个NoSQL键值存储,上面嫁接了一个低效的SQL层;(2)ScaleArc收购了ScaleBase,但这是一个竞争对手收购了另一个竞争对手。
这些例子都不是那种传统厂商收购后起之秀系统的收购(比如2011年Teradata收购Aster Data Systems)。
我们反而看到,大型厂商选择创新和改进自己的系统,而不是收购NewSQL新秀。
微软在2014年在SQL Server中加入了内存Hekaton引擎,以改善OLTP工作负载。
甲骨文和IBM的创新速度稍慢;他们最近在其系统中增加了面向列的存储扩展,以与惠普Vertica和亚马逊Redshift等日益流行的OLAP DBMS竞争。它们有可能在未来为OLTP工作负载增加内存选项。
从更长远的角度来看,我们认为,在我们这里讨论的四类系统中,将出现功能的融合。
(1)1980-1990年代的老式DBMS,(2)2000年代的OLAP数据仓库,(3)2000年代的NoSQL DBMS,(4)2010年代的NewSQL DBMS。
我们预计,这些分类中的所有关键系统都将支持某种形式的关系模型和SQL(如果它们还没有的话),以及像HTAP DBMS那样同时支持OLTP操作和OLAP查询。当这种情况发生时,这种分类将毫无意义。
鸣谢
The authors would like to thank the following people for their feedback: Andy Grove (AgilData), Prakhar Verma (Amazon), Cashton Coleman (ClearDB), Dave Anselmi (Clustrix), Spencer Kimball (CockroachDB), Peter Mattis (CockroachDB), Ankur Goyal (MemSQL), Seth Proctor (NuoDB), Anil Goel (SAP HANA), Ryan Betts (VoltDB). This work was supported (in part) by the National Science Foundation (Award CCF-1438955).
For questions or comments about this paper, please call the CMU Database Hotline at +1-844-88-CMUDB.
7. 引用
略了
