前面讲了CPU的演进,提出了StoreBuffer和InvalidateQueue的设计,并且讲解了这两个设计会带来的问题。
解决这两个问题就是引入内存屏障:强制刷新StoreBuffer和InvalidateQueue。
这里详细讲讲x86机器上的内存屏障指令与其他隐式的含有内存屏障的指令。
然后再聊一聊JMM与内存屏障的对应关系。
x86与内存屏障
前面提到的StoreBuffer和InvalidateQueue并不是所有的CPU都会去实现。
其中x86的机器上,遵循的内存一致性协议叫TSO协议。
在这个协议中,有个叫WriteBuffer的东西,就是对应StoreBuffer。
但是并没有InvalidateQueue的存在。
内存屏障指令集
上文中,提到了三个内存屏障的指令:
- lfence():读屏障
- sfence():写屏障
- mfence():读写屏障
那么在代码中是怎么定义的呢:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
首先来看barrirer()的定义,这个是禁止编译器进行重排序的。
具体的解释可以参考笔者的另外一个文章:volatile和内存屏障
然后我们看CONFIG_SMP,如果定义了这个,说明该机器上不止一个Core,否则就是单核心的机器。
在单核心的机器上,所有的CPU的内存屏障指令都是空指令,只有禁止编译器重排序的作用。
这个也好理解,就不多做解释了。
而在多核心的机器上,分别定义了:
- smp_mb():读写屏障
- smp_rmb():读屏障
- smp_wmb():写屏障
同时我们看具体的实现,也就是用到了我们上面提到了lfence,sfence,mfence。
但是我们再仔细看看这句话:#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
如果CPU没有lfence指令,那么就用lock; addl $0,0(%%esp)代替。
为什么?难道lock; addl $0,0(%%esp)也能有内存屏障的语义吗?
是的!
除了fence指令,还有很多的其他的指令也隐藏了内存屏障的语义。
下面笔者来总结一下:
常见的三种
x86/64系统架构提供了三种多核的内存屏障指令:(1) sfence; (2) lfence; (3) mfence
- sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
- lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
- mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
其实总结起来就是读屏障,写屏障,读写屏障。
上述的是显式的会起到内存屏障作用的指令,但是还有许多指令带有异常的内存屏障的作用。
MMIO写屏障
Linux 内核有一个专门用于 MMIO 写的屏障:mmiowb()
笔者也不熟悉这个的作用,后续再补上
隐藏的内存屏障
Linux 内核中一些锁或者调度函数暗含了内存屏障。
锁函数:
- spin locks
- R/W spin locks
- mutexes
- semaphores
- R/W semaphores
中断禁止函数:
启动或禁止终端的函数的作用仅仅是作为编译器屏障,所以要使用内存或者 I/O 屏障 的场合,必须用别的函数。
SLEEP和WAKE-UP以及其它调度函数:
使用 SLEEP 和 WAKE-UP 函数时要改变 task 的状态标志,这需要使用合适的内存屏 障保证修改的顺序。
JMM
在JMM中,定义了4中内存可见性语义:
- LoadLoad
- LoadStore
- StoreStore
- StoreLoad
但是这些指令对应到x86的机器上,并不是都需要实现的。
因为x86的核心问题是有StoreBuffer,一个值被Core0写入了StoreBuffer,另外一个Core可能读不到最新的值,除非Flush StoreBuffer。所以StoreLoad语义需要内存屏障来维持。
例如以下的例子:1
2
3
4
5
6
7
8void foo(void) {
x=1; //S1
r1=y; //S2
}
void bar(void) {
y=1; //L1
r2=x;//L2
}
在这个例子中,如果没有内存屏障,Core0执行foo,Core1执行bar,则r1和r2可能出现同时为0的情况。
再具体的这个文章讲的很好:为什么在 x86 架构下只有 StoreLoad 屏障是有效指令?
更具体的例子
下面我们看看代码,经过JIT编译后的指令1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static int a = 0;
static int b = 0;
public static void main(String[] args) {
for (int i = 0; i < 10000; i++) {
add();
}
}
public static void add() {
for (int i = 0; i < 100; i++) {
a++;
b += 2;
}
}
如果a没有被volatile修饰:
可以看到a和b的操作分别对应:inc %r9dadd $0x2, %r9d
中间没有任何内存屏障的指令
如果我们加上volatile修饰呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static volatile int a = 0;
static volatile int b = 0;
public static void main(String[] args) {
for (int i = 0; i < 10000; i++) {
add();
}
}
public static void add() {
for (int i = 0; i < 100; i++) {
a++;
b += 2;
}
}
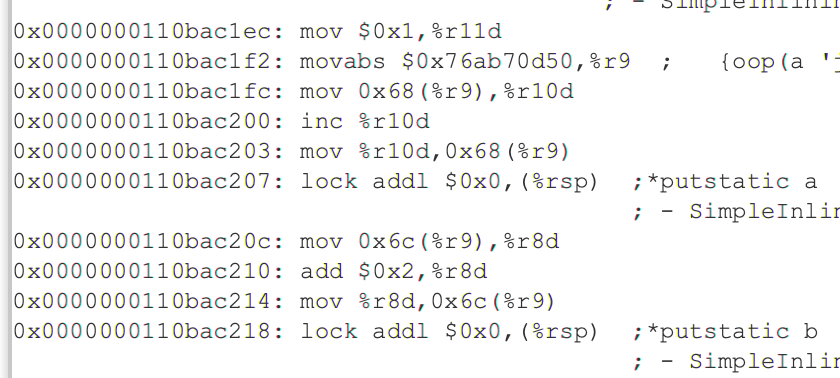
可以很明显的看到两个lock指令。
