前言
MVStore是h2数据库的底层的存储文件格式
在1.4版本之前底层的文件存储都是org.h2.store.*包中的
然后1.4之后默认改为了org.h2.mvstore.*包中的
官方的介绍说是根据Log Structed FS设计的,顺序写提高性能
MV的意思是multi-version
同类型的项目有个叫mapDB的项目
https://github.com/jankotek/mapdb
还有一个Apache的项目mavibot
http://directory.apache.org/mavibot/downloads.html
简单使用
1 | import org.h2.mvstore.*; |
来自官网的例子
就当做一个普通的Map使用就行,不过这里支持持久化到磁盘上
文件格式
在参考文档中有详细的讲述,不过和最新的代码版本有一些出入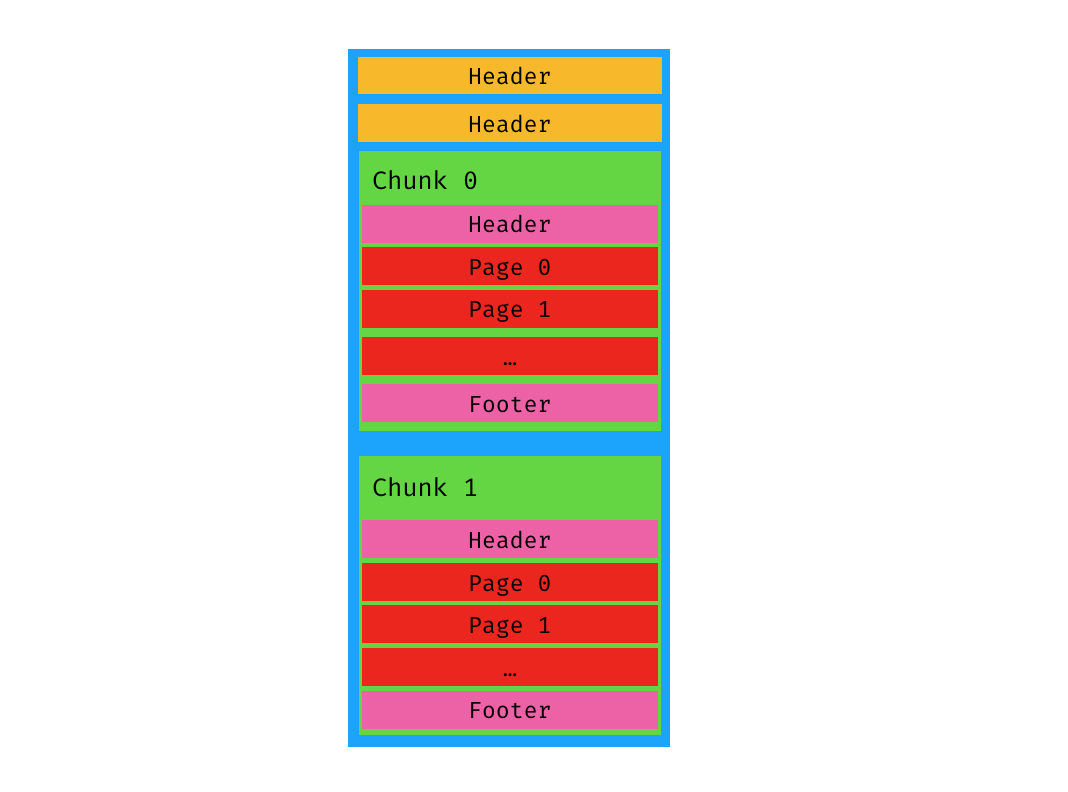
先谈谈block的概念block是一个扇区的大小,也就是磁盘一次读取的大小。
所以H2里定为4k,然后无论是file header还是chunk,都是对齐到block的整数倍
总体
[ file header 1 ] [ file header 2 ] [ chunk ] [ chunk ] ... [ chunk ]
整个文件的格式是这样
其中file header是个KV的格式,大小是一个block
形如H:2,blockSize:1000,created:167a11ebf8d,format:1,fletcher:9f80997e
H:2:固定的,表示这个是h2数据库文件blockSize:1000:block的大小,size是16进制的,换成存储的就是4Kcreated:167a11ebf8d:创建时间,v也是16进制的format:1:文件格式版本,为了防止后续如果新版本文件格式更改,现在都是1fletcher:9f80997e:checkSum
file header写了两份,header1和header2内容是一样的,官网的描述是防止文件损坏破坏了一份,也是有道理的。
Chunk
由于是Version的概念,所以每一次Commit,都会把这个阶段进行了修改的Page都放在新的Chunk中,Version++ (当然如果这段时间内没有修改,就不会commit)
每次Commit结束,只保留RootPage,把Children的Page缓存全部清空
下面的chunk是真正存储数据的地方,格式如下:[ header ] [ page ] [ page ] ... [ page ] [ footer ]
Chunk的大小是不固定的,但是肯定是block的整数倍大小
header也是KV的格式,长度限定了最大值Chunk.MAX_HEADER_LENGTH = 1k
header的header生成来自函数Chunk#asString
结果是header形如:chunk:5,block:5,len:1,map:c,max:980,next:6,pages:5,root:14000016194,time:102cc,version:5
chunk:5: 每个chunk都有一个id,这里的id为5,id是原子自增的block:5:chunk开始的block,用5*blockSize就可以定为到chunk在file中的offsetlen:1:chunk的长度,单位为blockmap:c:最新的map的id,这里是16进制,每新建一个Map都会分配一个id,自增的,其实我觉得是记录map的个数max:980:每个Page有个MaxLen(见下面Page的格式),这里是chunk中所有的maxLen加起来的值next:6:预测的下一个chunk的开始位置,单位为blockpages:5:此chunk中的包含的page的个数root:14000016194: MetaMap Root Page的位置,但不是指在文件中的绝对位置,参见Page中的Children编码,一般是chunkId+offset来表示time:102cc:时间戳,16进制,从文件创建后到chunk写入的时间差version:5:版本号,一般来说一个commit就会创建一个chunk,每个chunk都是一个新的版本号,这里的chunk包含的数据版本是5
除了上面这些,可能还有
liveMax: 回去看max的含义,是每个Page的MaxLen的和,就是无论这个Page是否还被使用,liveMax就是所有还在被使用的Page的MaxLen的和livePages:和上面的Pages的对应,也是还在被使用的Page的个数,而Pages统计的是所有
那么统计上面这个两个参数有啥含义呢,当我们回收一个Chunk的时候,如果其中Pages很多,但是目前还在被使用的极少,那么就会进行compact,把还在使用的移动到新的Chunk中,然后回收这个Chunk
footer的信息和header其实和一部分是一样的
写入footer我感觉是为了文件初始化的时候直接从文件末尾开始构建MetaMap准备的chunk:5,block:5,version:5,checkSum:{checkSum}
Page
page
page是进行数据读写和操作的最小单位
但是和其他的框架中的Page定义不同的是,这里的page的大小并不一定,虽然不固定,但是也有一个阈值的
当超过阈值条件后,会进行页分裂,关于页分裂的参见下文
每一个Map的底层都是一个B+树,然后每一个节点都是一个Page
但是其实不是标准的B+树,是一种变形,叫Counted B+ Tree
这个奇怪的结构,网上并没有找到介绍,但是其实就是进行了B+Tree的优化
参见我的另一个文章Counted-B+Tree原理
一个Page的结构是[length][checkSum][mapId][len][type][children][childCount][keys][values]
length:page的大小,int类型checkSum: checkSum,计算方式是chunkId ^ page在chunk中的offset ^ length,short类型mapId:page所属的map的id,variable size int类型len:key的个数,variable size int类型type:page的类型,0代表叶子节点,1代表内部节点,如果值+2了表示key和value进行了LZF压缩,如果值+6表示key和value进行了Deflate压缩,byte类型children:long[]类型,值为子节点的位置,其中- 26bit为chunkId,
- 32bit为page在chunk中的offset,
- 5bit位lengthCode,标志page的maxLen
- 0 => 32bytes
- 1 => 48bytes
- 2 => 64bytes
- 3 => 96bytes
- …
- 1bit为children的type,叶子节点还是内部节点
childCount:表示子节点中的key个数,类型是variable size long数组keys:放的是key,byte[]类型values:只有子节点有,放的是值,byte[]类型
问:为什么不用绝对位置的信息来存放Page的位置呢
答:这样灵活性更大,可以移动整个chunk而不用进行Page位置的修改
问:什么时候会移动Chunk呢
答:目前没看到
metaMap
在文件初始化的时候,会创建一个metaMap
这个Map中存放的是文件的一些元信息
每次Chunk进行写入的时候,最后写入metaMap的Page的信息
metaMap中存放着这些信息
name.{mapName}=> mapId,由map的名字对应MapId,mapId是16进制map.{id}=>name:{mapName}root.{mapId}:mapId所指的map的RootPage的位置chunk.{chunkId}=>chunk:2,block:3,len:1,liveMax:100,livePages:1,map:1,max:3c0,next:4,pages:5,root:800000be0a,time:824,version:2表示chunk为id的信息
但是整个MVStore会进行GC的,就是定期清除那些有用的Page不多的Chunk,然后把空出来的空间放新的Chunk。
这就导致了一个问题,就是最新的Chunk不一定就是就在文件的最后
所以怎么找到最新的MetaMap的地址呢
记得每个Chunk里有个next的KV吗,在MVStore进行初始化的时候,会直接读取最后一个Chunk,然后依次根据他的next值寻找下去,从而找到最后一个Chunk。
文件新建
h2抽象出了操作文件接口和上层的业务
文件的实现都是在org.h2.store.fs.*中,读写接口是FileChannel。
当我们调用
MVStore s = MVStore.open("/Users/zhuyichen/h2/data.mv");
时,MVStore会打开一个新的文件,当然是文件不存在的时候
写上file header部分,写两份1
2
3
4storeHeader.put("H", 2);
storeHeader.put("blockSize", BLOCK_SIZE); //BLOCK_SIZE = 4 * 1024
storeHeader.put("format", FORMAT_WRITE); //FORMAT_WRITE = 1
storeHeader.put("created", creationTime);
文件打开
如果是打开旧的文件,那么会分为下面几个步骤
- 读取Header信息
- 读取最后一个Chunk的Footer信息
- 读取最后一个Chunk的Header信息
- 定位MetaMap的位置
- 读取MetaMap的信息,定位所有Map的RootPage的信息
所以其实整个核心就是找到MetaMap的位置,然后读取,只要得到MetaMap的信息,就可以找到所有的Map的位置了
这里还是略复杂,为了讲清楚,我们举例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15MVStore s = MVStore.open("/Users/zhuyichen/h2/data.mv");
MVMap<Integer, String> map1 = s.openMap("data1");
MVMap<Integer, String> map2 = s.openMap("data2");
for (int i = 0; i < 100; i++) {
map1.put(i, "Hello1");
map2.put(i, "hello2");
}
s.commit();
for (int i = 0; i < 50; i++) {
map1.put(i, "hi1");
map2.put(i, "hi2");
}
s.close();
我们在运行上面的代码之后,会产生两个Chunk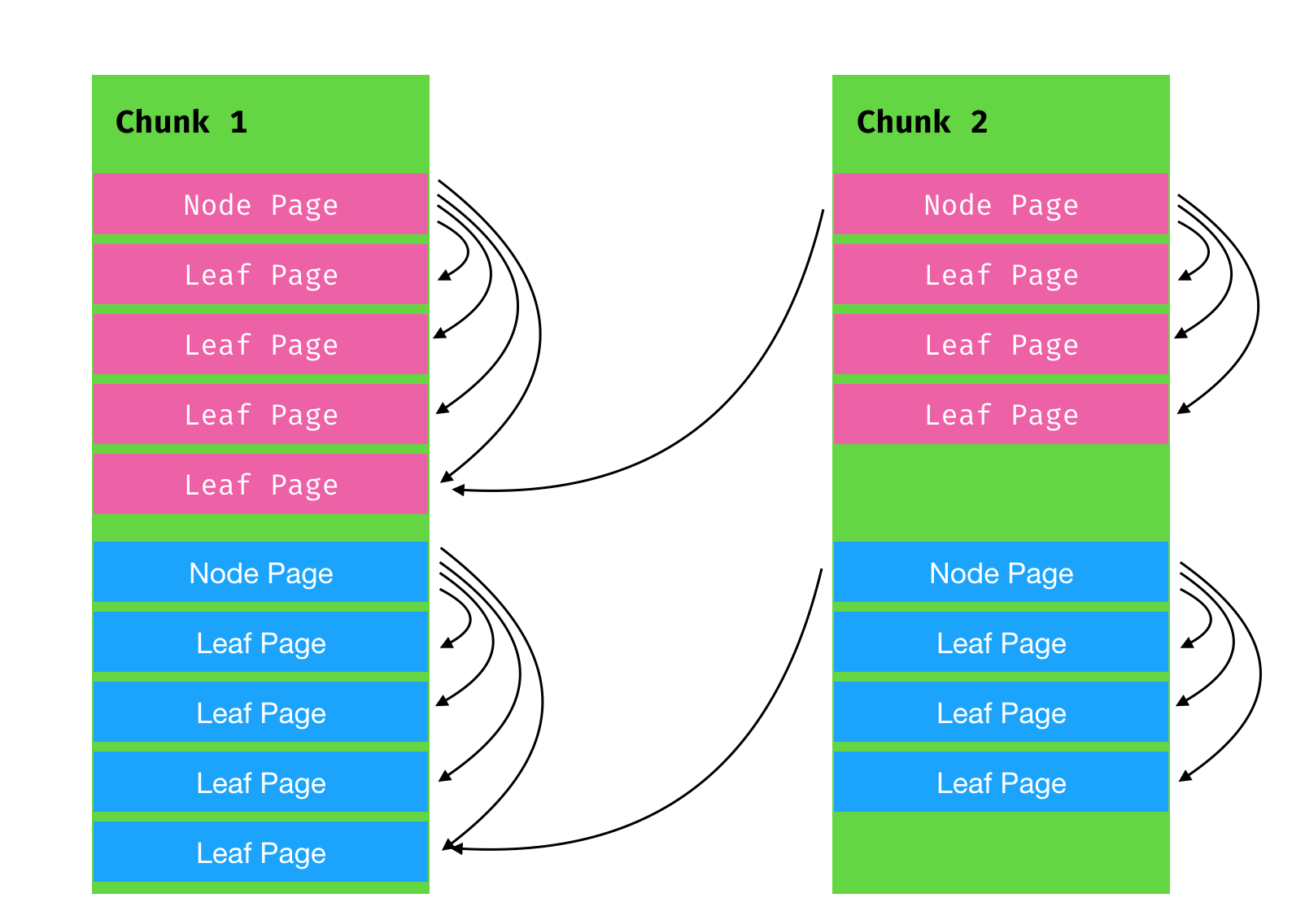
如上图
第一个Chunk中包含了两个B+树 每一个RootPage包含四个Leaf Page
在第二次修改中,我们只修改了50个元素,所以没有动到第4个Leaf Page的数据
当我们进行commit之后,只save了3个Page,第4个没有动Page,我们还是指向了Chunk1的数据 具体的基于Page的B+树,请看下面
这里我们知道了文件的布局,下面看看文件的打开流程1
MVStore s = MVStore.open("/Users/zhuyichen/h2/data.mv");
当我们调用这句话的时候
新建Map
打开文件之后,新建一个Map实例
1 | MVMap<String, String> map = mvStore.openMap("data"); |
其实还有第二个参数,是Map的一些可配置参数1
2MVMap.Builder<Integer, String> mvMapConfig = new MVMap.Builder<>();
MVMap<Integer, String> map = s.openMap("data1", mvMapConfig);
参数列表
- keyType: 默认是ObjectDataType
- valueType: 默认是ObjectDataType
- singleWriter:
我们假设文件是新建的,也就是metaMap中查询不到这个Map的信息
然后会给这个Map分配一个唯一的ID
然后向metaMap中写入自己的信息
然后新建一个空Leaf作为Map的RootPage,keys和values都是长度为0的数组
基于Page的B+树
每个Page上能放的key的个数是限制的
1 | map.put("key1", "value1"); |
假设我们这么进行写入
假设我们是新打开的Map,那么此时Map上只有一个空的Leaf数组
在进行写入之前,会对整个MVStore进行一个检查,检查文件的有效性
类似于JVM会检查Class文件的MagicWord,cafebabe一样。
下面就是查找过程,由于是Empty-Leaf,所以找到的index是-1。
继而把这个Leaf进行扩容,把key1放到Page对应的keys数组中
既然扩容values,把value1放到数组中
页分裂
页分裂的条件1
2(keyCount = p.getKeyCount()) > store.getKeysPerPage() ||
p.getMemory() > store.getMaxPageSize() && keyCount > (p.isLeaf() ? 1 : 2)
看起来还是挺简单的
store.getKeysPerPage默认是48
store.getMaxPageSize和Cache有关,不过默认是64K
如果Page是Leaf的话,还必须至少有一个Value,是Node的话,至少有两个子节点
但是我理解的话,如果是因为内存过大而分裂,那么Node节点其实是不太可能的
持久化流程
和正常的数据库一样,当我们读取和写入数据的时候,都会先从磁盘上把该数据所在的Page加载到内存中
然后持久化的最小单位也是Page
也就是说,如果Chunk 1中的Leaf Page中有48个KeyValue,但是我们只修改了一个Value,然后整个Page还是会持久化到Chunk 2中
手动持久化
1 | mvStore.commit(); |
当我们手动进行commit或者直接close的时候,其实就是告诉MVStore进行一次Version的持久化
结果就是创建一个Version = currentVersion的Chunk
写chunk的时候,首先写入header
然后开始写Page的信息
写完用户的Map的Page信息之后,最后写入MetaMap的Pages
后台定时持久化
在MVStore进行初始化之后,会启动一个后台线程1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private static class BackgroundWriterThread extends Thread {
public void run() {
while (store.backgroundWriterThread != null) {
synchronized (sync) {
try {
sync.wait(sleep);
} catch (InterruptedException ignore) {
}
}
if (store.backgroundWriterThread == null) {
break;
}
store.writeInBackground();
}
}
}
同时传递给它一个sleep的time,每隔sleepTime,就进行一次commit,默认的sleep的时间是1000ms
当他醒来之后,如果发现数据有改变,就会进行一次commit
由于时间很短,所以正常情况下,不需要手动进行commit
在我们调用MVStore#close的时候,也会调用一次进行commit
GC
随着使用时间变长,肯定不会没有限制的创建Chunk的,MVStore也有回收机制,去回收很久之前的版本的Chunk
在官方文档中写的是
Old data is kept for at least 45 seconds (configurable), so that there are no explicit sync operations required to guarantee data consistency. An application can also sync explicitly when needed. To reuse disk space, the chunks with the lowest amount of live data are compacted (the live data is stored again in the next chunk). To improve data locality and disk space usage, the plan is to automatically defragment and compact data.
我们知道MVStore不会保存所有的Version,很久之前的Version肯定会清除
那么就需要一个文件空间标记机制,标记那一块没有被使用已经被Free了,然后下面的Chunk进行写入的时候,可以复写那一块磁盘地址
这个机制在MVStore的底层文件操作类FileStore中
底层使用了BitSet来表示,单位为BLOCK_SIZE1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30#FileStore
protected final FreeSpaceBitSet freeSpace =
new FreeSpaceBitSet(2, MVStore.BLOCK_SIZE);
public void markUsed(long pos, int length) {
freeSpace.markUsed(pos, length);
}
//这个是核心方法,从FileStore中寻找length长度的位置
//注意,不是直接从文件末尾找一块地方
public long allocate(int length) {
return freeSpace.allocate(length);
}
public long predictAllocation(int length) {
return freeSpace.predictAllocation(length);
}
//free从pos开始的空间
public void free(long pos, int length) {
freeSpace.free(pos, length);
}
public int getFillRate() {
return freeSpace.getFillRate();
}
long getFirstFree() {
return freeSpace.getFirstFree();
}
long getFileLengthInUse() {
return freeSpace.getLastFree();
}
在我们进行store的时候1
2MVStore#storeNow()
long filePos = allocateFileSpace(length, !reuseSpace);
就能看到分配的逻辑在里面
同时我们还能看到Free的方法在里面,就是标记一块Chunk所在的地方已经可以进行reuse
那么怎么进行判定了,从上图我们可以知道其实即使在Chunk2中,还是有Page是引用的Chunk1
MVStore解决的方法也比较简单,就是DFS
遍历所有的Map的Node和Page,找到一个Chunk,就把ChunkId放在一个Map中,最后遍历当前文件中的所有Chunk,如果在Map中未找到,那么就是可以回收的
有点类似引用计数的方法,但是会不会出现循环引用呢
由于所有的Map的RootMap都是存在最新的Chunk中,所有不会出现循环引用的情况
方法在MVStore#collectReferencedChunks
这里为了加速DFS的速度,还启动了一个线程池
带来的问题:
GC的机制也带来了问题,就是最新的Chunk在哪儿的问题
我们知道如果真的是Log Structed FS的格式的话,那么最新写入的肯定是在最后,而MetaMap的Root Page是在最新的Chunk中的
所以我们需要一个机制在打开文件的时候,找到最新的Chunk的位置
这个查找的过程,前面已经描述了一遍了
Compact
当一个Chunk中LivePages比较少的时候,H2会进行Compact1
MVStore#compact
Compact的方式
我只能表示非常的tricky
把LivePages中比较少的Page上的数据,全部replace了一遍,这样Chunk1指向chunk0的数据相当于全部update了一遍,但是数据没有变化
等Compact完之后,再进行上面一步
Page Cache
Page的Cache机制不是LRU,而是LIRS
说实话这种Cache机制我是第一次见
Debug技巧
源码环境导入Idea
会出现提示configure OSGI,别点
dump file
如果想要观察Commit发生了什么
可以把BackgroundWriterThread给关闭了,防止在背后每隔1s自己commit
h2的作者提供了一个dump方法MVStoreTool.dump()
可以把文件的内容打印出来
PR
在阅读MVStore源码的过程中,还发现了一个comment的错误
已经提了PR进行了修复
