第一次写如此泛泛而谈的文章。
最近磁盘,IO中断的概念不断的在我脑子中,就随便写写。
Speed
其实自己之前对内存访问,Cpu Cache和磁盘访问,网络访问的时间并没有多大的概念。
只知道个大概的比较
下面是各个操作的正常时间延迟
--《Redis开发与运维》
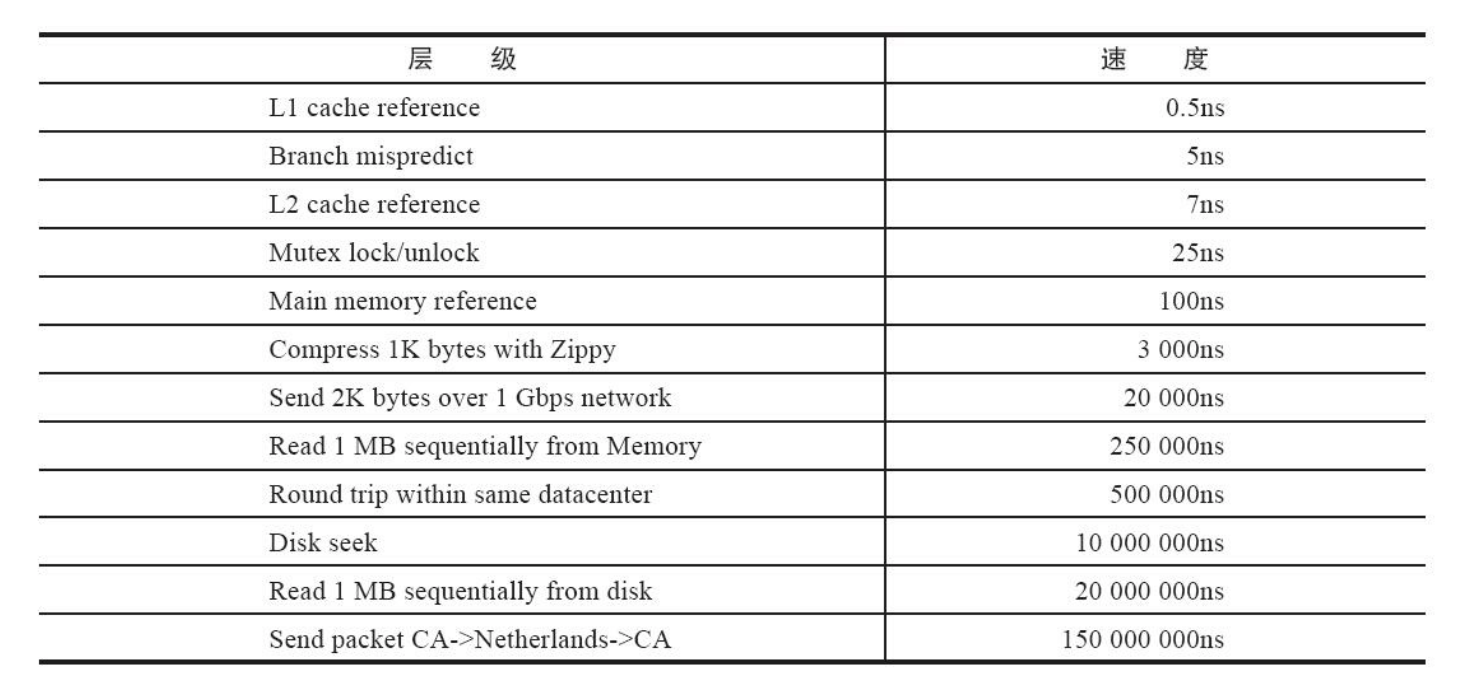
同时,目前很多的产品都用上了SSD。
而SSD相对于磁盘而言,访问速度和性能又上升了一个层次。
传统磁盘的I/O寻道延迟很高,这导致它的访问延迟(~10ms)远高于内存(~100ns),并且它的随机访问性能远低于顺序访问性能,这对上层软件系统的设计产生了极大的影响。为了解决这一问题,存储器件的演进方向主要包含两类:(1) 闪存(Solid State Disk,SSD)将I/O访问延迟降低了三个数量级(~10us),并且它的随机读取性能与顺序读取性能相似
– http://mysql.taobao.org/monthly/2018/11/01/
= = 我没测过,所以不对以上数据负责。。。
- Cpu Cache << Main Memory
这个很典型的例子,就是ArrayList的迭代和LinkedList的迭代,哪个快问题,因为一个CacheLine是64,所以读取不足64k的话,会把目标地址的周围数据也读进去填充为一个CacheLine,这个就导致了ArrayList的迭代速度大于LinkedList - Main Memory Reference + Read 1MB sequenially from memory <<< Disk Seek + Read 1MB sequenially from Disk
这个速度差距简直不忍直视,现在的很多内存数据库,比如Redis,虽然是双读双写,如果Miss了,还要读一次数据库,性能损耗很大,但是如果访问量巨大,全部命中Cache的话,那收益是巨大的。
System Call
还有一个性能所在的地方就是系统调用
普通函数和系统调用的性能对比我也不是很清楚,只是知道系统调用性能消耗比较大
从上面看,一个轻量级的系统调用还行,但是涉及到IO的,就很慢了,比正常函数慢100 - 1000倍不等。
而如果考虑Epoll那种事件驱动的话,如果你的业务代码非阻塞,执行的非常的快的话,其实和IO事件比起来不算什么,参见Netty,可能你调用了几百个简单的函数,都不如一次Read函数花的时间多。
从数据上看Write比Read更是慢了一倍,所以NIO而言,异步的写,我感觉还是比较重要的,特别是遇到Would Block的错误,如果还是拼命写,那其实还不如先存起来,等待一个写事件。
缓冲
如果你再去看看主存的定义,会发现它其实是类似于缓存的东西,为磁盘服务的。
缓存的概念其实到处都有,主要用来处理上层和下层的速度不匹配的问题。
而磁盘的缓存单位一般是页,在H2Database中,一个页通常是4k,和内核的内存管理有关。
而数据的写入,一般是先写入主存,再写入磁盘。
而大多数人不知道的是,我们代码的数据到磁盘之间,调用write之后,并不会直接到磁盘,而是先写入内核的缓存。
所以数据的流向是这样的
用户态数据 -> 内核态数据 -> 磁盘。
相应的,从磁盘读取数据到用户态也是
磁盘 -> 内核态数据 -> 用户态数据
内核是以页为单位把数据从磁盘读到内核缓冲区的。
内核为啥要把数据先放到自己的缓冲区呢,个人理解答案当然还是为了缓冲。
就跟Cpu的CacheLine一样,你只从文件里读取一个Bit?那不行,直接拉满填充一个Page
当我们自己向文件中写入了值的时候,其实还没有写进去磁盘,具体什么时候写,由内核来定。
所以提供了两个函数
- sync
- fsync
sync只是把脏页数据,强制放到写磁盘的队列中
fsync一直到成功写入磁盘才返回
而write函数仅仅是写回脏页而已
而这里其实还有个问题,就是内核是不相信用户的,所以如果你要从内核的缓冲区进行Read,内核会把那一份数据拷贝一份到用户态
这其中的消耗其实不是那么必要的。
为此,内核还提供了一个函数mmap,就是给予用户程序能直接读取和写入数据到内核的缓冲区
在此,如果有这样一个需求,在一个静态的httpServer,需要把index.html传送到socket,我先read出来,然后write出去,这不傻逼了吗,白白复制这么多次。
然后有个系统调用叫sendfile,内核帮你直接复制到socket的缓冲区。
中断
如果你注意思考上面的问题,你就会发现问题本质是
- CPU的快和其他东西慢的矛盾
在思考Epoll的就绪链表的时候,如果该Socket Fd上出现事件,就调用回调把自己插入到就绪链表。
那么再深层次一点,谁调用这个回调呢,是内核
再深层次一点,内核怎么知道你这个Fd上有数据
那就是网卡发送中断给CPU了设备事件 - 中断 - CPU响应中断
这个简直是个完美的模型
但是上面的模型,如果基于Netty的Flux一样,并不能提高事件处理的速度,而是提高了吞吐量,提高吞吐量的关键就是不要Block住CPU,再实际一点就是不要Block住线程,让一个线程多处理事件。
而提高应用的速度和吞吐量并不是两个毫不相干的东西,在一些情况下,甚至会是互相矛盾的。
比如就写事件而言,如果出现了would block
- 我还是疯狂写
- 注册写事件,当出现写事件再去写
如果你是疯狂写,那么你就是让其他的事件去等待,恰好网络状况较好的话,这种的速度是很快的,但是吞吐量不高。
如果你是注册写事件,那么就是暂时放弃了这个fd,当Fd可写的时候,相对于第一种情况,已经经过了相对较长的时间了,相应的响应时间就变长了。
我曾经设想过一个,就是用Netty的时候,把EventLoop线程设置为茫茫多,像Tomcat那么多,但是其实是有问题的,因为他的模型和Tomcat不一样,Tomcat的200个线程是不处理IO事件的,但是EventLoop中每一个线程还注册了Epoll来处理IO事件。
虚拟内存
主存的定位是什么,Cache吗,作为CPU和磁盘的缓冲,有道理。
作为CPU计算的中间结果的暂存地?也有道理。
其实现在这种Cache大行其道的时代,你会发现主存却越来越非主流
从Cache的角度讲,主存的意义就是作为磁盘的高速Cache
但是现在你和其他人讲这个观点反而会觉得奇怪,内存怎么会和缓存是一回事呢?
因为现在很多东西都只在内存中,应用或者系统也没有打算写到磁盘中
Cache失效了?那就崩溃了,那就重启吧,不叫事。
但是如果你在公司不考虑缓存失效的情况,那你怕是要被开除了。
但是其实我们没有考虑过,主存到底会不会失效呢
我们写Java程序,往一个List里面写一个对象,运行着发现这个对象没了
不会考虑到操作系统的问题,而是我们代码的问题
所以Cache失效的问题,是操作系统来保证不会失效的的。
当然DRAM也算,硬件一般也不会出问题
如果你再深挖一下
什么?内存竟然不是我们自己来管理的?那我们平时写内存写内存是写到哪儿去了。
不要误以为写内存就是直接写物理内存(内存条),其实只是提申请给操作系统,然后由操作系统写到了物理内存
那平时我们print出来的那些内存地址呢,是真的物理地址吗?
不是
那些地址是假的吗?
是也不是。
那么操作系统怎么管理内存的呢?
其实操作系统管理内存的方式更像是Cache管理的方式
CPU
如果你参考现在的系统优化方向,大部分分两个方向
- 架构
- 硬件
之前我在的数据库事业部,架构上的优化,和高性能几乎没什么关系,基本都是为了CAP而来
但是加速执行,硬件是个大方向,而且越来越火
比如Java的Panama项目中增强的SIMD支持
SIMD是什么呢?这个是CPU中很早就支持的东西,但是JDK中是我们无法控制的,有HotSpot自己控制。
从数据库的查询来看,SIMD在对数组进行Project和Filter等特定算子的运行时,加速是很大的。
