B树的一种变形,和B+树有点相近但是实现不一样
B-Tree
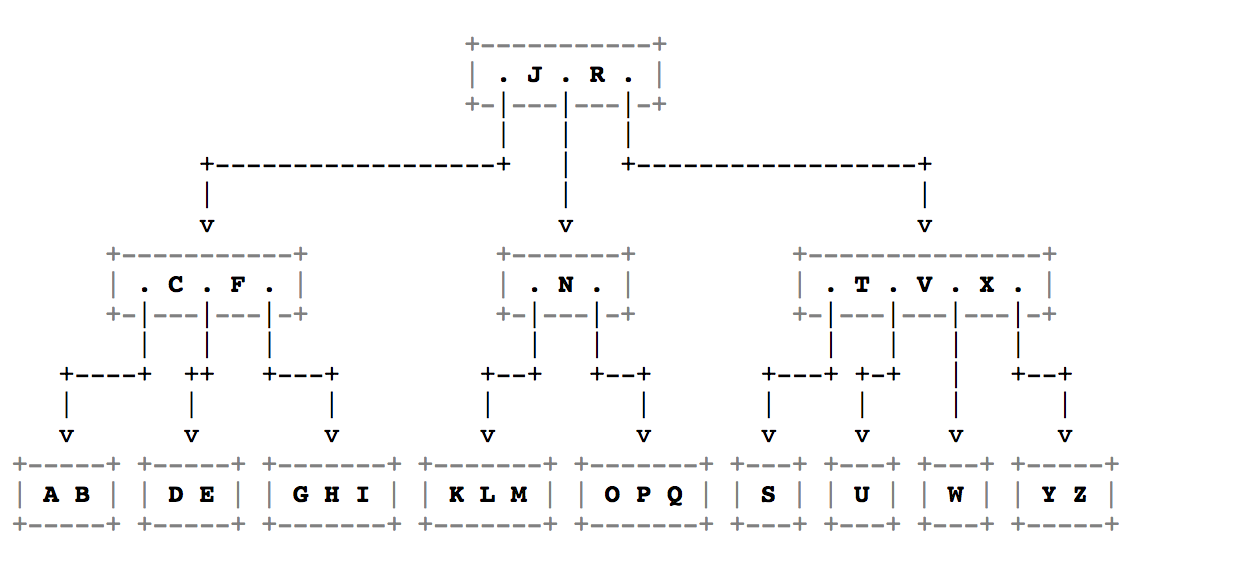
上面是典型的一个B-Tree的结构
如果我们知道B-Tree的改进版B+Tree的话,就知道纯粹的B-Tree其实是有缺点的
如果我们要取排名第X的元素,那么其实需要进行中序遍历
如果我们需要一段范围内的元素,那么还是需要进行中序遍历
B+Tree
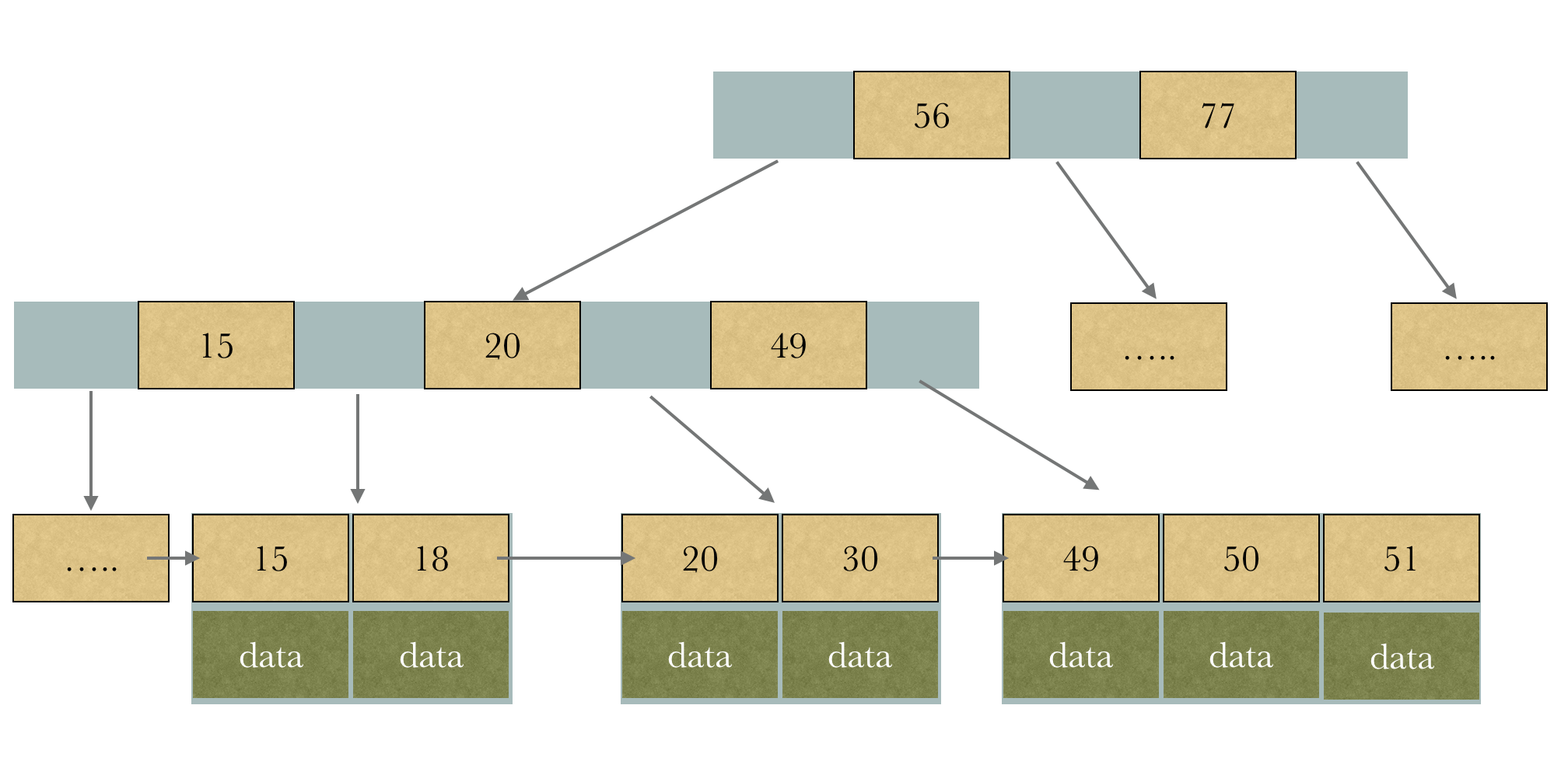
但是B+Tree提出了一种解决方案(当然还有其他的原因,磁盘的出入度之类)
它把所有的元素放在叶子节点,然后全部用指针串起来。
但是这样还是有一个问题,我们寻找第X个,其实最差的情况下是O(n)的,因为必须从头开始寻找,而且必须把Page的数据全部读取出来,很有可能我们要的数据并不在这个Page上
还有一个问题,就是如果我们要倒数后10个元素,因为底层的指针是单方向的,所以无法从后往前。
Counted-B-Tree
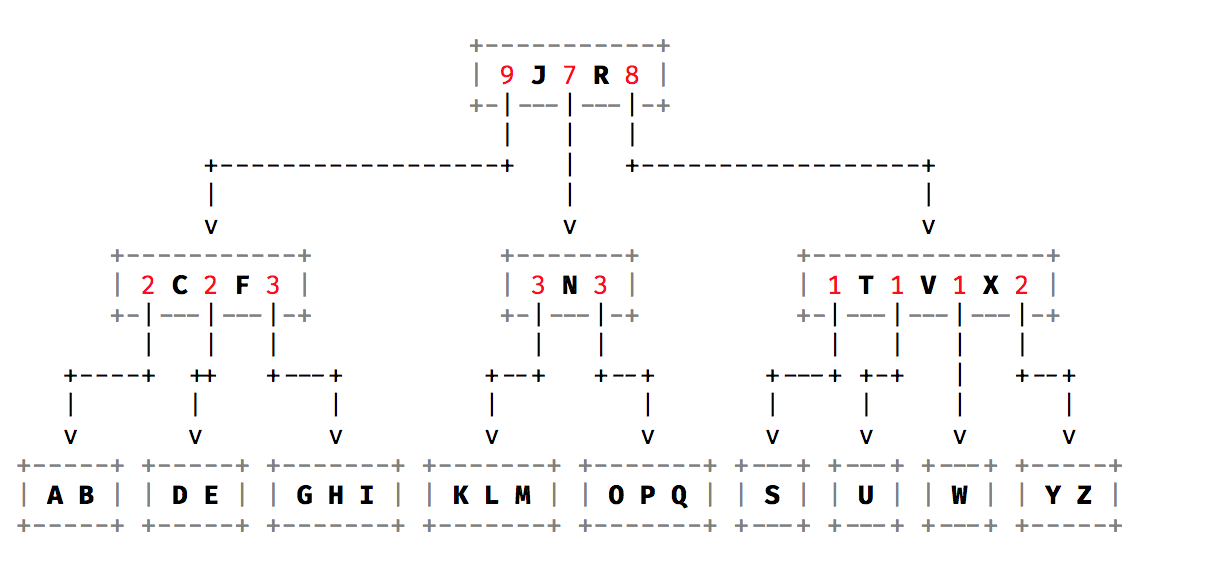
上面就是本文要讲的Counted-B-Tree了
每个父节点记录了子节点的元素个数
这样我们在寻找第X个元素的时候,不需要进行遍历
在寻找一段范围的元素的时候,也可以进行
同时如果是逆序的查找,其实也可以很快的进行,只要考虑每个节点是从左往右还是从右往左就行
但是如果你说从B+Tree的磁盘存储角度讲的话,由于数据还是放在元素节点中,所以进行Page读取的话,还是会把很多不需要的值读取出来
Counted-B+Tree
在H2Database中
他的Page结构就结合了B+Tree和Counted-B-Tree
他的结构类似于这种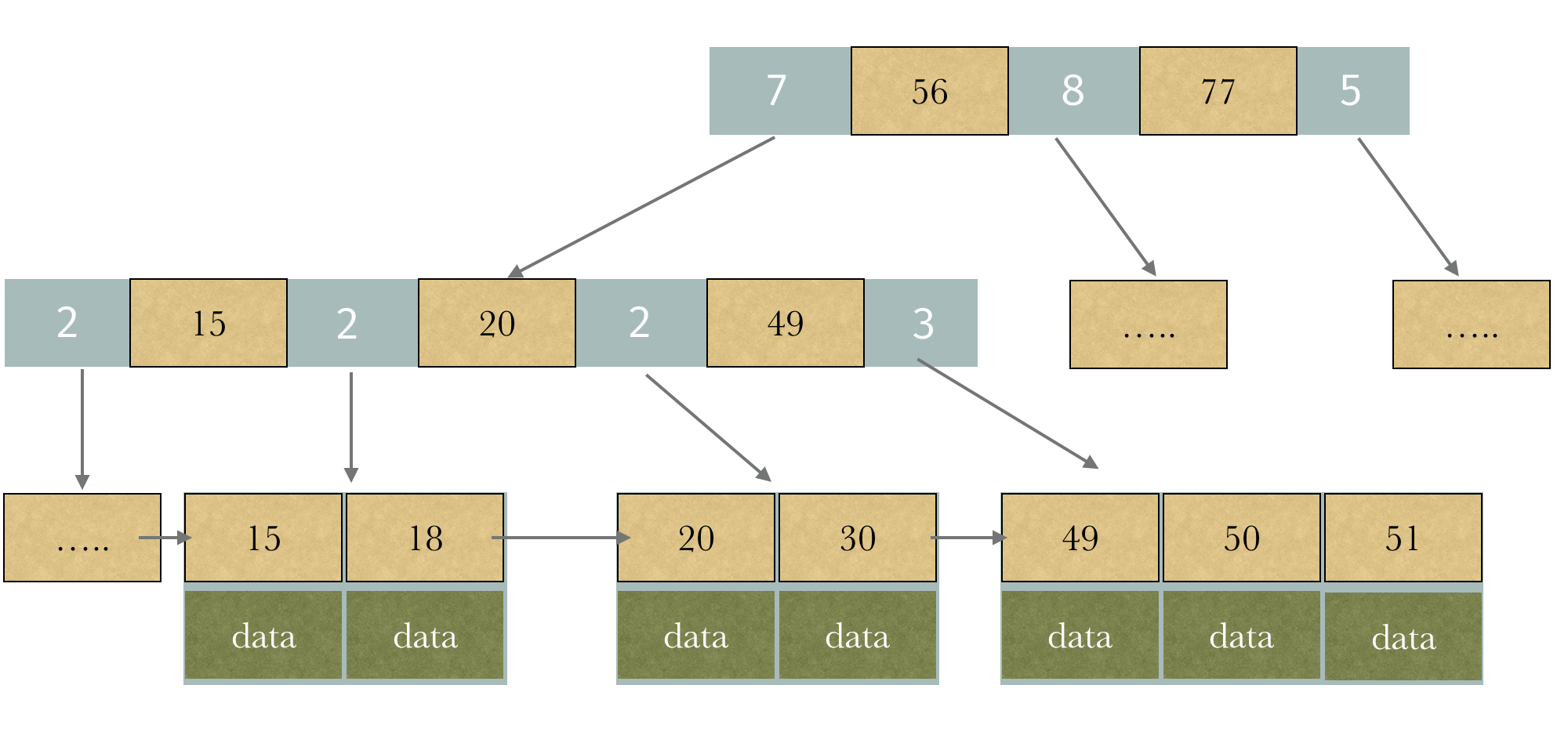
对于磁盘存储而言,维护了很好的出入度,同时对于第X个查找和范围查找又维持了很好的效率
参考文档
https://www.chiark.greenend.org.uk/~sgtatham/algorithms/cbtree.html
http://directory.apache.org/mavibot/user-guide/2-btree-types.html
https://www.kancloud.cn/kancloud/theory-of-mysql-index/41846
