大学里也没教跳表,主要是树结构的实现
因为Redis源码里使用到了跳表
所以顺便学习一番
参考资料
我把参考资料写在开头,因为我保证我不是跳表将的最好的
https://www.cs.cmu.edu/~ckingsf/bioinfo-lectures/skiplists.pdf
数据结构
Redis的跳表的定义代码在server.h中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
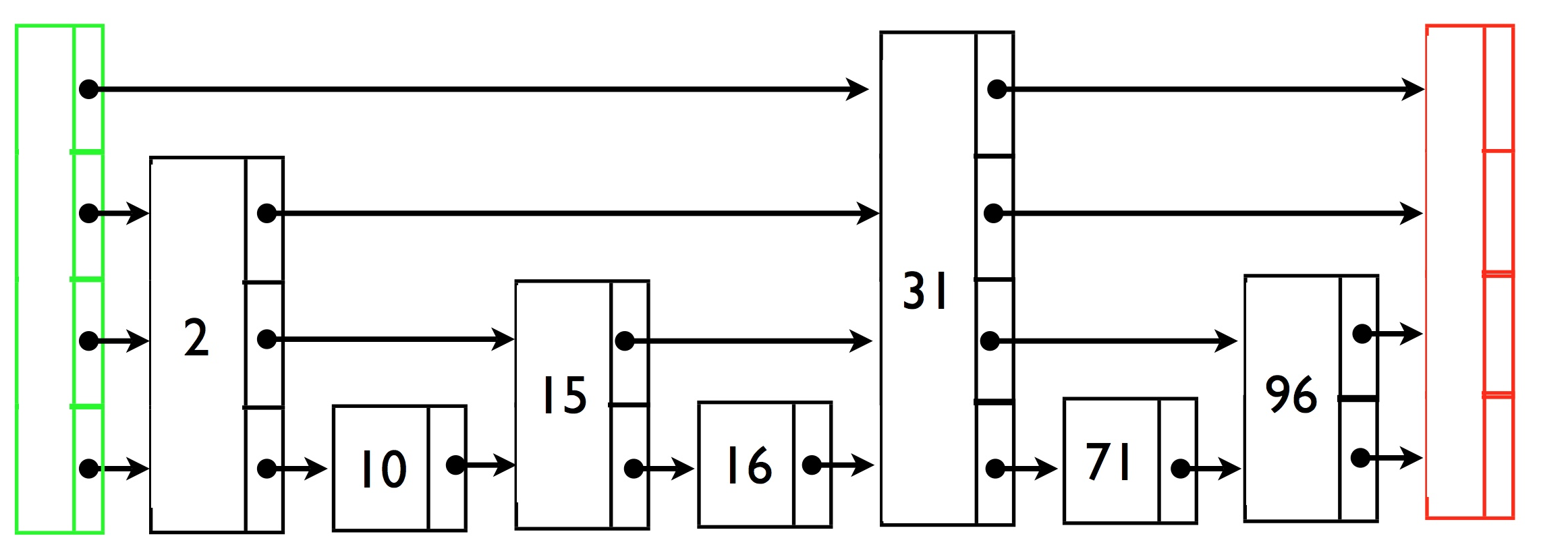
和红黑树的功能相比,Redis的跳表的定义还有点不太常见的地方
- backward节点,这个节点的指向和level数组向前不一样,指向的是后一个节点,相当于红黑树的父节点的指针
- span,这个是计算当前节点和forward指向的节点中间的间隔,这个有什么用呢,主要是计算当前节点的排名的
我们在查找一个节点的时候,把查找过程中的所有的span加起来就是它在整个跳表中的排名
如果说上一个红黑树可能还算常见的话,这个就更不常见了,而且这个的计算还是有点复杂
创建
对一个跳表而言,我们初始化的时候,要设定它的最大高度,Redis中设置的是32
在初始化跳表的时候,要先创建header节点,高度位32
每个Node的创建的时候,level数组会随机一个大小,不超过32
代码如下:(没啥好看的)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
//创建header
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
zskiplistNode *zslCreateNode(int level, double score, robj *obj) {
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->obj = obj;
return zn;
}
查找
查找比较简单
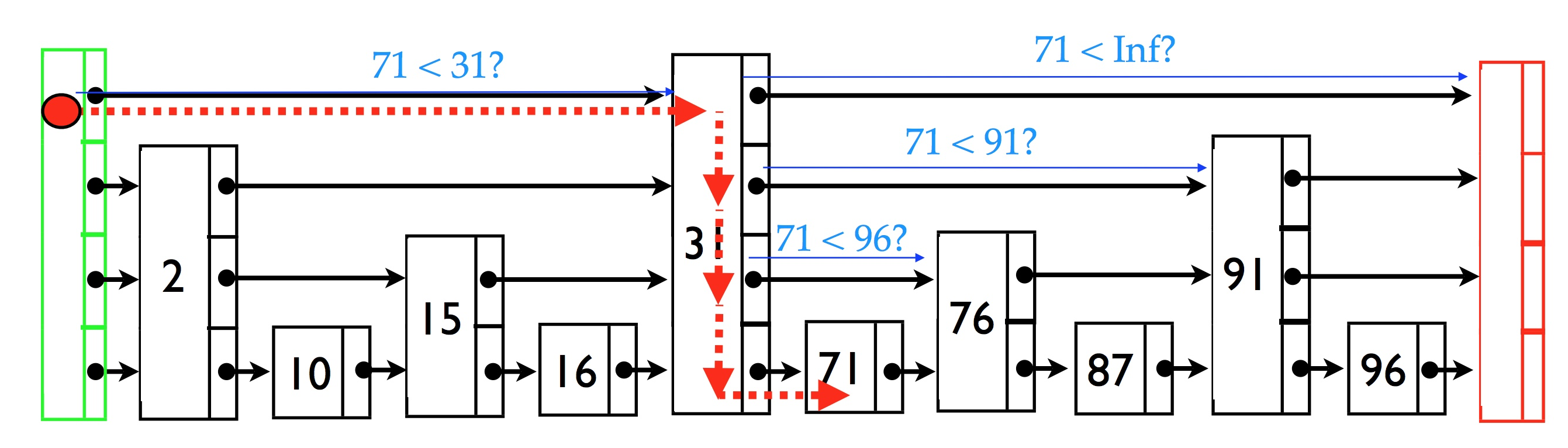
比如上图中,我们要查找71这个元素,这个图假设的最大高度是4
先从header的最高level开始
如果forward节点的值小于var,则前跳
如果大于或者指向了tail,则下降一个level
再补充一个查找96的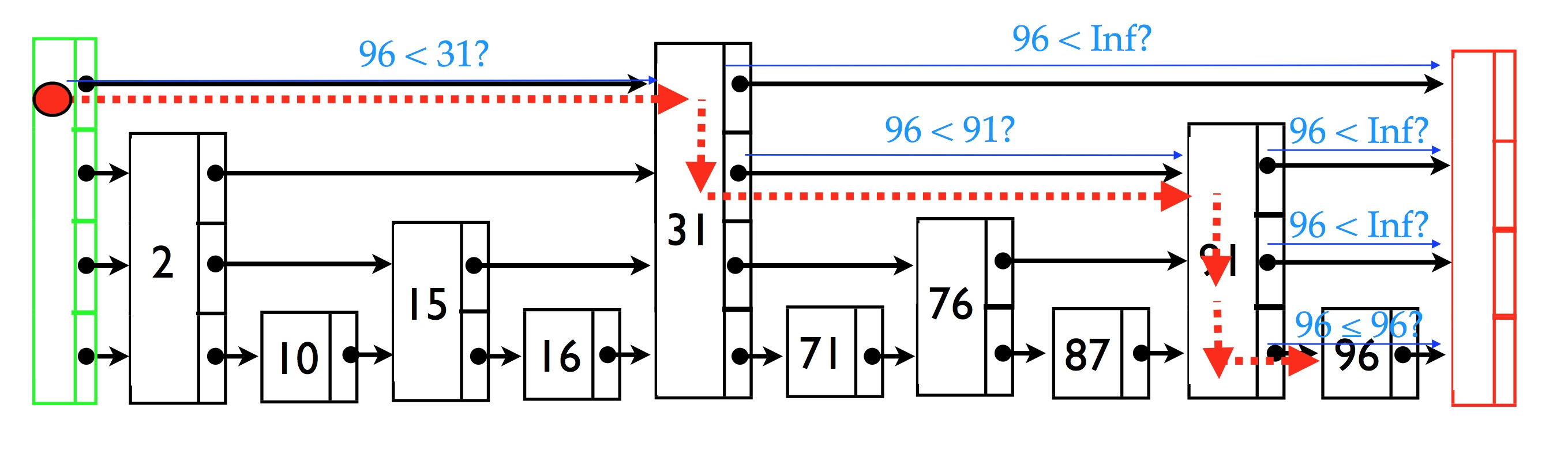
插入
理解了查找的逻辑,才能方便理解怎么插入
因为插入一个节点,除了要知道它因为在的位置,还需要修改它前面节点的level数组中forward指针的指向
同时,对于Redis的拥有span的信息而言,还需要更改前面节点的span的值
这个Redis使用了一个Update数组和Rank数组辅助完成
Update数组主要用来构建将插入节点的每个Level成员的前继节点
Rank数组则是Update数组中每个成员在整个跳表中的排名
看图
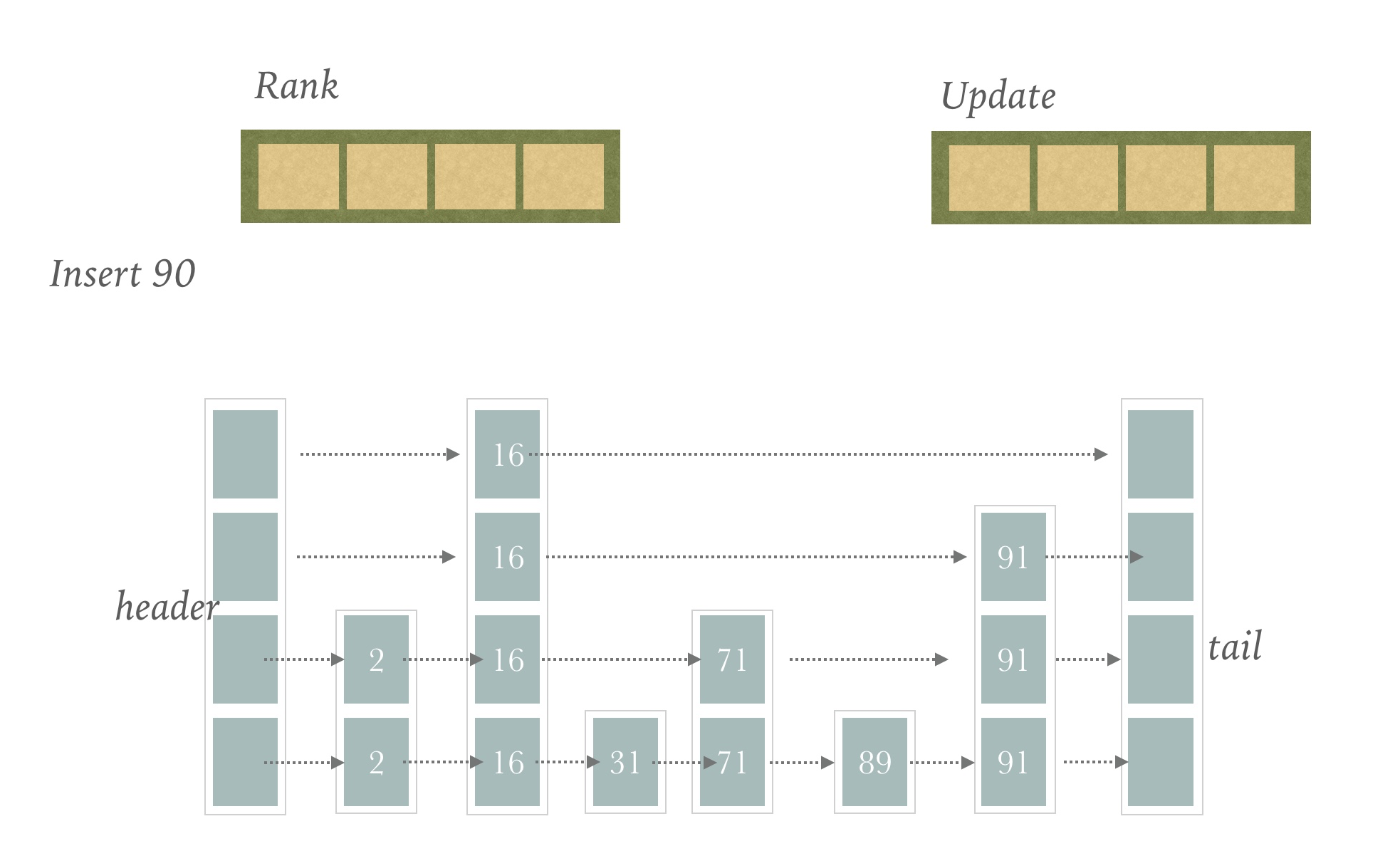
假设当前的跳表是这样,我们要插入元素90
首先初始化Update和Rank数组,大小是maxLevel的大小,这里就是4
首先对第一层分析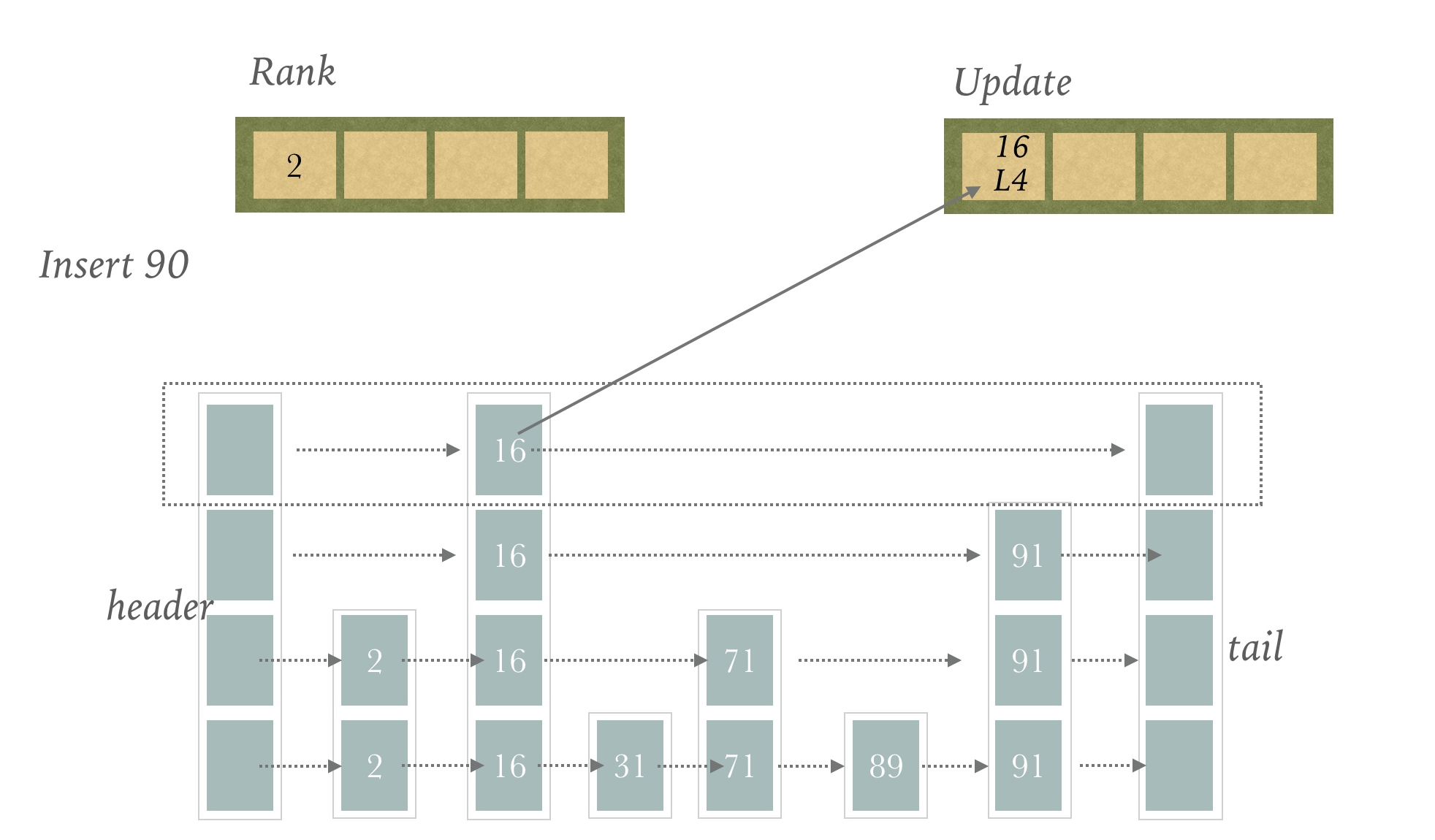
从header节点出发,找到最后一个比90小的Level中的节点,就是16的level[3]
然后放入Update数组,同时把它的Rank放入Rank数组
然后对第二层进行分析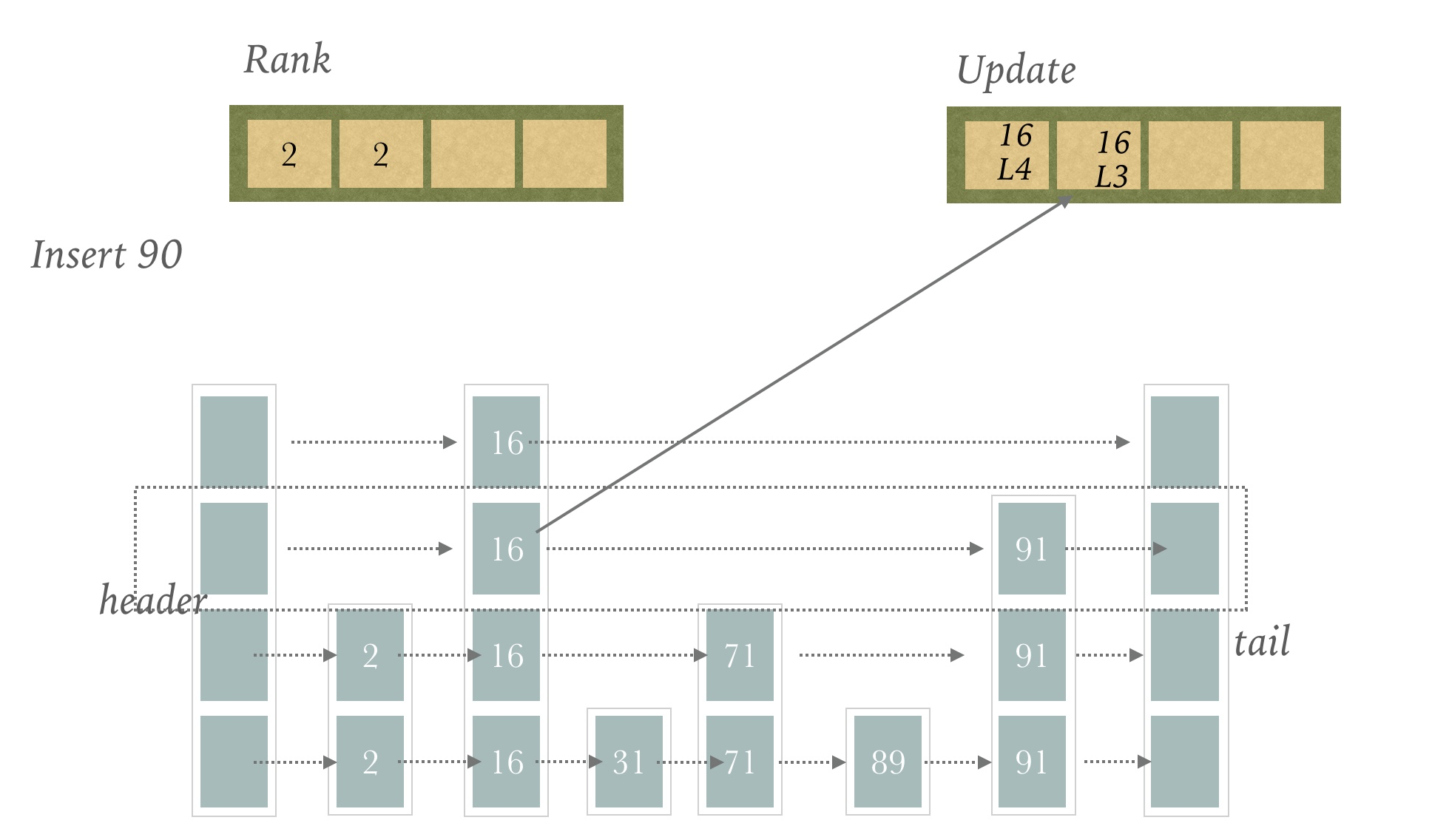
还是16这个节点,放入Update和Rank数组中
第三层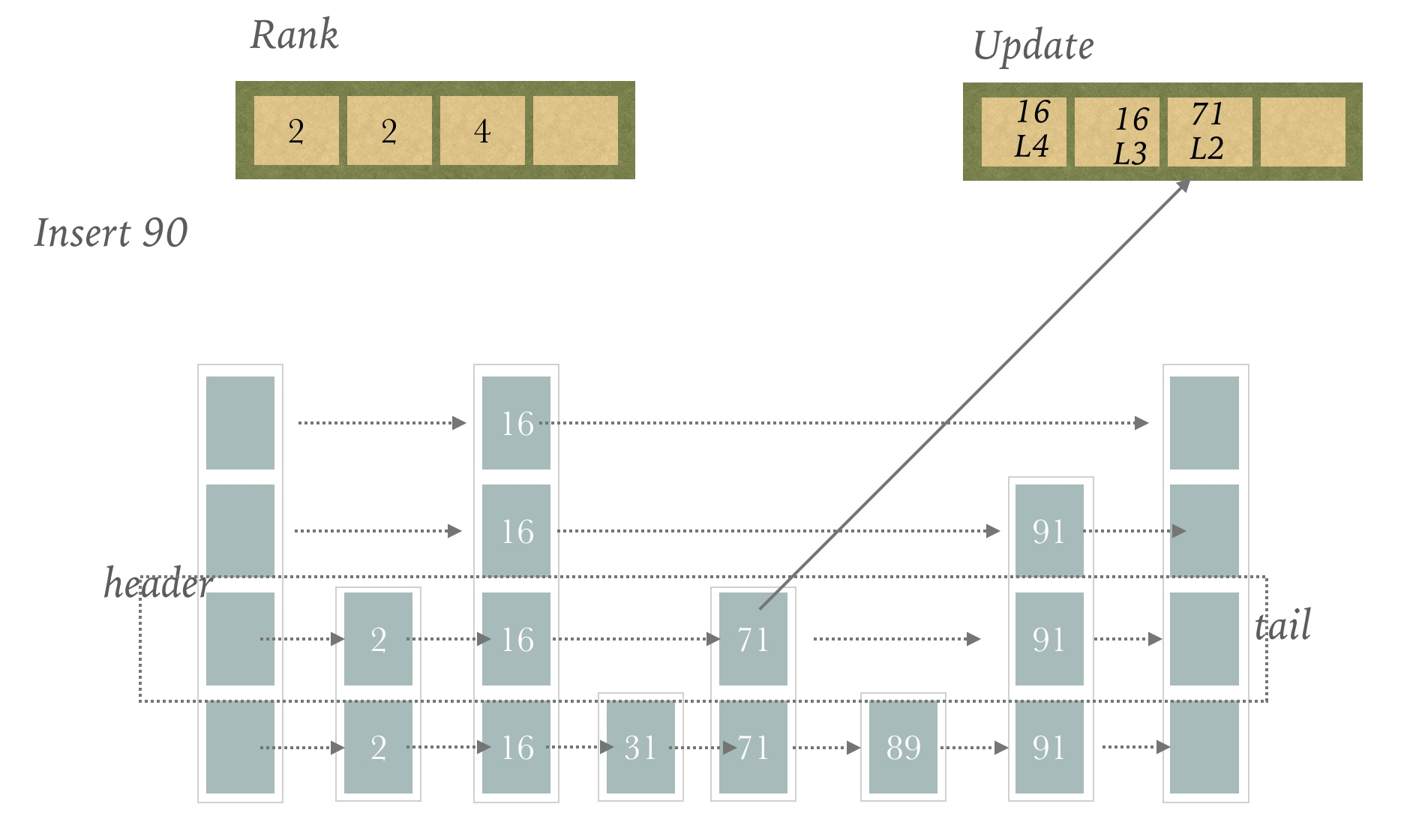
我们找到71这个节点,放入Update和Rank数组中
第四层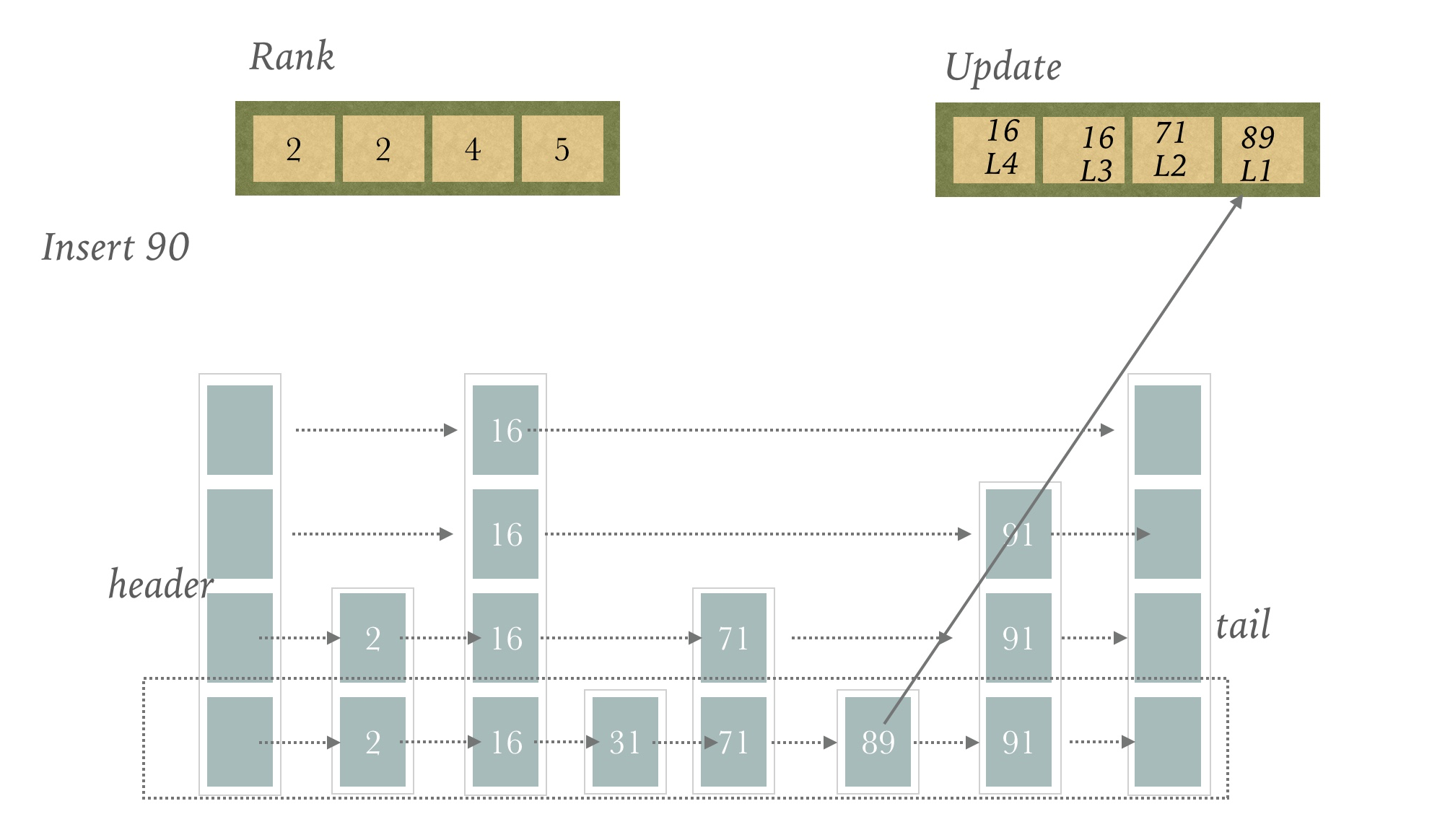
我们找到89这个节点
到现在为止,Update数组和Rank数组都已经构建完毕
90插入的位置也已经找到,就是89节点的下一个位置
我们随机一个高度,假设是3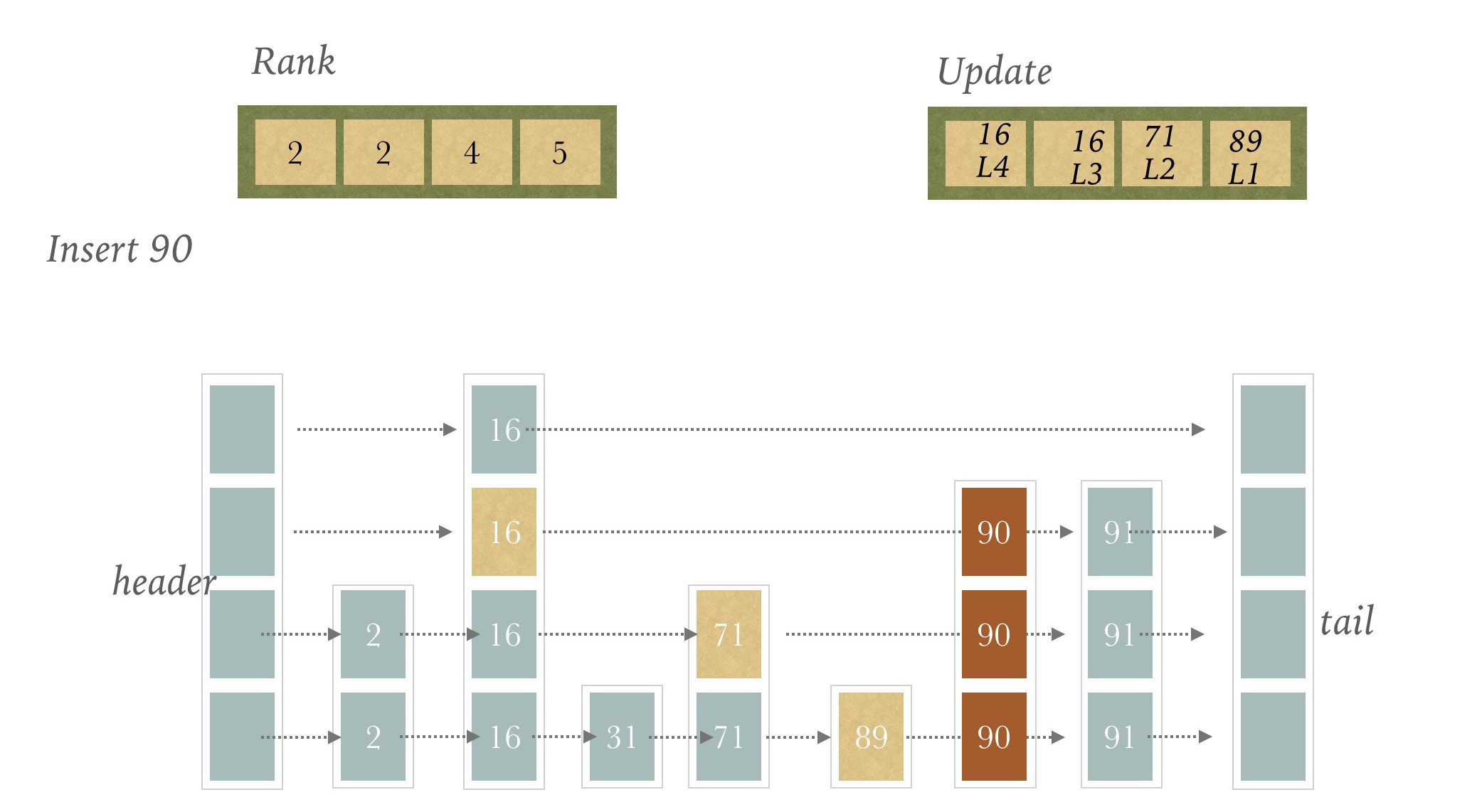
那么我们更新90的前继节点的forward指针和span值呢
有了Update和Rank数组,公式可以很轻松的拿到1
2
3
4
5x.level[i].forward = update[i]->level[i].forward
update[i]->level[i].forward = x
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i])
update[i]->level[i].span = (rank[0] - rank[i]) + 1
这就是核心的插入逻辑,代码中其实不是每一层都是从Header开始查找的
我这么画是为了好理解一点
下面是Redis中的源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL]; //建立一个长度为32的rank,用于后续更新span
int i, level;
serverAssert(!isnan(score));
//update数组,存的是即将指向新插入节点的level数组的forward节点
x = zsl->header;
//for循环,寻找每一层的前继节点,方法Update数组中
//当然这里并不是每次都从头开始找的,整个构建逻辑和查找很像
for (i = zsl->level-1; i >= 0; i--) {
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
compareStringObjects(x->level[i].forward->obj,obj) < 0))) {
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
//给新节点初始化一个高度
level = zslRandomLevel();
//创建一个跳表节点
x = zslCreateNode(level,score,obj);
//更新前继节点的forward和span
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
//有删减
}
删除节点
删除节点其实比较简单了
只需要构建Update数组就行了
span就直接加上被删除节点的span就行了
