重点
- 按申请内存大小分类,使用不同的分配策略
- 完美二叉树表示内存池占用
- ThreadLocalCache
- Recycler对象池
简单使用
Netty的内存分为池化和非池化
同时又分直接内存和堆内存
1 | //direct pooled |
基本概念
对于一些重要抽象的概念
- PoolArean: 内存分配的上层接口
- PoolChunk: 直接管理内存,一大块byte[]就是在这其中申请的
- Page: Chunk中的内存被逻辑上分为很多个Page,逻辑上按照Page进行分配管理
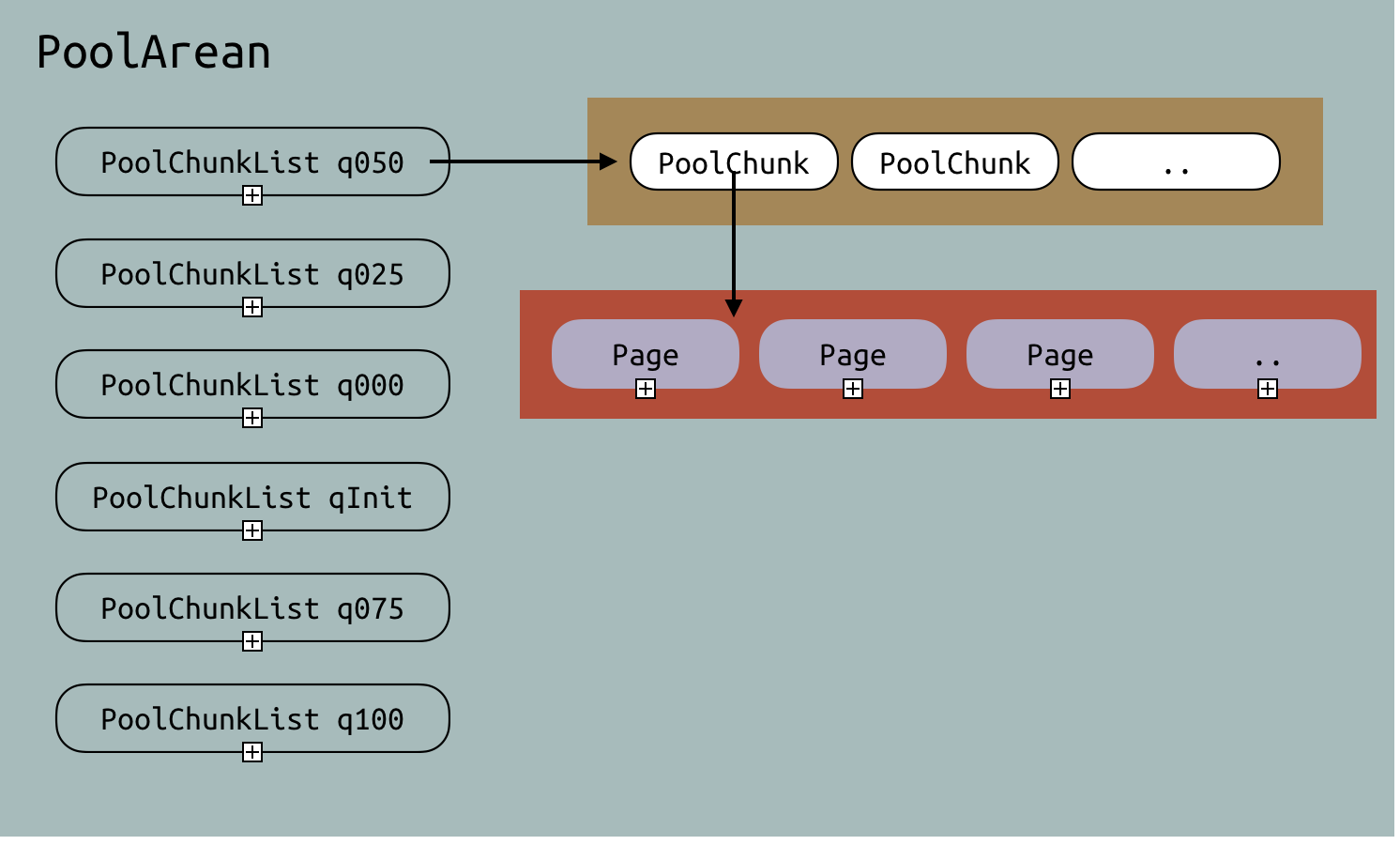
上面这个图很好的阐述了三者的关系
一个PoolArean中包含很多的PoolChunk
同时为了管理这些PoolChunk,Arean根据目前内存占用率建立了对应的几种PoolChunkList并进行双向链表的串联

某一个PoolChunk并不是一直在一个List中,会根据使用率进行动态调整
new一个PoolChunk的时候,也会申请一大块内存
对这大块内存进行逻辑上的分配,固定一个大小,每一个大小称为一个Page
参数设置
大体的概念是这样,下面有一些重要的系统参数规定:
DEFAULT_PAGE_SIZE: 是默认一个Page的大小,默认是8kPageShifts:这个参数很迷,由Integer.SIZE - 1 - Integer.numberOfLeadingZeros(pageSize)这样计算出来,默认是13DEFAULT_MAX_ORDER决定设置一个PoolChunk的申请内存的大小,下面可以看到,就是完美二叉树的树高 默认是11defaultChunkSizePoolChunk的申请的内存大小 => DEFAULT_PAGE_SIZE << DEFAULT_MAX_ORDER 默认是16MBdefaultMinNumArena: 默认的Arean个数: 等于NettyRuntime.availableProcessors() * 2DEFAULT_NUM_HEAP_ARENA和DEFAULT_NUM_DIRECT_ARENA:
当我们初始化PooledByteBufAllocator的时候,会初始化PoolArean,但是为了减少竞争,会建立不只一个PoolArean
这两个参数是表示建立几个Heap_Arean和Direct_Arean 我的机器上默认是161
2
3
4
5
6DEFAULT_NUM_HEAP_ARENA = Math.max(0,
SystemPropertyUtil.getInt(
"io.netty.allocator.numHeapArenas",
(int) Math.min(
defaultMinNumArena,
runtime.maxMemory() / defaultChunkSize / 2 / 3)));
对于申请的内存块大小 ,分为三类1
2
3
4
5enum SizeClass {
Tiny,
Small,
Normal
}
Tiny是 小于 512的
Small是大于512小于PageSize的
Normal是大于等于一个PageSize的
Netty之所以分为三类,是因为这三类的分配方式不是很一样
Alloc初始化
PooledByteBufAllocator进行初始化的时候,会先初始化两个PoolArenaPoolArena<T>[]
分别是堆和直接内存的 就是不管你想用哪个,都会初始化两个
同时对数组的成员的每一个成员增加PoolArena
如果是堆就是1
HeapArena extends PoolArena<byte[]>
如果是直接内存就是
1 | DirectArena extends PoolArena<ByteBuffer> |
注意两个之中的泛型是不一样的
分配
虽然我们申请内存使用的是PoolArean的方法,但是真正负责分配的还是在PoolChunk中
上文中我们提到PoolChunk一下子会直接申请16MB的内存
PoolChunk利用两个byte数组来进行内存的管理
byte[] memoryMap = new byte[1 << maxOrder << 1] == new byte[4096]byte[] depthMap = new byte[memoryMap.length]
这两个参数构造了一个完美的二叉树
在进行初始化的时候按照memoryMap[id] = depth_of_id进行分配1
2
3
4
5
6
7
8
9
10int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
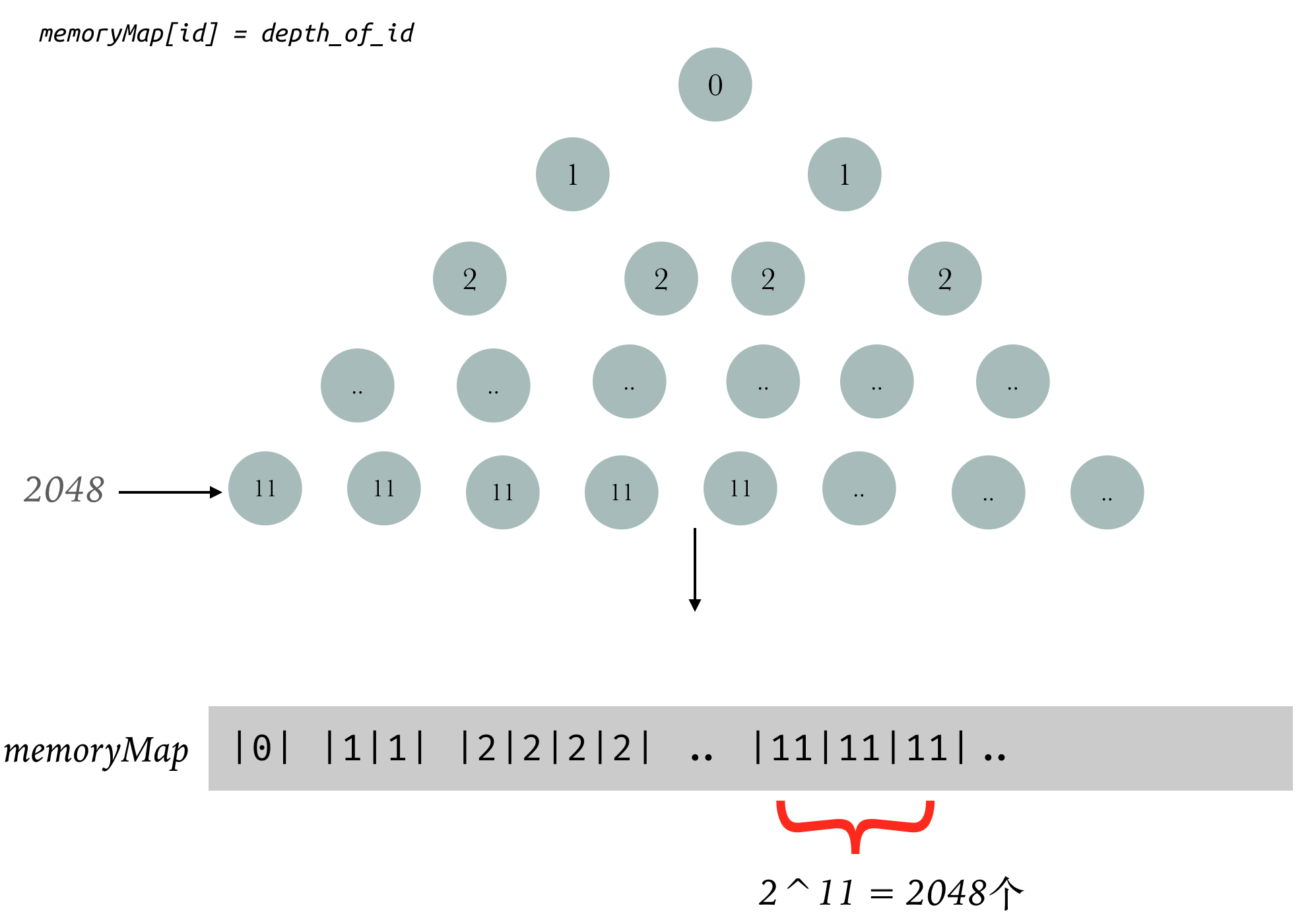
上面我画的图很好的解释了二叉树图到数组的转变
有个注意的点就是数组的使用域从Index = 1开始的
叶子节点有2048个,每一个叶子节点表示一个逻辑的Page,也就是8k的内存
那么叶子节点的父节点就代表16k内存,依次向上,第一个节点表示16MB内存
一个PoolChunk有2048个Page
那么怎么标记那一块内存被使用,那一块没有没使用呢
首先既然逻辑单位是Page,那么进行分配的时候都是按照Page来,标记的粒度最小的也是Page
不会标记这个Page用了一半的情况
这里,类的注释中讲的很清楚
To allocate a memory segment of size chunkSize/2^k we search for the first node (from left) at height k which is unused
对于MemoryMap而言
- 1) memoryMap[id] = depth_of_id => it is free / unallocated
- 2) memoryMap[id] > depth_of_id => at least one of its child nodes is allocated, so we cannot allocate it, but some of its children can still be allocated based on their availability
- 3) memoryMap[id] = maxOrder + 1 => the node is fully allocated & thus none of its children can be allocated, it is thus marked as unusable
- 1) 如果 memoryMap[id] = depth_of_id 表示这一块还未分配,我们初始化的值就是这样
- 2) 如果 memoryMap[id] > depth_of_id 表示下属的内存已经被分配了,但是还未分配完全
- 3) 如果 memoryMap[id] = maxOrder + 1 表示下属的内存已经被分配完了
对于depthMap而言,它的作用是
depthMap[id]= x indicates that the first node which is free to be allocated is at depth x (from root)
下面我们仔细走一下流程
size > PageSize
如果我们申请的内存大于一个PageSize的内存,假设就是(8192 + 1)b的大小
首先我们需要对内存进行规整化
申请大小规整化
我们知道Netty把申请的内存分为三类
如果小于512,则找到下一个16的倍数最小的
2 => 16
3 => 16
15 => 16
17 => 32
其中如果大于512,那么就是找到下一个2的次方最小的
比如
513 => 1024
1050 => 2048
那么8093b被规整化为16k,也就是2个page
我们知道二叉树depth=11时的节点,分配的是一个Page的
depth = 10时的节点,分配的是2个Page的
然后我们从第一个节点开始迭代
判断memoryMap[1]和10的大小
要判断这个节点下时候还有分配8k的空间,只需要比较memoryMap[id] 和 depth_of_memory的大小,这个和下面的分配成功的标记有关
如果memoryMap[0] > 10,则已经分配完了,分配失败
否则就肯定还有空间分配16k的内存
我们只需要迭代的找子节点,memoryMap[id] == 10,
这里不是广度优先搜索,是深度优先,所以只管查找,只要有一个进行
那么找到第10层第一个节点 memoryMap[1024]
那么这个节点代表的内存将被分配出去
好,节点找到了,那么下面需要迭代更新父节点的信息
因为现在父节点memoryMap[id] = depth_of_id
要更新成已经被分配,但是还未分配完全
比较子节点的值,选择一个最小的赋给它
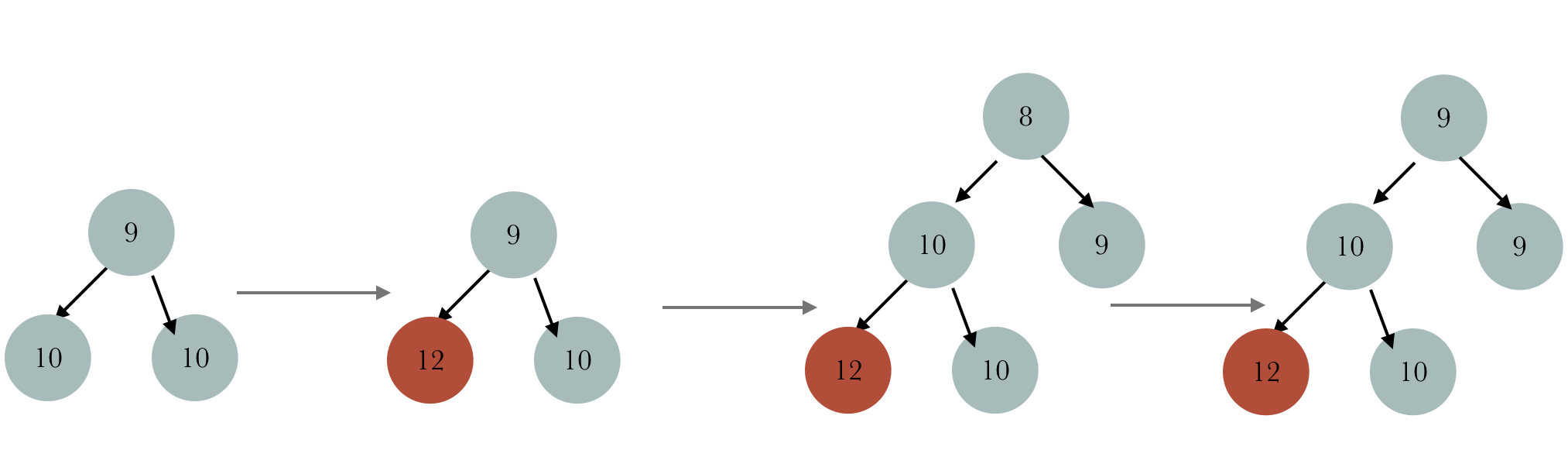
现在父节点的值为10,满足第二个条件
父节点的父节点为9,迭代下去,头节点变成1
那么假设第10层分了1023个,也就是还剩一个,那么头节点还是10,那么上文的
memoryMap[0] > 10还是不成立,说明还是有空间,这是统一的
那么分了1024个,也就是全部分光,那么头节点也就变成12,那么就成立,也就说明没有空间了,也是成立的
所以总结一下整体流程
- 规整化申请的内存大小
- 找到内存大小在二叉树的哪一层
- 从头节点开始找到一个memoryMap[id] == depth_of_memory的节点
- 把节点的值置为已使用
- 同步更新父节点的值为子节点中的最小的那个
size < PageSize
如果申请的内存小于一个Page,那么直接分一个Page有点浪费,但是单个页又标记怎么分又有点麻烦,甚至要消耗更多的空间,不是很值得
Netty的做法是直接从PoolChunk中申请一个Page,然后把Page分为等块的大小的内存,大小由第一次来申请的内存决定,下次再来一样的,就直接再从这个Page中找一块给它
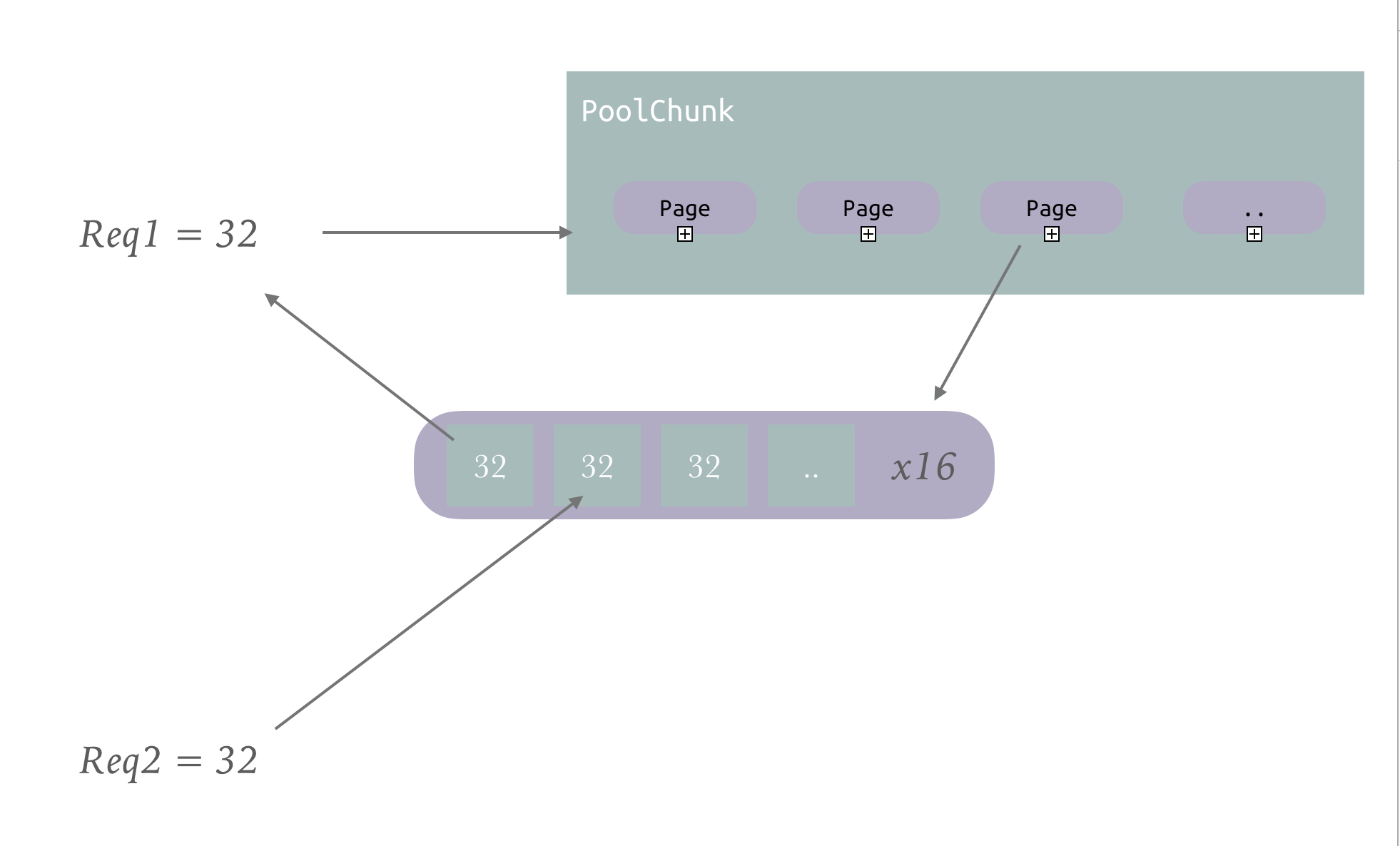
我们前面知道tiny是小于512字节的,那么规整到16的倍数,也就32种选择
small是小于PageSize的,规整到2的次方大小,也就3种选择 1024,2048,4096
随意干脆直接创建两个数组,从PoolChunk中申请来一个Page后,直接放到对应的数组位置中,用的时候直接定位到数组就行了
因为PoolArean管理很多的PoolChunk,所以这个数组创建在PoolArean中好了
1 | # PoolArean |
PoolSubPage
由上文我们知道,对于小于一个Page申请的大小,会从PoolChunk中申请一块内存,然后创建一个PoolSubpage来进行管理
PoolSubpage的具体管理也不复杂
首先,假设我们请求一个1k的内存
PoolArean会先从PoolChunk直接请求一个Page
然后把这一个分为8个1k的内存,并且运用bitmap进行标记
同时维护一个numAvail看还有多少可用
ThreadLocalCache
我们知道一个Alloc可能会整个应用只有一个,多线程应用肯定是加锁的
为了减少竞争,Netty创建了多个PoolArean
同时很多内存资源使用完放回去,如果之后再申请一样大小的,还是要重新走一遍流程
如果我们暂时先不放回去,而是放在ThreadLocal中,等再次请求的时候,直接从ThreadLocal中拿,这样高效还不用加锁,减少了申请的次数
PoolThreadLocalCache就是做这种工作的
这里的运行机制还是蛮绕人的
我们先看PoolThreadLocalCache的声明
1 | final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> |
FastThreadLocal我们可以看做是ThreadLocal的变种,主要是更改了解决冲突的方法,具体可以看看我的另一个文件,这里我们就把当ThreadLocal理解
在Alloc申请内存的时候,会优先调用PoolThreadLocalCache.get方法,得到一个PoolThreadCache
我们来看看ThreadLocal的initValue方法1
2
3
4
5
6
7
8
9
10
11
12
13protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
Thread current = Thread.currentThread();
if (useCacheForAllThreads || current instanceof FastThreadLocalThread) {
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
// No caching so just use 0 as sizes.
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);
}
在初始化变量的时候 之前每一个PoolArean里都有一个变量表示自己当前被多少线程持有1
2// Number of thread caches backed by this arena.
final AtomicInteger numThreadCaches = new AtomicInteger();
leastUsedArena方法就是找到被最少线程持有的PoolArean
所以一个Cache和一个PoolArean是绑定的
在每个PoolThreadCache内部,有六个MemoryRegionCache1
2
3
4
5
6private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;
private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
private final MemoryRegionCache<byte[]>[] normalHeapCaches;
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
每个MemoryRegionCache内部维护了一个Queue
当我们调用ByteBuf的release()方法的时候add方法把那一块ByteBuf的信息放进去
这里还要提一下在PooledByteBufAllocator里面的三个参数
- DEFAULT_TINY_CACHE_SIZE 默认是512
- DEFAULT_SMALL_CACHE_SIZE 默认是256
- DEFAULT_NORMAL_CACHE_SIZE 默认是64
这三个参数很迷,光看名字还以为是内存的大小
其实既然知道MemoryRegionCache内部分了一个queue,那么这里的SIZE就是和queue的大小有关
因为如果Queue满了,那么release会直接放到PoolChunk中,而不会缓存起来
其中TINY和SMALL的策略和上一节中的分配一样,都是直接建了一个32和3的数组
但是这里多了一个对于NORMAL的缓存
而且也是建了一个数组,那么这个数组的大小是什么呢?
这里还牵扯到一个参数
- DEFAULT_MAX_CACHED_BUFFER_CAPACITY 默认是32K
数组大小1
2int max = Math.min(area.chunkSize, maxCachedBufferCapacity);
int arraySize = Math.max(1, log2(max / area.pageSize) + 1);
如果全部按照上面的默认参数来设置 那么arraySize就是3
那么数组的Index是这么算出来的1
int idx = log2(normCapacity >> log2(pageSize))
那么1
2
3[8192, 8192 * 2) => index = 0
[8192 * 2, 8192 * 4) => index = 1
[8192 * 4, 8192 * 8) => index = 2
8192 * 8 刚好是32K,所以Normal的最大到32k,大于这个的内存是不进行缓存的
我们知道,内存进行release的时候,会优先进入cache中,那么如果cache之后再没有分配这块,那就会造成内存泄漏
所以Netty也做了一个对长时间未使用的cache进行释放的机制
主要是维护了一个int allocations
每次进行allocate的时候,进行+1
当分配次数大于一直阈值,默认是8192的时候,就会进行调用MemoryRegionCache的trim方法1
2
3
4
5
6
7
8
9public final void trim() {
int free = size - allocations;
allocations = 0;
// We not even allocated all the number that are
if (free > 0) {
free(free);
}
}
MemoryRegionCache的trim方法就是判断size - allocations,如果大于0,那么就会释放多余的不用的Entry
对象池
Netty的对象池是一个通用的对象池,可以被用在很多的地方
参见我的另外一个文章
申请
看完所有的流程,我们就可以串一遍整体的申请流程了
1 | private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { |
