2020-11-21日更:
x信金科,如果大数据部招人,如果你是业务出生/学历不好/公司背景不强,就不要浪费他们的时间了
前言
Presto的Join操作可以说是极为复杂的几个步骤之一
加上又无其文档和注释,所以想要了解其细节需要自己去耐心的阅读源码
笔者进行了一些研究后,进行了一些自己的理解的整理
总结出来,希望对你有用
Partition和Broadcast
站在整个Presto的体系中,其实数据到底是Partition的分发还是Broadcast的分发在很多环节都有的。
那么对于Join而言,Partition肯定是有的。
想象对于下面一句话1
select * from video v join user u on v.user_id = u.id
那么对于整个分布式环境而言,完全可以把video和user表的数据根据join的key按照Hash的方式partition到不同的节点上去进行运算
这样提高整体的效率是极好的。
那么Join需要Broadcast吗
想象下面一句话1
select * from video v left join user u on v.user_id = u.id
那么对于这么一句话,两个表还可以根据key按照Hash的方法partition到不同的节点上去吗?
肯定是不行的
我们可以对左边的表进行partition到不同的节点上,但是对于右边的表,partition肯定是不行了,只有进行Broadcast才能保证数据Join出来是正确的结果
DistributionType
对应到源码级别的就是在JoinNode中1
2
3
4
5public enum DistributionType
{
PARTITIONED,
REPLICATED
}
这个DistributionType的意思就是针对于右表而言的分发方式,那么是怎么进行判断的呢
在DetermineJoinDistributionType类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private JoinNode.DistributionType getTargetJoinDistributionType(JoinNode node)
{
JoinNode.Type type = node.getType();
if (type == RIGHT || type == FULL || (isDistributedJoinEnabled(session) && !mustBroadcastJoin(node))) {
return JoinNode.DistributionType.PARTITIONED;
}
return JoinNode.DistributionType.REPLICATED;
}
private static boolean mustBroadcastJoin(JoinNode node)
{
return isScalar(node.getRight()) || isCrossJoin(node);
}
private static boolean isCrossJoin(JoinNode node)
{
return node.getType() == INNER && node.getCriteria().isEmpty();
}
整体逻辑其实很挺好懂的
如果是right join或者是full join,那么右表肯定就是partition的了
因为如果是replicated的话,那么肯定就会多出数据来
如果是cross join的话,那么也只能是replicated的方式了。
这个其实也不难理解,想象下面这句sql1
select * from video v join user u on v.user_id > u.id
这种情况和下面这种情况是不同的1
select * from video v join user u on v.user_id = u.id
因为不是等于关系的Join,所以无法根据Hash(user.id) = Hash(u.id)进行partition分发着Join
最多只允许一个表去partition,另外一个表是replicated的。
那左边的表replicated还是右边的replicated,对于最终的结果是没有区别的。
但是在某些情况下并不等同,这个我们留到下面reorder再讲。
Probe和Build
对于Presto而言,其实只有一个Join模式。
那就是
pipeLine0: 读左表 -> LookupJoin
pipeLine1: 读右边 -> HashBuilder
其中是pipeLine1的任务先行,把右表读出来,然后建立一个bucket为N的HashTable。
pipeLine0的任务是先读取左边的数据,然后等待HashTable的建立完成,然后进行Join操作。
其实更细节的话,在pipeLine0的读左表和建立HashTable是两个pipeLine的操作,中间还需要进行数据Hash到Bucket的操作和建立PageIndex的操作。
那么抽象就是左表是Probe表,然后右表是Build表。
永远是右表去Build一个东西,然后左表是Probe数据。
那你发现问题了吗?
如果是这种sql语句呢1
select * from video v right join user u on v.user_id = u.id
对于right join而言,肯定是右表出的是全量的数据,它如果还是build的话,那肯定是不行的。
那么怎么解决呢?
方案:
当然这也不是个致命的问题,可选方案也是有好几个。
1.
Reorder
就是调换两边的Join顺序
把上面的Join变成1
select * from user u left join video v on v.user_id = u.id
这样把左表变成右表,然后把right join变成Left join,可以解决这个问题。
2.
Tracker
当然Presto并没有选择上面这种方法,他在build端增加了一个Tracker。
这个Tracker的作用就是记录没有被Probe到的行,然后LookupJoin结束后,把那些没有Join扫过的一把抓回去。
Merge Join和NestLoopJoin
我们分析下可以发现Presto不管对于什么情况的Join,都是由HashBuilderOperator类去进行Build的。
这很容易让人理解为Presto中只有Hash Join。
但是理论上Hash Join并不是万能的,有些情况是不能解决的。1
select * from video v join user u on v.user_id > u.is
这种情况,肯定是不可能用HashBuilder去完成的,或者更准确点,不能用HashJoin去完成的。
那么肯定是需要NestedLoop Join和Merge Join的存在的。
这个其实蕴含在了Hash Join的具体的实现中了。
只不过是HashBuilderOperator算子的实现是相同的而已。
Join流程
Presto的Join流程还是稍微有点复杂,我花了一天的时间大致梳理一下。
这里涉及到几个比较重要的类HashBuilderOperatorPagesIndexPositionLinks
我们假设有这么两张表进行Join,而且Join的语句是这样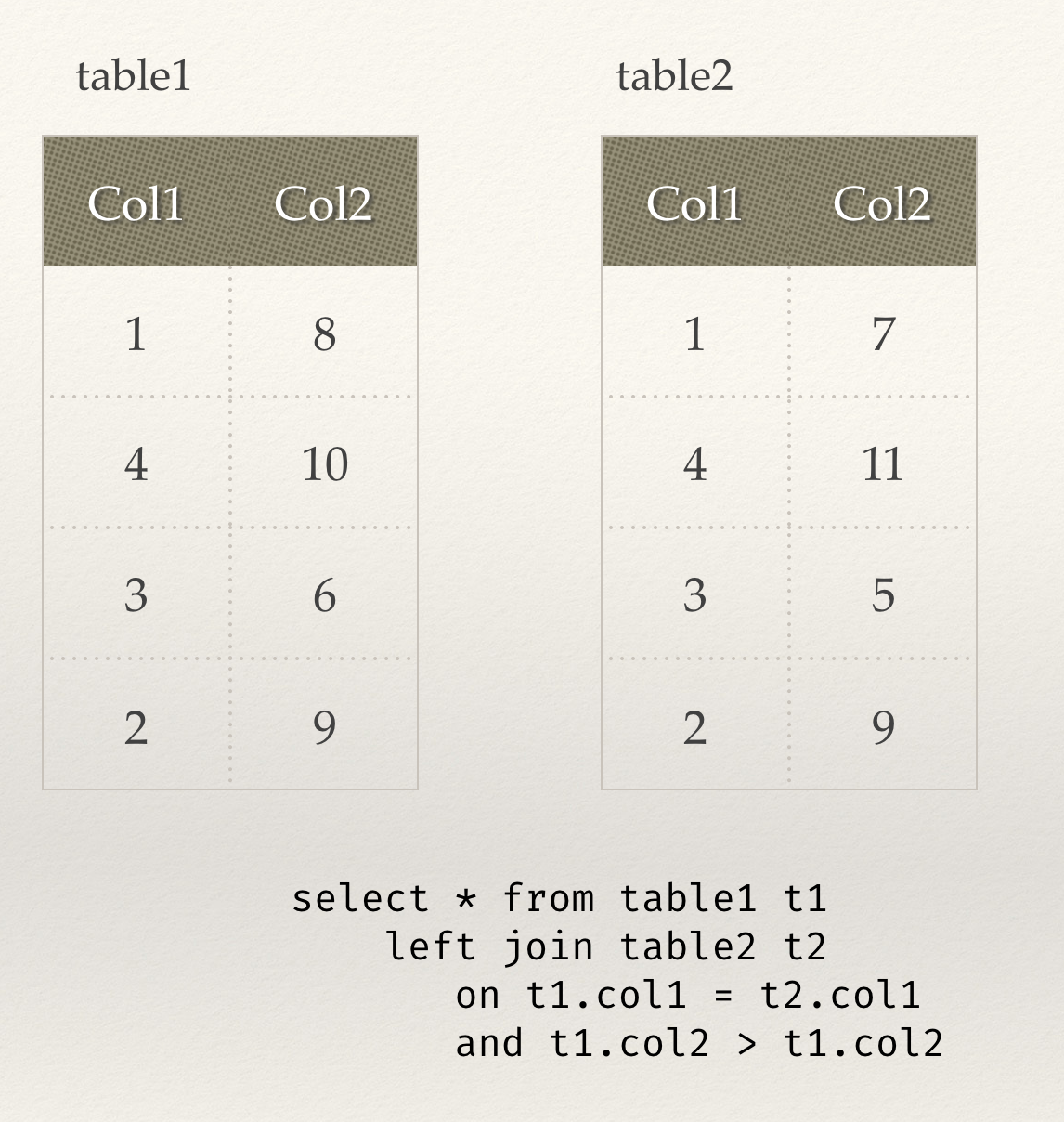
这时候右表的数据以Page为单位进入到HashBuilderOperaor中1
2
3
4
5
6
7
8
9
10
11
12public void addInput(Page page)
{
requireNonNull(page, "page is null");
checkState(!isFinished(), "Operator is already finished");
index.addPage(page);
if (!operatorContext.trySetMemoryReservation(index.getEstimatedSize().toBytes())) {
index.compact();
}
operatorContext.setMemoryReservation(index.getEstimatedSize().toBytes());
operatorContext.recordGeneratedOutput(page.getSizeInBytes(), page.getPositionCount());
}
我们假设右表分为了两个Page进入。
从代码里可以看到的是HashBuilderOperator直接把Page加到了PagesIndex中,从类的名字中我们就可以看出来,这个类是为了建立索引用的。
但是具体是如何建立索引呢。让我们再来看看源码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public void addPage(Page page)
{
// ignore empty pages
if (page.getPositionCount() == 0) {
return;
}
positionCount += page.getPositionCount();
int pageIndex = (channels.length > 0) ? channels[0].size() : 0;
for (int i = 0; i < channels.length; i++) {
Block block = page.getBlock(i);
channels[i].add(block);
pagesMemorySize += block.getRetainedSizeInBytes();
}
for (int position = 0; position < page.getPositionCount(); position++) {
long sliceAddress = encodeSyntheticAddress(pageIndex, position);
valueAddresses.add(sliceAddress);
}
estimatedSize = calculateEstimatedSize();
}
这里比较让人困惑的就是valueAddresses了,这个类是建立Page到channels的索引的类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public final class SyntheticAddress
{
private SyntheticAddress()
{
}
public static long encodeSyntheticAddress(int sliceIndex, int sliceOffset)
{
return (((long) sliceIndex) << 32) | sliceOffset;
}
public static int decodeSliceIndex(long sliceAddress)
{
return ((int) (sliceAddress >> 32));
}
public static int decodePosition(long sliceAddress)
{
// low order bits contain the raw offset, so a simple cast here will suffice
return (int) sliceAddress;
}
}
我们直接看整个类,就是把Page和每一个Page中的Position进行了编码,编成了一个long类型的字段,前32位为Page的Index,后32位为PostionIndex。
那么我们把右表的两个Page加进去的时候,addresses数组和channels就变成了这个样子
HashRow
到上面这一步其实都是为下面做准备的,因为Join而言,如果左表的每个字段都来和右表的每个字段进行比对,那么效率是很低的,这里既然我们准备了t1.col1 = t2.col1,那么不如把col1进行Hash一下好了。
我们创建一个Key的数据,长度就是所有行数。这里就是4个。
然后把col1进行Hash,把addresses的index塞到key数组中,
比如图中,第一行的col1是1,我们进行Hash,等于1,于是把addresses对应的数据index放在Key数组中。
那么下面就是查找了。查找的流程其实和Build的过程类似,先把col1进行Hash,然后去key数组中查找,如果能查到,那么就是拿到了addresses的index,因为addresses中的value是对应的实例的值的pageIndex和PositionIndex的索引,所以再去channels中查找就行。
如下图所示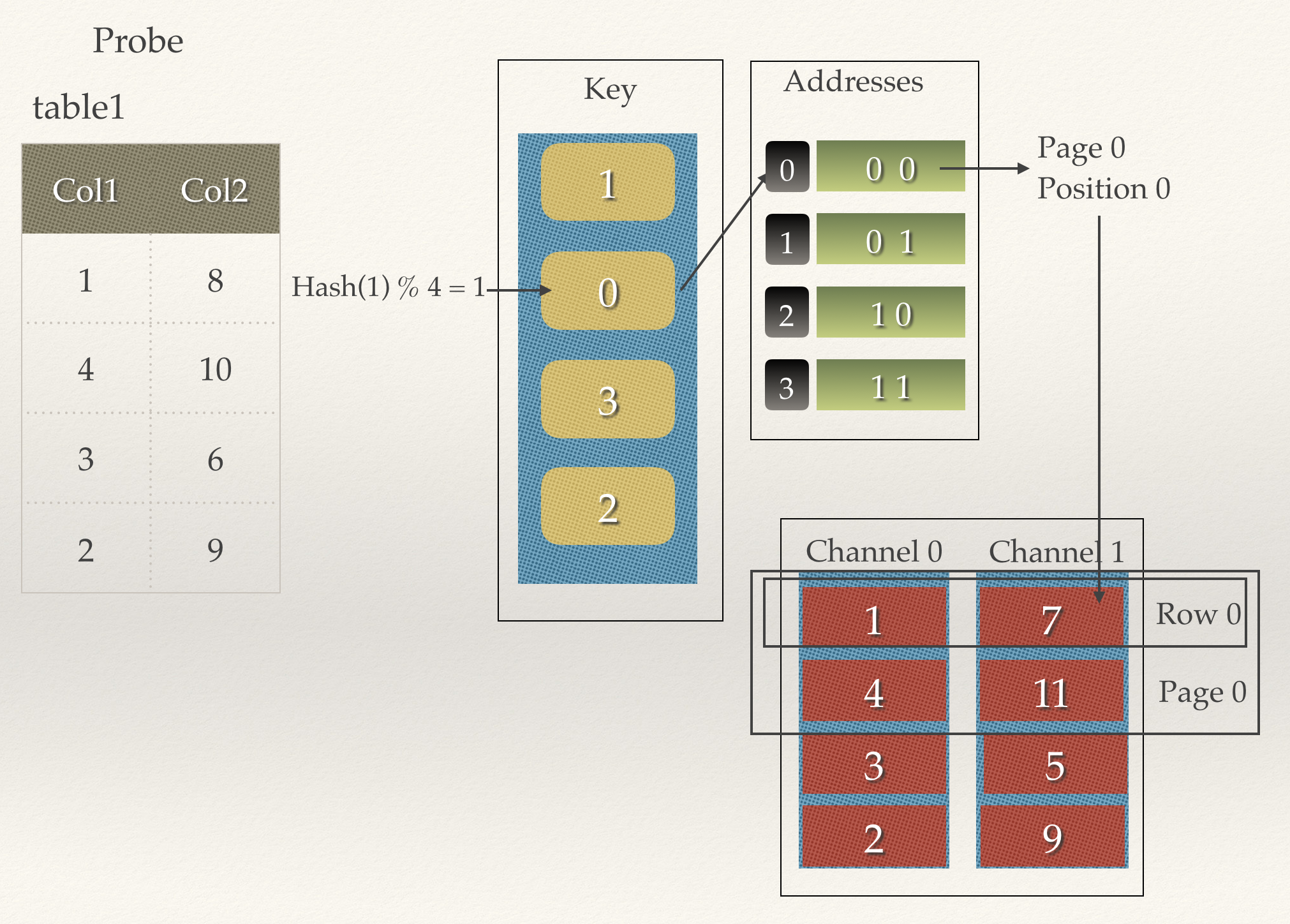
但是这么还是不够,我们如何处理Hash碰撞的情况呢?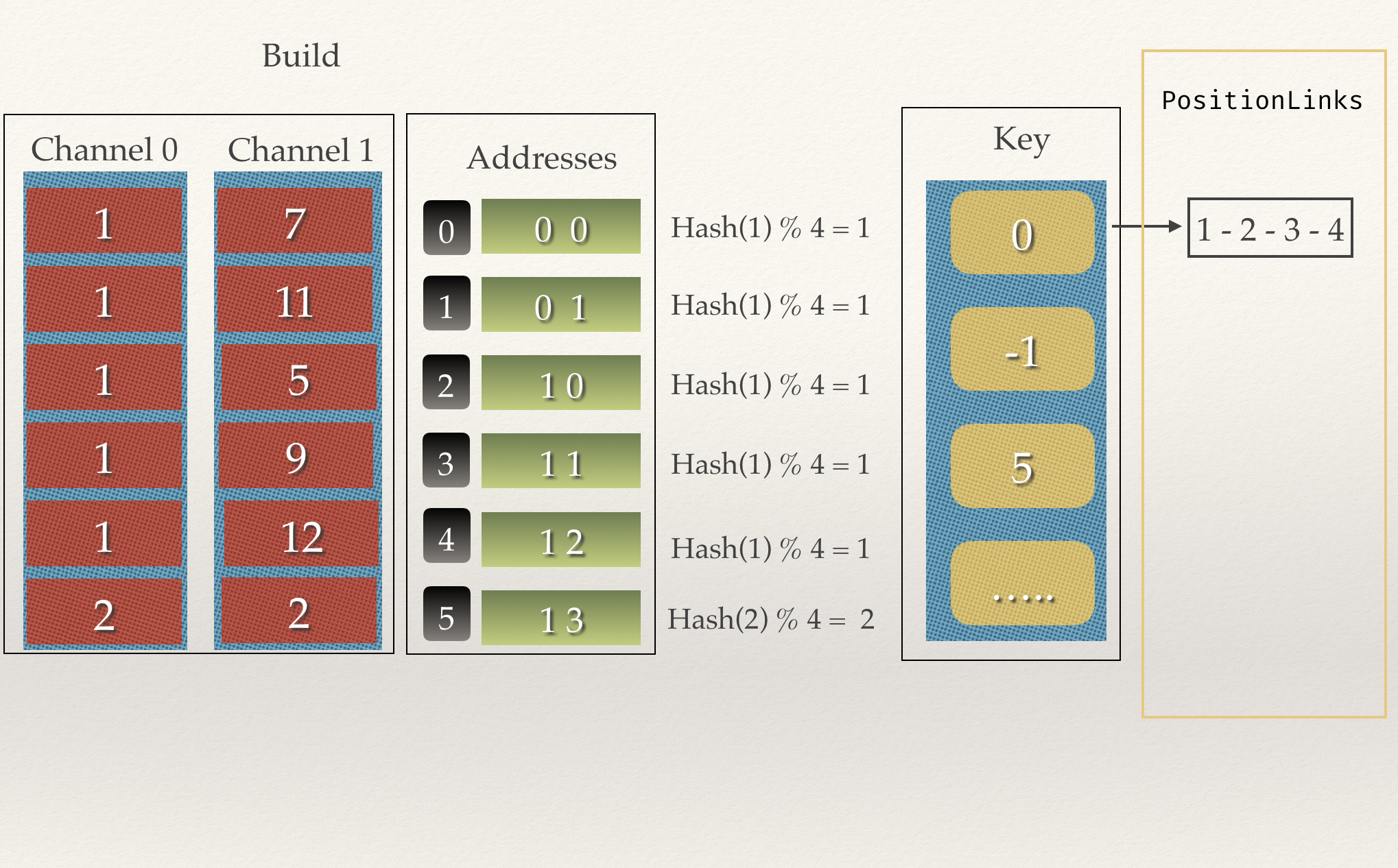
像上面这种情况,col1有多个都是1,那么key只是个一维数组,肯定是不行的。
那么PositionLinks就排上用场了,思路就是为key的每个Index维护一个一维的链表,
在Join的时候,Hash(row)之后去一个一个的找那个链表中的值。
那么,到现在为止已经很完美了,还有优化的空间吗?
答案是有的,看下文。
FastInequalityJoin
我们在扩展一下情况,假设col1相等的情况异常的多。

让我们假设有一千万个,那么单链表就会异常的长,每一行都要去遍历链表吗?
显然我们可以再优化一下。
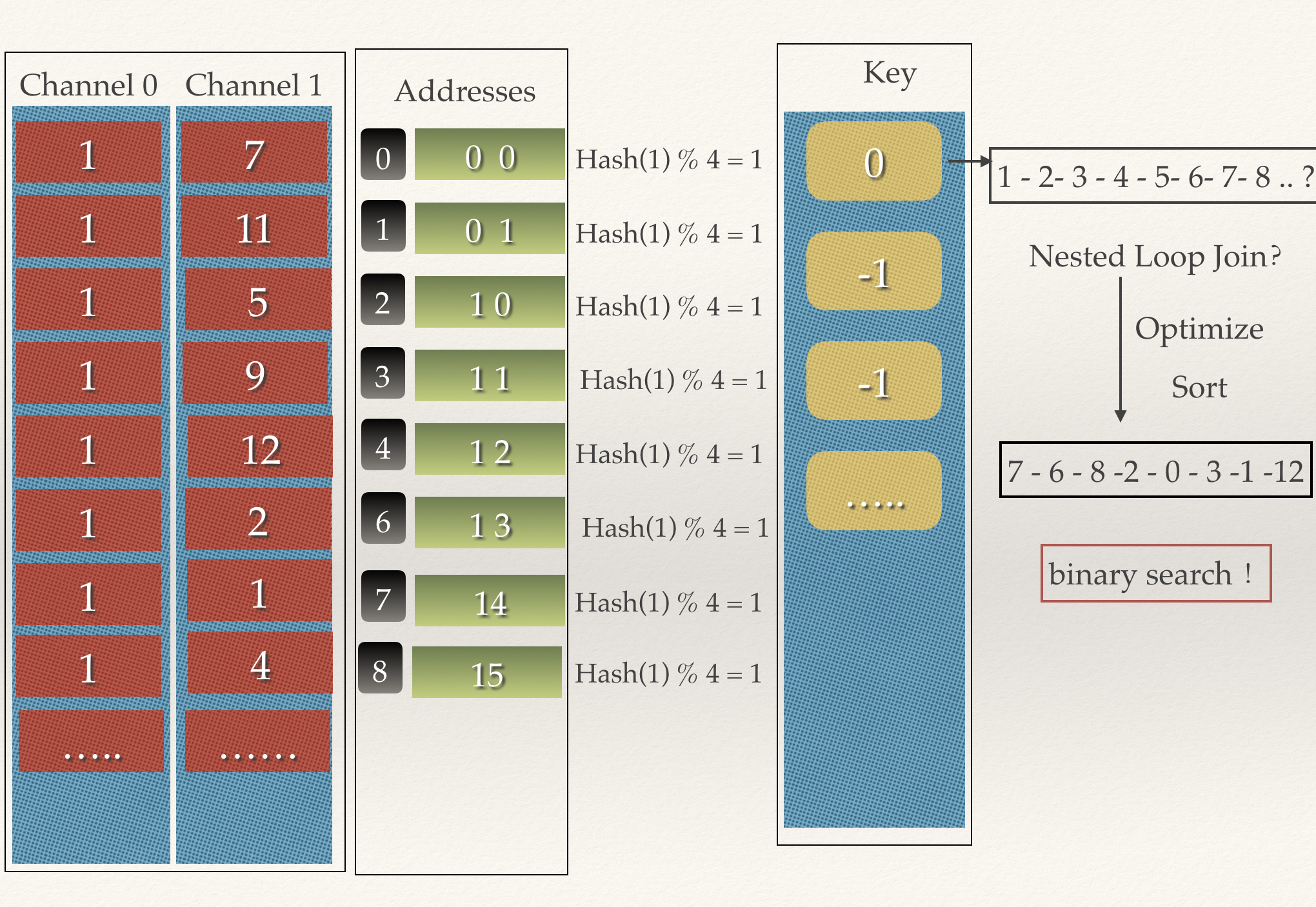
和图中讲的一样,如果我们修改为Sort,那么在进行col2的查找的时候,直接进行二分查找就行了。
这个优化在Presto中是默认开启的,叫做fast_inequality_join1
2
3
4
5
6
7
8
9
10
11
12
13## JoinHashSupplier
PositionLinks.FactoryBuilder positionLinksFactoryBuilder;
if (sortChannel.isPresent() &&
isFastInequalityJoin(session)) {
checkArgument(filterFunctionFactory.isPresent(), "filterFunctionFactory not set while sortChannel set");
positionLinksFactoryBuilder = SortedPositionLinks.builder(
addresses.size(),
pagesHashStrategy,
addresses);
}
else {
positionLinksFactoryBuilder = ArrayPositionLinks.builder(addresses.size());
}
我们可以看到在JoinHashSupplier的源码中,如果开启了fast_inequality_join,那么默认就会创建
SortedPositionLinks,这个和ArrayPositionLinks区别从名字就可以看出是会进行排序的。
