2020-11-21日更:
x信金科,如果大数据部招人,如果你是业务出生/学历不好/公司背景不强,就不要浪费他们的时间了
前言
Presto在数据进行shuffle的时候,并不是PPT中经常看到的Push模式,而是Pull模式。
在两端负责分发和交换数据的类分别是ExchangClient和OutputBuffer。
比如:Source Stage把数据从Connector中拉取出来,这时候需要给下一个FixedStage进行处理。
他会先把数据放在OutputBuffer中,等待上游把数据请求过去,而上游请求数据的类就是ExchangeClient。
ExchangeClient
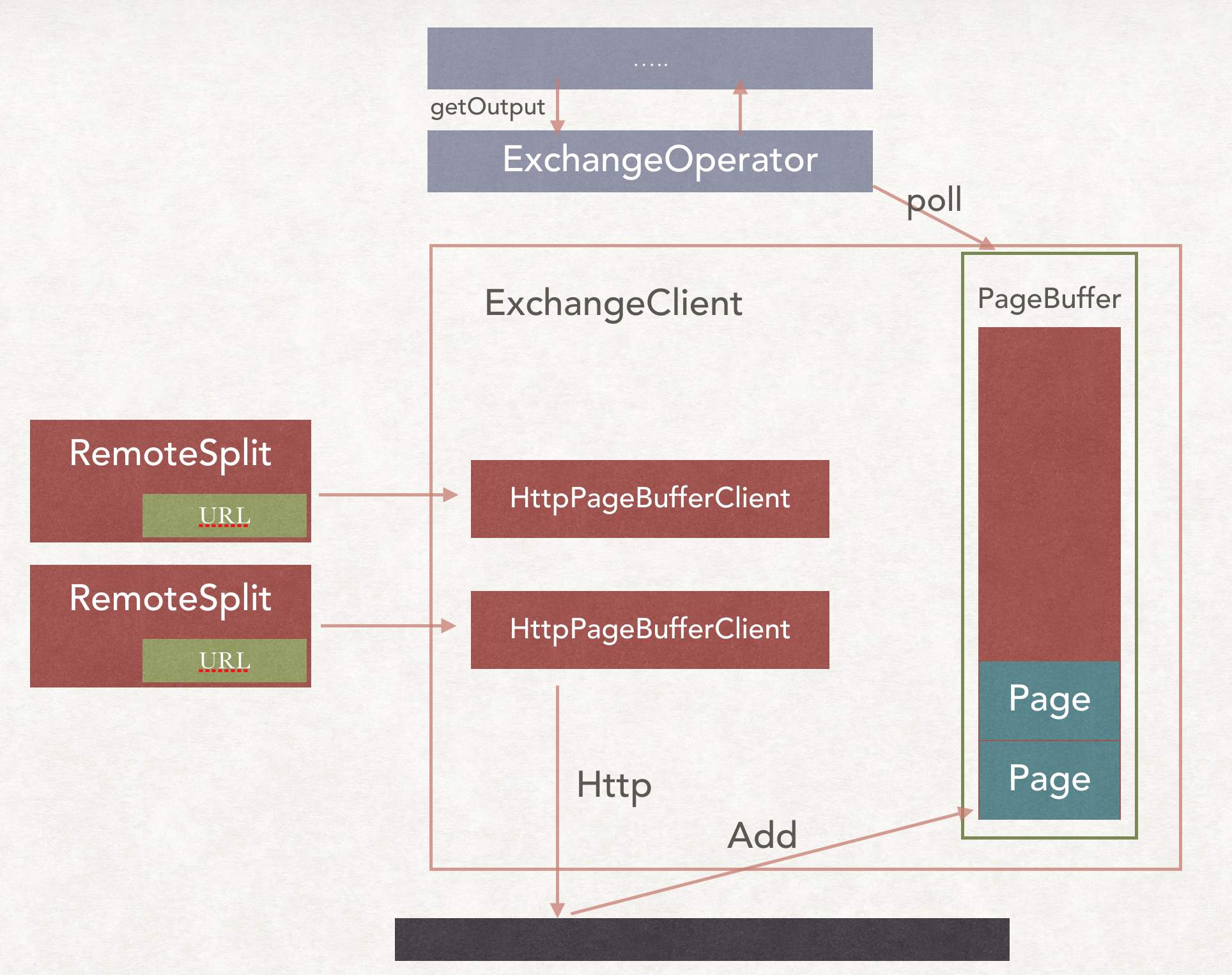
大体的过程是这样,但是一些细节还是没发画出来,尽力了。
下面详细解释下。
ExchangOperator
一般来说负责从下游的Stage拉数据有个专门的Operator是ExchangeOperator。
在创建ExchangeOperator的时候,会加上一个ExchangClient。
所以和图中不同的是,这个ExchangeClient其实是在ExchangeOperator里面。
在PipeLine的下一个Operator和ExchangeClient拉数据的时候,会调用上一个的getOutput(),返回的是一个Page。
在ExchangeOperator的getOutput()方法中1
2
3
4
5
6
7
8
9public Page getOutput()
{
SerializedPage page = exchangeClient.pollPage();
if (page == null) {
return null;
}
operatorContext.recordGeneratedInput(page.getSizeInBytes(), page.getPositionCount());
return serde.deserialize(page);
}
就是调用的exchangeClient的pollPage()方法得到一个Page。
RemoteSplit
RemoteSplit是Source Stage的Task在生成的时候,会添加给FixedStage的。
成员变量特别简单,就是一个标记数据位置的URL。1
2
3
4
5public class RemoteSplit
implements ConnectorSplit
{
private final URI location;
}
HttpPageBufferClient
在进行addSplit到ExchangOperator的时候,会把每个URL封装成一个HttpPageBufferClient,同时传递进去的还有
- httpClient 整个Task共享的一个,用于发送请求的。
- maxResponseSize 一次相应最多的数据量大小,默认是1M
- new ExchangeClientCallback() 当拿到数据后的回调,把Page加到ExchangeClient的队列中
- executor 所有的http请求都是通过这个线程池发送
- minErrorDuration
- maxErrorDuration
上面这两个参数会随之构建一个Backoff的对象。
HttpSchedule
如果我们进入到HttpPageBufferClient的scheduleRequest方法,会发现里面并不是立即发送请求,而是运用了一个schedule方法1
2
3
4
5
6
7
8
9
10
11
12
13public synchronized void scheduleRequest()
{
long delayNanos = backoff.getBackoffDelayNanos();
executor.schedule(() -> {
try {
initiateRequest();
}
catch (Throwable t) {
// should not happen, but be safe and fail the operator
clientCallback.clientFailed(HttpPageBufferClient.this, t);
}
}, delayNanos, NANOSECONDS);
}
这就涉及了请求的失败重试的问题。
简单的说,每一次请求失败,会有一个等待时间,而且随着失败次数的增加,这个等待的时间会越来越长。在这个等待的时间内,不会再去进行请求。
我们看创建backoff的代码。1
2
3
4
5
6
7
8
9this.backoff = new Backoff(
minErrorDuration,
maxErrorDuration,
ticker,
new Duration(0, MILLISECONDS),
new Duration(50, MILLISECONDS),
new Duration(100, MILLISECONDS),
new Duration(200, MILLISECONDS),
new Duration(500, MILLISECONDS));
分别是50MS,100MS,200MS和500MS。
同时有个最小时间和最大时间,防止传递了一个超长的时间,那么就永远挂在这儿了。
这在一定的程度上缓解了请求的压力,同时为节约了下游的cpu资源。因为如果那台服务器挂了,那么一直无意义的http请求是毫无意义的,还会一直浪费cpu资源。
但是这个
流控
如果上游的数据来不及消费会怎么样。
那么,上游来不及消费的信号是什么呢?
整个buffer肯定有个阈值的。1
2
3
4public class ExchangeClientConfig
{
private DataSize maxBufferSize = new DataSize(32, Unit.MEGABYTE);
}
这个阈值就是最大的bufferSize,默认是32M。
在ExchangClient中,有一个long类型的bufferBytes,用来标记当前的buffer中有多少buffer。
在scheduleRequestIfNecessary()方法中,会把bufferBytes和maxBufferSize进行比较,如果已经满足了,那么就不会请求HttpPageBufferClient去请求数据。
同时HttpPageBufferClient不是划了个定时任务去做拉数据的,整个拉取入口函数都是scheduleRequestIfNecessary()中,需要进行手动调用的。
那么是在什么时候会进行手动调用呢,查看了一些,在下面情况下会发生:
- 在新增
URL的时候 - 在所有的
RemoteSplit分配结束的时候 - 在
ExchangeOperator进行pollPage时
其中保证第三个条件是最重要的。
OutputBuffer
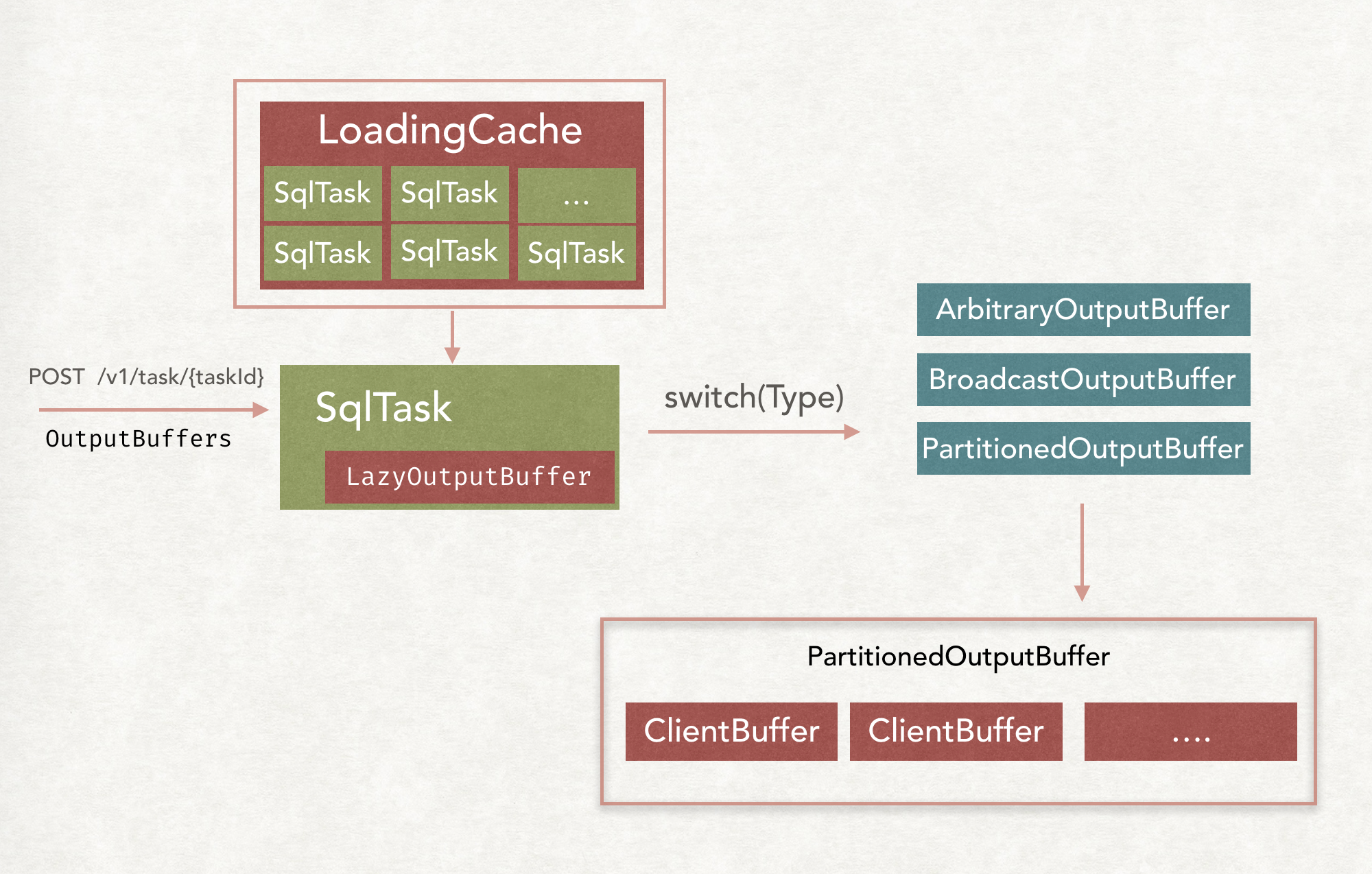
大体的创建流程如上。
TaskResource
一般来说创建Task和更新Task的信息的接口都是/v1/task/{TaskId}。
所以Presto使用了一个Guava Cache来进行SqlTask的cache,当是第一次来的时候,会自动创建一个新的SqlTask,而当是进行update的时候,就从cache中拿出来之前创建的。
LazyOutputBuffer
当一个请求过来的时候,会从Cache中拿出对应的SqlTask,创建LazyOutputBuffer,这个OutputBuffer只是对外的一个封装,里面还包含了一个类别不同的OutputBuffer。
BroadcastOutputBuffer和PartitionedOutputBuffer
具体是哪一种,要根据OutputBuffer的类别来判定。
如果是Broadcast类别的,就会创建BroadcastOutputBuffer,如果是Partition类别的,就会创建PartitionedOutputBuffer。
然后就会根据OutputBuffers的个数具体创建ClientBuffer。
然后在TaskOutputOperator或者是PartitionOutputOperator进行finish的时候,都是把Page放到ClientBuffer中。
如果是BroadcastOutputBuffer类别的,就是把PageReference放到所有的ClientBuffer中,如果是Partition类别的,就是放到指定的ClientBuffer中。
token机制
Presto的数据传输怎么保证可靠性呢?Page什么时候会从下游的OutputBuffer中Remove呢?
这个就需要了解一下Presto拿数据时的Token机制。
我们查看下游去上游的Stage拿数据的接口是1
2@GET
@Path("{taskId}/results/{bufferId}/{token}")
这里的TaskId很好理解,bufferId就是下游的Task的Id,也就是标记下游的哪个Task来拿的数据,那么这个Token是怎么回事呢?
我们想象纯粹的没有token这个参数。
来一次请求,从Buffer中取出一部分数据回送回去,然后把这部分Page进行Remove。
那么问题来了,如果对方接收失败了这部分数据呢?
最终问题就是,你怎么知道对方已经拿到了多少数据?
要是接收失败,你怎么处理这种失败的情况。
解答是Presto模拟了Tcp中的Seq和Ack机制。
但是因为只有上游需要把数据传送给下游,所以是半双工的。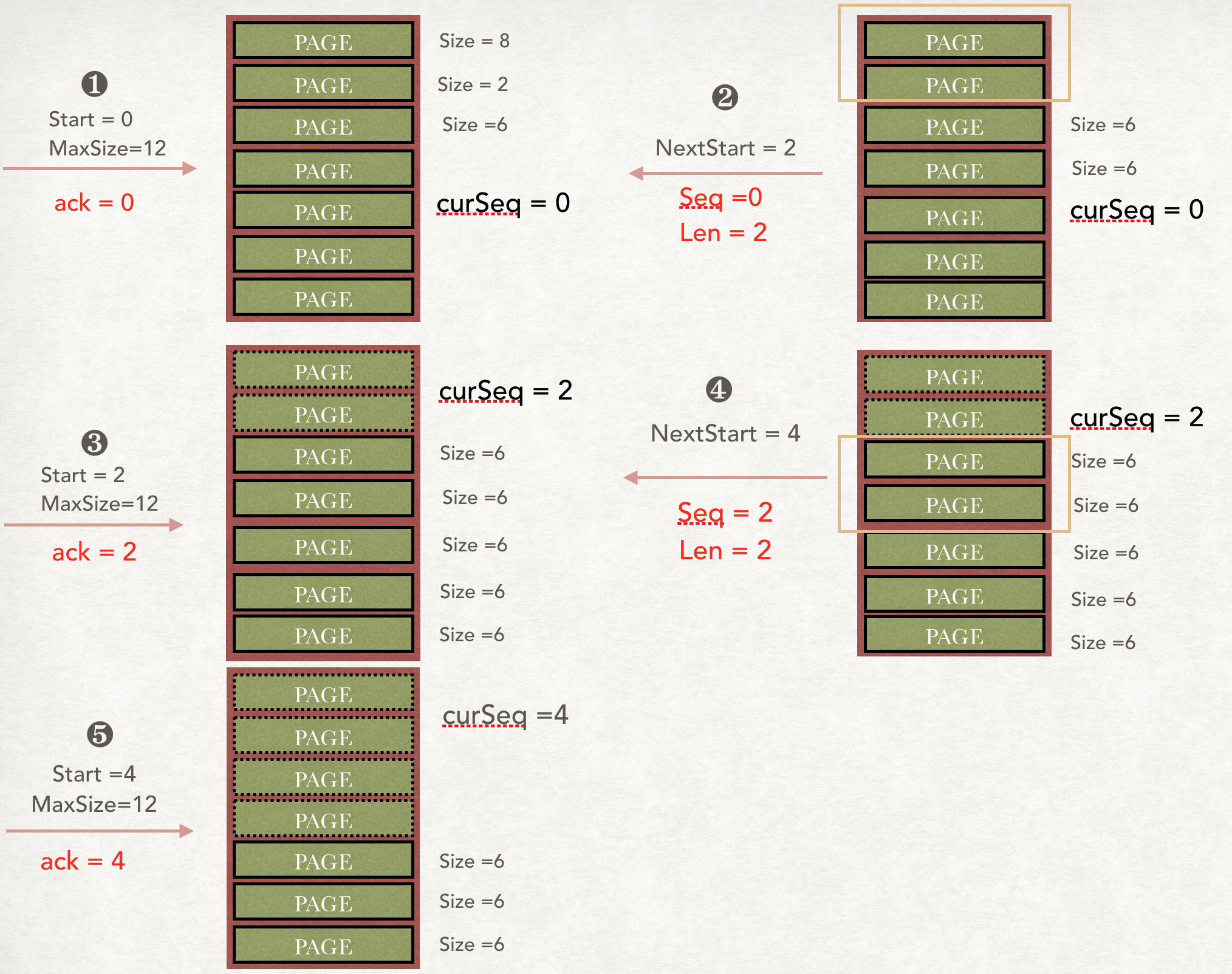
首先下游请求数据的时候,会带上Token,也就是Start,然后还会标记你最多给我多少数据,对应图中的就是MaxSize,其中每个Buffer会有一个叫curSeq的游标。
假设第一次来的时候,上游的队列中有很多Page,前三个大小分别是8,2,6。因为start = 0,也就是从0开始,MaxSize = 12。所以上游会回送前两个Page给下游,同时回送一个NextStart = 2,告诉下游下一次的数据从什么地方开始请求。
第二次请求,start就是上一次上游回送的2,maxSize依然是12。这时候请求发过来时,上游会把前2个Page给Remove掉。然后把下两个Page回送回去,同时标记下一个从4开始。
同样的,当第三次请求过来,start = 4,上游继续把4之前的Page给Remove掉。
那么假设第二次的回复对方没有接收到,那么游标curSeq还是不会变,等下游再次请求的时候,还是从Start=2开始的,就是不会受到影响。
这就是Presto的传输数据的Token机制,类似于Tcp中的Seq和Ack,保证了数据传输的可靠性。
流控
上次提到了ExchangeClient端的流控,当数据来不及消费的时候,那么ExchangClient就不会来请求数据了。
那么这时候OutputBuffer端会出现什么样子的情况呢?
同样的,也是有一个配置标记一个Task的Buffer最大能存多少。1
2
3
4class OutputBufferMemoryManager
{
private final long maxBufferedBytes;
}
这个类,每一个BroadcastOutputBuffer或者PartitionedOutputBuffer都会含有一个,用来监控当前已经的buffer的大小。
如果我们简单的想一想其实监控已经很简单,每来一个Page,把大小加进去,每出一个Page把大小减去,如果当前攒着的大小超过了阈值,那么就返回Blocked,把整个Driver给Block掉,不去执行了。
这种想法其实没错,实现起来也不是很难,足以应付partition的情形,因为每一个Page进来,只会分到指定的一个ClientBuffer中,移除的时候直接减去就行了。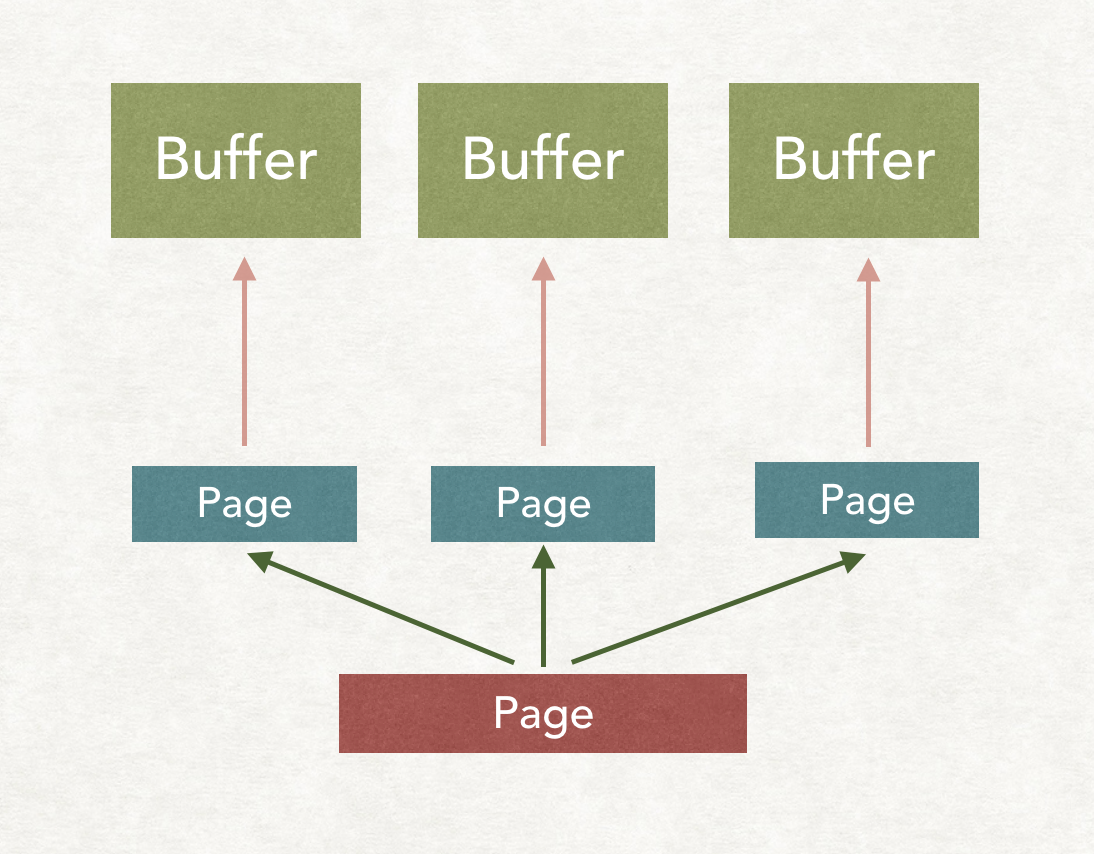
但是如果是broadcast情形呢。
每个ClientBuffer中其实都有一个Page的引用,只有当所有的下游Task把对应的ClientBuffer里面的Page取走了才能把大小给减去,那么你怎么知道已经被所有的Task取走了呢?
如果我们看代码,其实Presto并没有直接把Page放进Buffer中,而是包装了一个PageReference类,传递进去原先的Page和一个回调,这个回调就是把当前的BufferSize减去CurPageSize。
再进去看发现这是个引用计数的实现,每add到Buffer中一次,计数就加一,每从buffer中移除一次,计数就减一,当为0的时候,就调用回调把size减去。
这真的是很精妙了。
