2020-11-21日更:
x信金科,如果大数据部招人,如果你是业务出生/学历不好/公司背景不强(BAT),就不要浪费他们的时间了
先行流程
在进行分段之前,已经建立好计划数PlanNode,并且已经进行了所有的planOptimizers进行优化。
最后在SqlQueryExecution#doAnalyzeQuery()的PlanFragmenter中进行分段。
Stage抽象
Stage:unit of work that does not require shuffling
这个定义是抄的某个PPT上面的,虽然有点抽象,但是也算是个通俗的原则。
PlanFragmenter
在进行分段的流程同样是Visit模式,这里的Visit类是PlanFragmenter的内部类Fragmenter。
每一段之间的分段标记符是RemoteSourceNode
在看Fragmenter源码时,我们会发现每遇到一个Remote的ExchangeNode,都会创建一个RemoteSourceNode。在其他的地方都不会创建。
所以核心在ExchangeNode上。
AddExchanges
既然是Remote的ExchangeNode决定了分段,那么这些ExchangeNode是什么时候添加进去的呢。
经过查找发现是在AddExchanges的Optimizer类中。
他在进行优化的时候,也是运用的Visit模式。
聚合数据节点
首先在OutputNode的时候,如果Child计划不是运行在一个Node上的,就会加上一个Remote的ExchangeNode,同时Type是GATHER,意思就是Child节点的数据远程传输集中到这个OutPutNode上来。
在SortNode上,如果底层的Child计划不是SingleNode运行的,那么就会加上Remote的ExchangeNode,同时Type是GATHER
在TopNNode上,同样的,如果是FINAL级别的TopN(因为TopN是可以先进行Partition的),并且Child不是在一个节点上,那么就会创建一个Remote的ExchangeNode,同时Type是GATHER。
同时在LimitNode节点上也是如此。
总结:
在进行OutputNode,SortNode,TopNNode,或者是LimitNode这种需要聚合所有节点的数据来进行操作的,如果Child的执行计划是在多个节点上运行,那么就会加上RemoteExchangeNode来进行分段。
Join节点
和上面的聚合数据的节点不同,Join节点的处理方式较为复杂。select * from video v join user u on v.user_id = u.user_id
想象这么一句话。
如果不考虑数据分布的情况,正常的处理就是
- 随机选择Fixed阶段处理节点
- 从Source把数据读出
- video的数据按照user_id的Hash进行shuffle到Fixed节点
- user的数据按照user_id的Hash进行shuffle到Fixed节点
但是如果video的原先数据分布就是按照user_id进行分布的呢。
那我们这时候,把user的数据按照user_id分到video的节点上。
是不是更好呢。
那么这样的话,原先是这样的结构。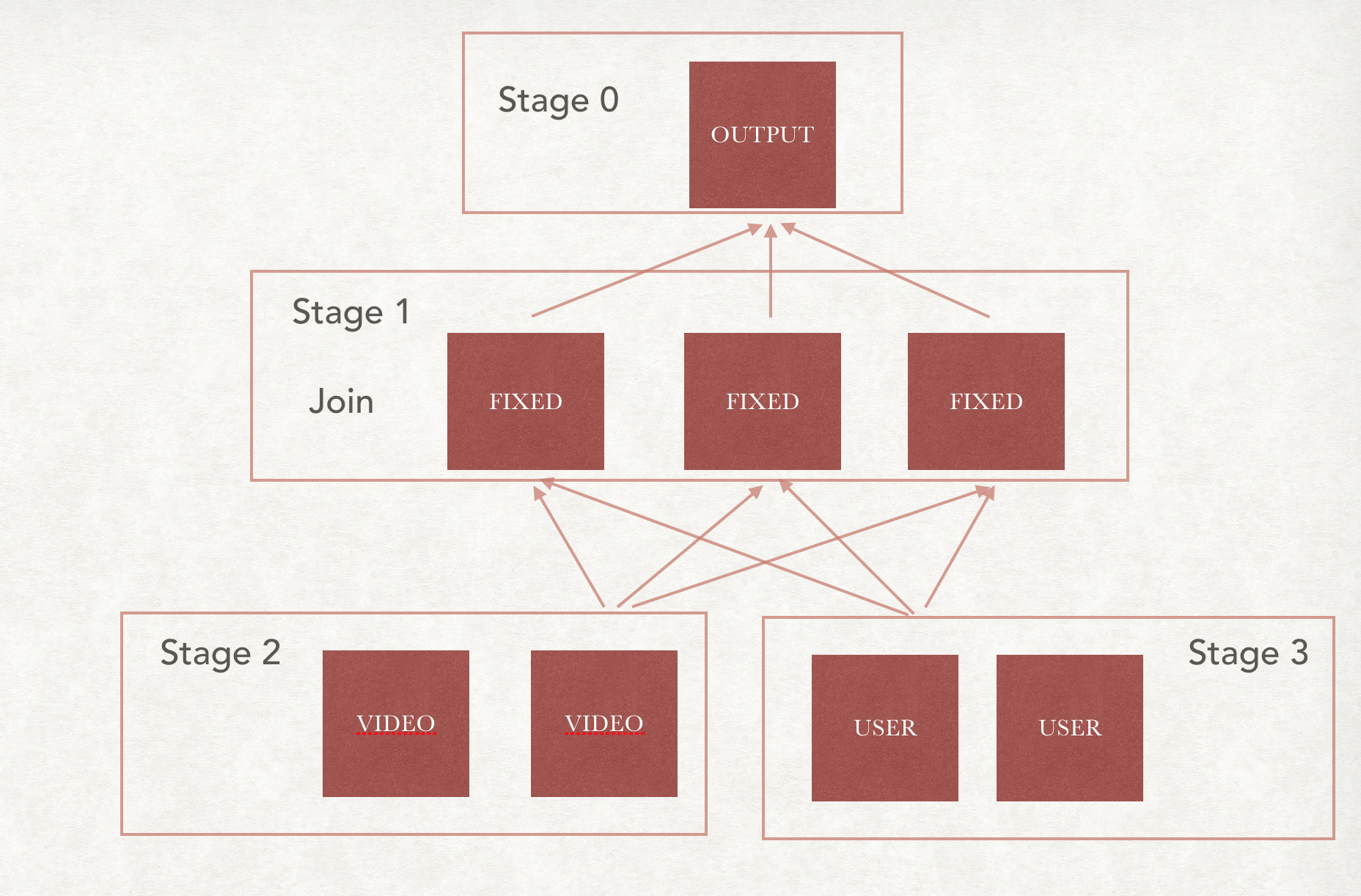
那么就可以变成这样的结构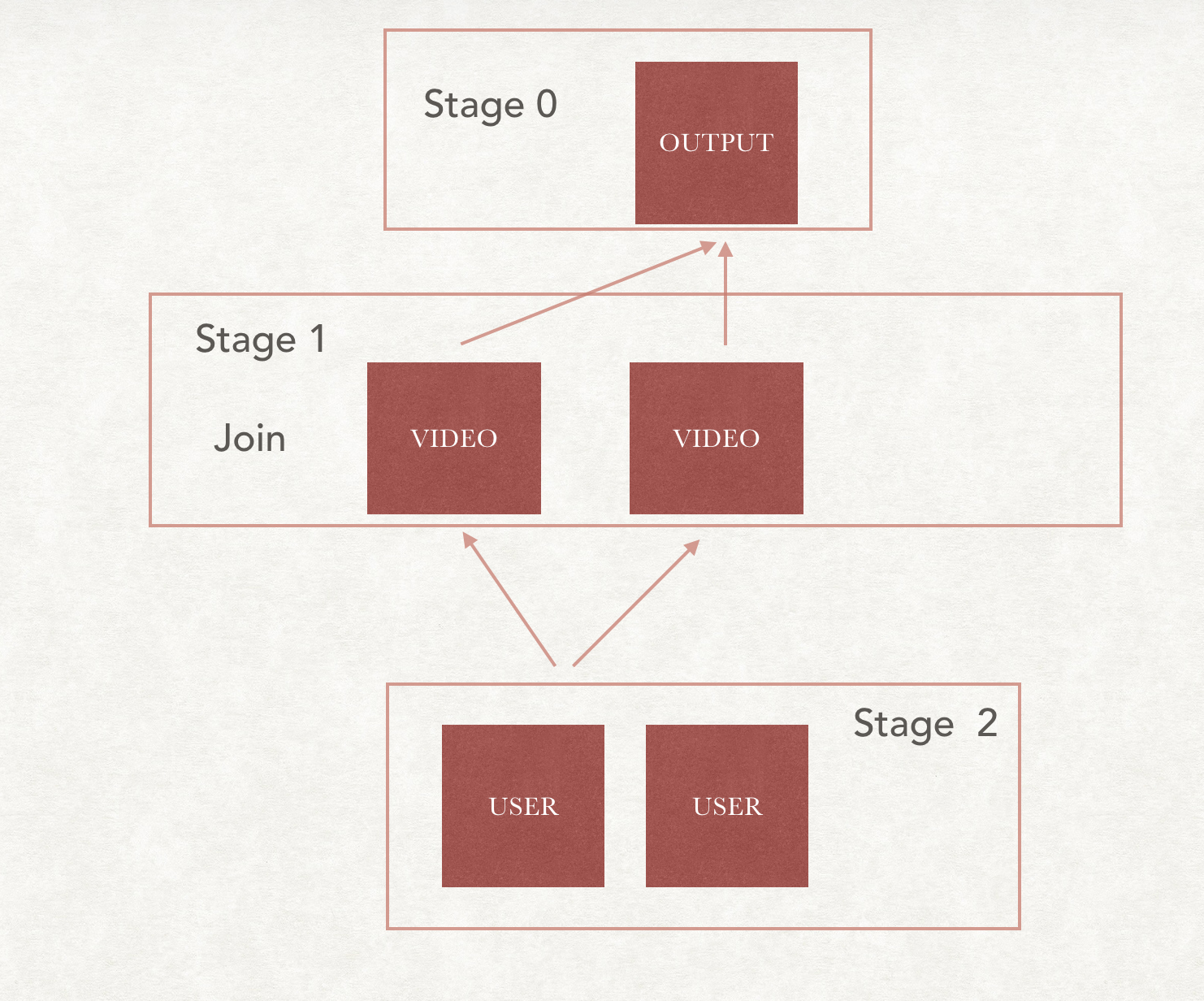
如果左表特别大的话,那么就省去了很多的shuffle时间。
