前言
行列存储的区别,上次在串讲的时候被问到了。
因为没有作为具体的分析,所以今天就来全方面的分析一下。
存储方式
假设我们拥有一张表,有两个字段为name和age
| name | age |
|---|---|
| Zhao | 19 |
| Qian | 20 |
| Sun | 21 |
| Li | 22 |
我们知道磁盘的存储是以页为单位的,每一页的存储地址是连续的
下面看看两种不同的存储方式的区别
行式
那么假设我们以行来存储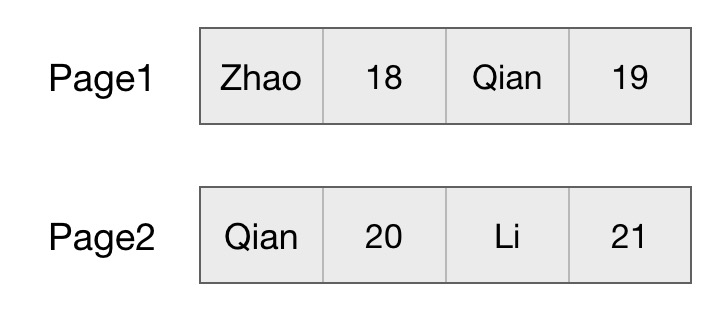
简单的看就是每一行的数据都是存在连续的一块地址中
列式
列式存储根据字段进行切割,把每一个字段的数据存在一起。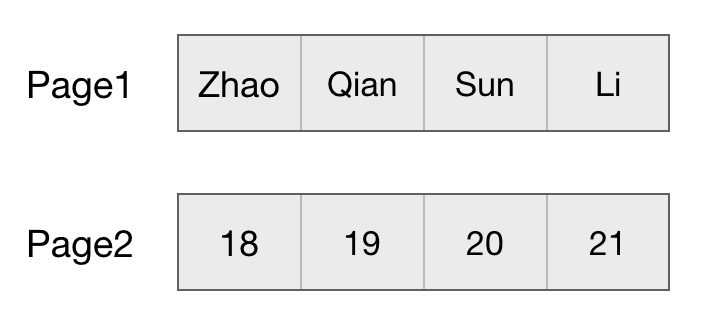
压缩
一般来说数据可以进行压缩,以减少存储的空间。
对于行式来说,很难进行压缩,因为每个表的字段的类型是不统一的,除非预先确认,否则无法动态的进行压缩。
但是列式的就不一样了,每一个字段的类型是确定的,占用大小也是确定的,所以很容易进行压缩。
字典压缩:
假设年龄字段基本就是在18到25之间,那么我们可以建立一个字典,如下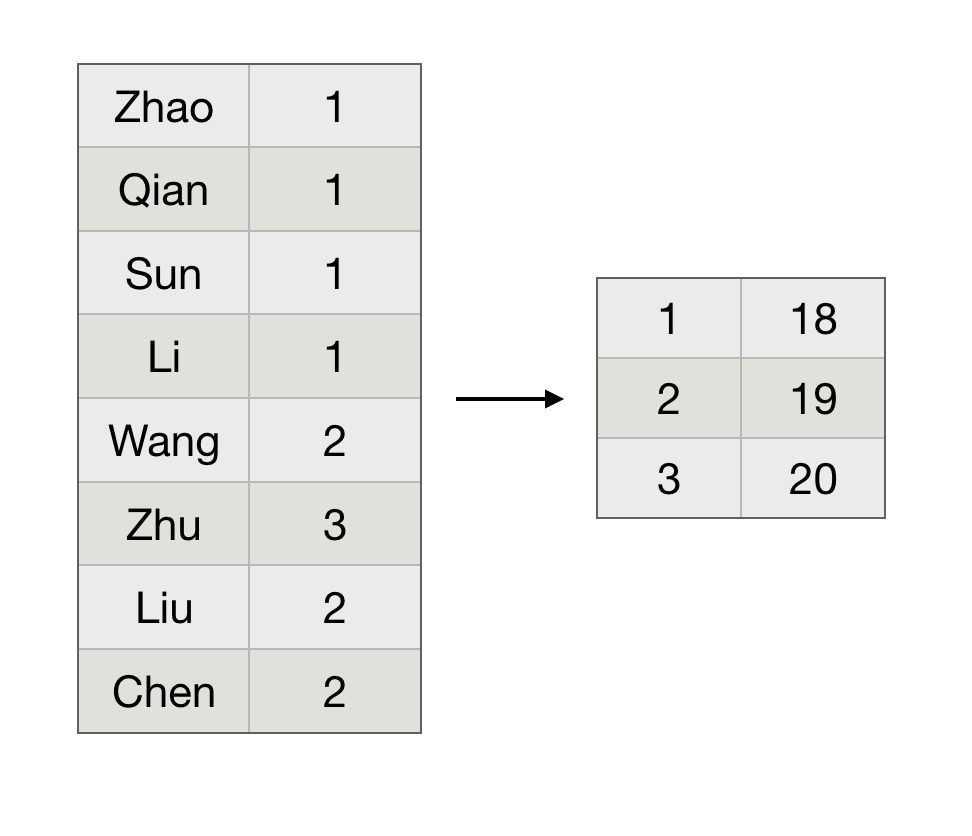
当数据量达到亿级或者千亿级,这样其实是可以省下大量的空间,提高了IO的效率
查询
对于查询而言,针对不同的查询场景,行式和列式的区别较大。
还是以上面的表为例
1.1
select avg(age) from table
对于这句Query,如果是行式,我们需要
- 读取所有的Page
- 在内存中跳着读所有的age字段的数据
- 进行计算
而对于列式而言
- 读取存储age字段的page
- 在内存中连续读取所有的age字段
- 进行计算
显而易见的是肯定是列式的效率更高一点。
同时列式还可以更好的利用Cpu Cache的特性加快读取。
Cpu Cache
对于Cpu的缓存而言,一次的缓存大小是固定的,比如是64KB,叫做一个Cache Line。
那么我们在读age为19的地址的时候,由于那部分凑不齐64KB,那么cpu就是把读取地址附近的数据也读过去以补齐一个Cache Line。
那么可能读18的时候,把后面的19,20,21一起读到Cache中了。
下面在进行读的时候,就不用继续读取内存了,直接在缓存中拿就行了。
2.1
select * from table where age = 18
对于这句Query,假设行式都有索引的情况下
行式
- 读取Page1
- 连续读一块内存
- 进行计算
列式
- 读取Page1和Page2
- 跳着读出所有指定行的字段数据
- 计算输出
显而易见是行式更好一点。
拥有更好的IO效率和更好的运用了Cpu Cache
总结:
对于只需要指定字段的查询,那么行式拥有更好的效率
Insert和Update
对于传统的数据库需求
插入和更新的语句较多的情况
行式
如果是行式的话,更新只需要找到指定的行的地址,进行修改就行了。
对于插入操作,只需要在将上一行的指向下一行的指针修改为插入的那一行的数据就行了。
列式
对于列式而言,如果没有开启压缩,那么对于更新操作而言其实和行式的差不多。
但是如果开启了压缩,那么还需要解压缩->修改->压缩的操作,消耗的时间更久。
同样的,对于插入操作,即使没有开启压缩,那么需要的时间也很久,因为指定行的数据是连续的放在一起,在其中插入一个,必然导致后面的会进行后移。
总结:
对于行式而言,频繁的插入和更新操作损耗较小
对于列式而言,频繁的插入和更新操作损耗较大
使用场景
正常来说
行式存储比较适合OLTP,列式存储比较适合OLTP
因为对于OLTP而言
- 查询需要全字段,只需要指定的几行的语句较多
- 插入,删除,更新操作较多
对于OLAP而言
- 插入,删除,更新操作较少
- 经常只需要相关的列
而这恰恰是运用了行式和列式的优点和缺点。
